




 本文详细介绍Spark 2.3版本的选择、编译、依赖环境及安装过程,包括JDK、Scala的安装,以及Spark在分布式集群和高可用集群的部署方法。特别关注Spark Shell的使用,SparkContext与SparkSession的初始化,和SparkHistoryServer的配置。
本文详细介绍Spark 2.3版本的选择、编译、依赖环境及安装过程,包括JDK、Scala的安装,以及Spark在分布式集群和高可用集群的部署方法。特别关注Spark Shell的使用,SparkContext与SparkSession的初始化,和SparkHistoryServer的配置。
1、Spark 版本选择
三大主要版本:
Spark-0.X
Spark-1.X(主要 Spark-1.3 和 Spark-1.6)
Spark-2.X
官网首页:http://spark.apache.org/downloads.html
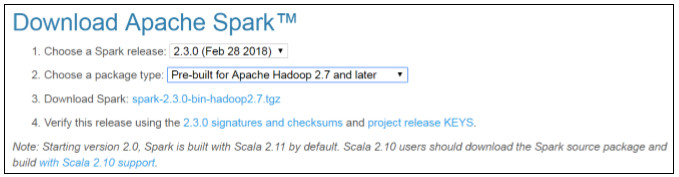
或者其他镜像站:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/
https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/
我们选择的版本:spark-2.3.0-bin-hadoop2.7.tgz
2、Spark 编译
自行利用搜索引擎解决,可做可不做
官网:http://spark.apache.org/docs/latest/building-spark.html
3、Spark 依赖环境
在官网文档中有一句话:
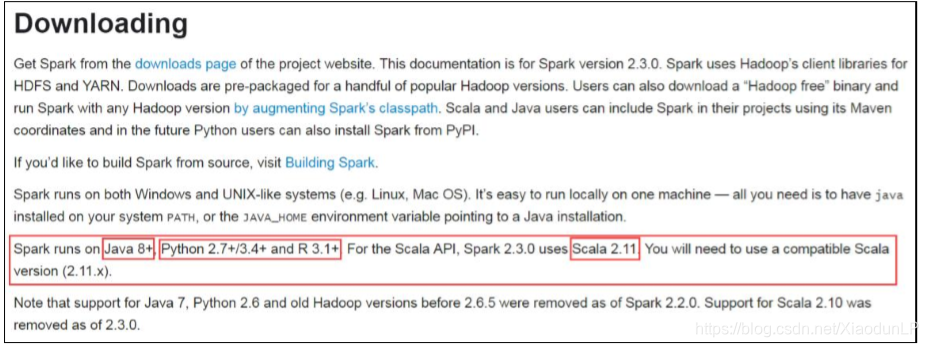
所以总结: Spark-2.3
需要依赖:Java 8+ 和 Python 2.7+/3.4+ 和 Scala 2.11 和 R 3.1+
4、安装 JDK
略 --之前都有
5、安装 Scala
略
6、安装 Spark
6.1、Spark 分布式集群
Spark 也是一个主从架构的分布式计算引擎。
主节点是 Master,从节点是 Worker

详细安装步骤:

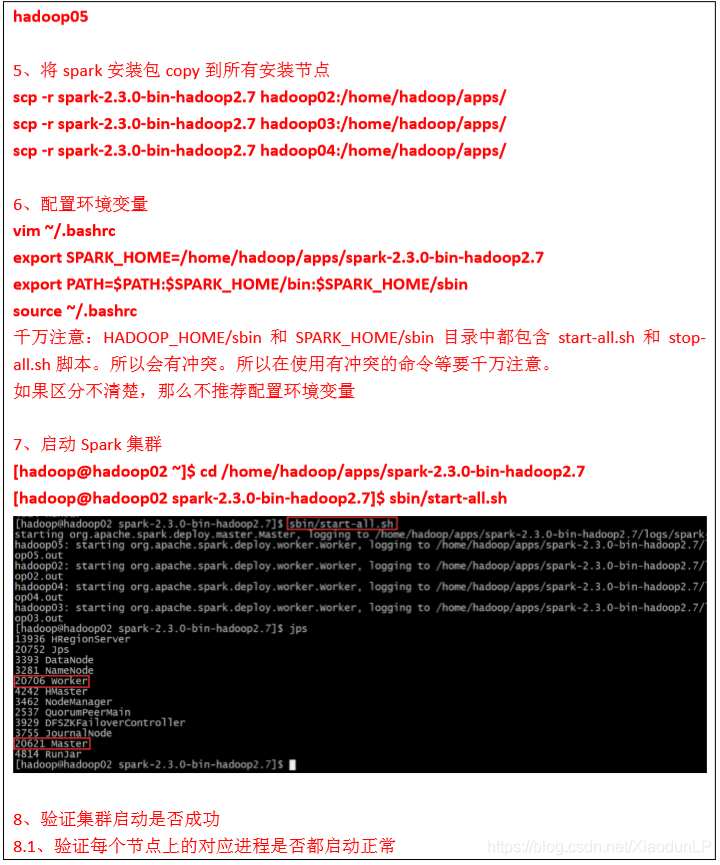
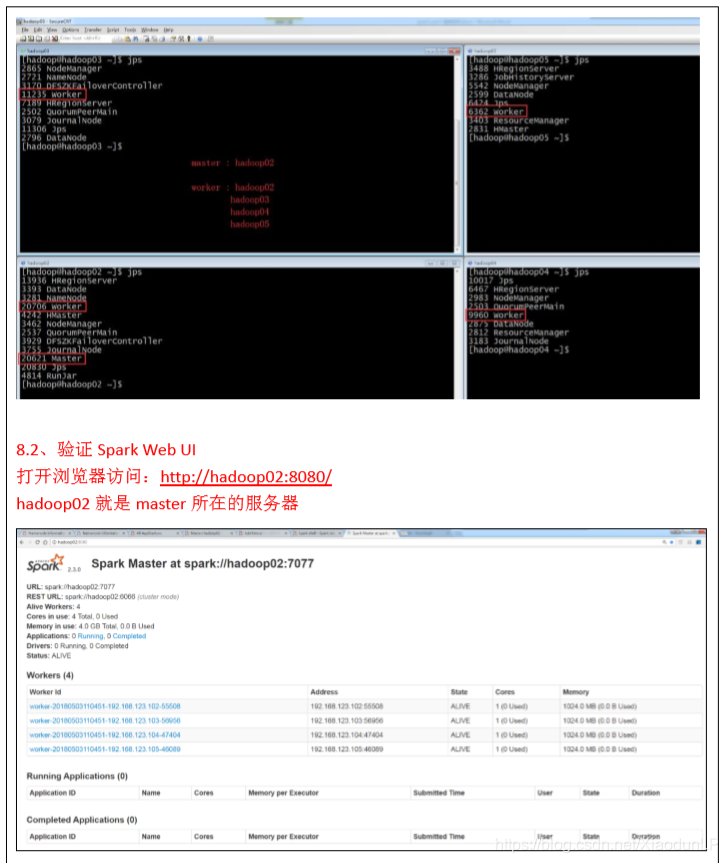
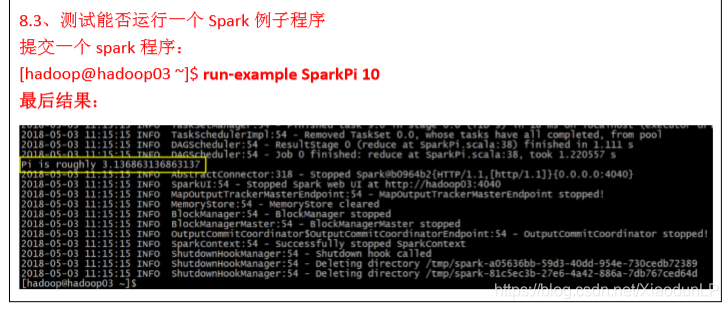
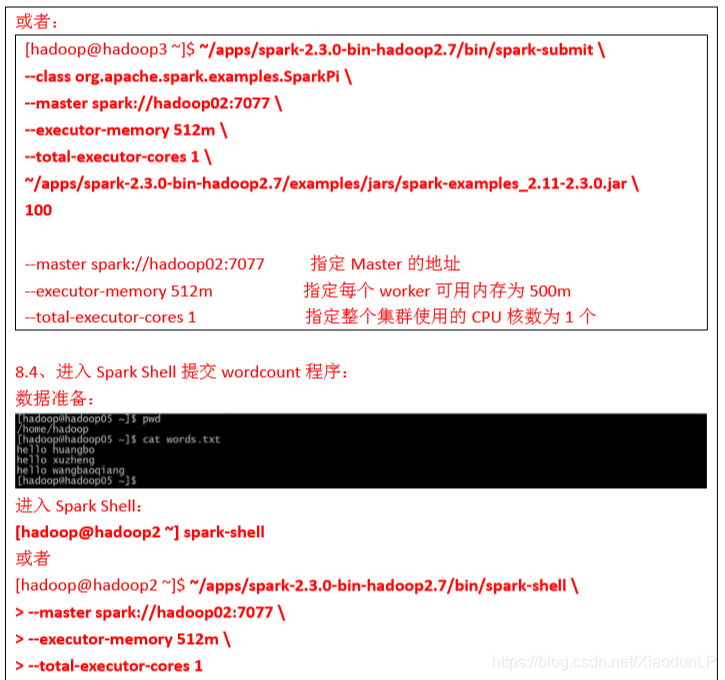
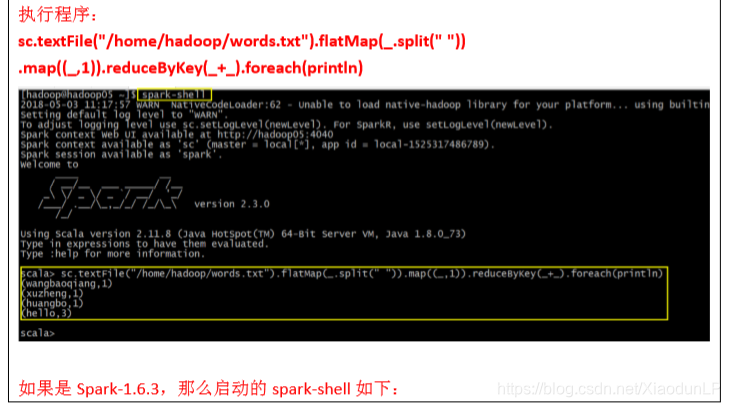
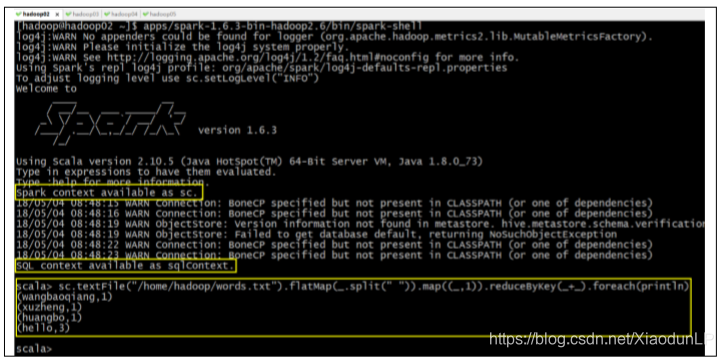
注意:
如果启动 Spark Shell 时没有指定 master 地址,但是也可以正常启动 Spark Shell 和执行 Spark Shell 中的程序,其实是启动了 Spark 的 local 模式,该模式仅在本机启动一个进程,没有与 集群建立联系。
Spark Shell 中已经默认将 SparkContext 类初始化为对象 sc。用户代码如果需要用到,则直接 应用 sc 即可。
Spark Shell 中已经默认将 Spark Session 类初始化为对象 spark。用户代码如果需要用到,则 直接应用 spark 即可。
注意 Spark2 和 Spark1 的区别
6.2、Spark 高可用集群
在上面的 4.6.1 中的安装的 Spark 集群是一个普通的分布式集群,存在 master 节点的单点故 障问题。Hadoop 在 2.X 版本开始,已经利用 ZooKeeper 解决了单点故障问题。同样的策略, Spark 也利用 ZooKeeper 解决 Spark 集群的单点故障问题



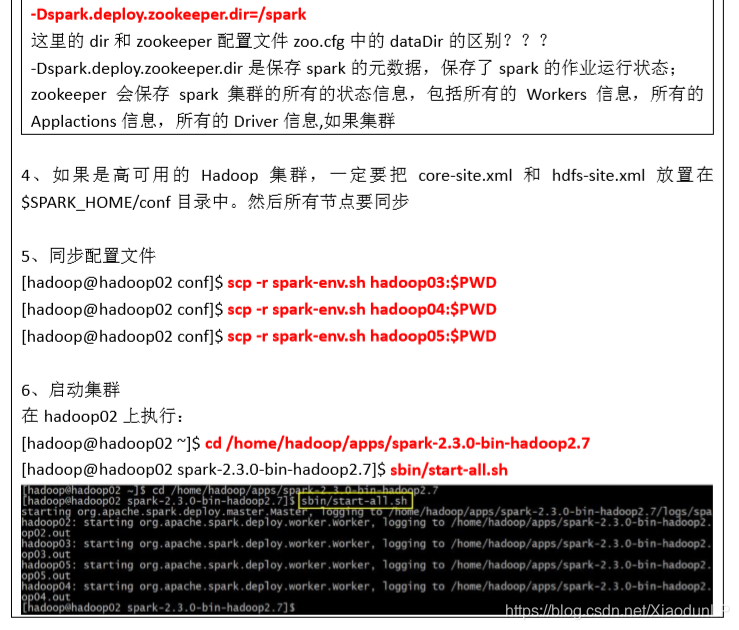
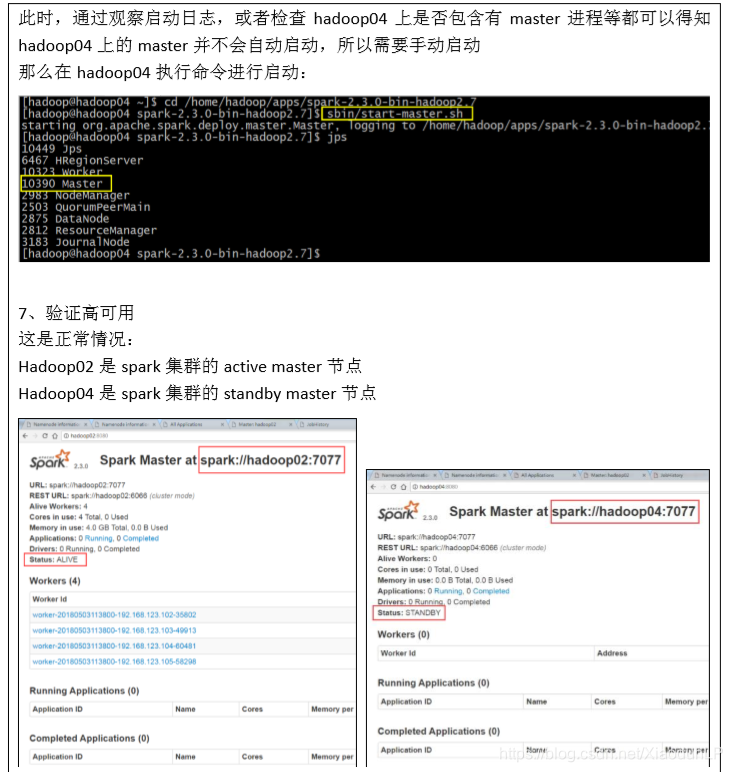
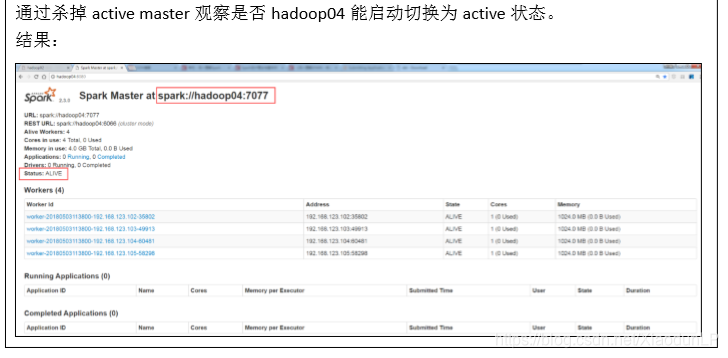
6.3、配置 Spark HistoryServer
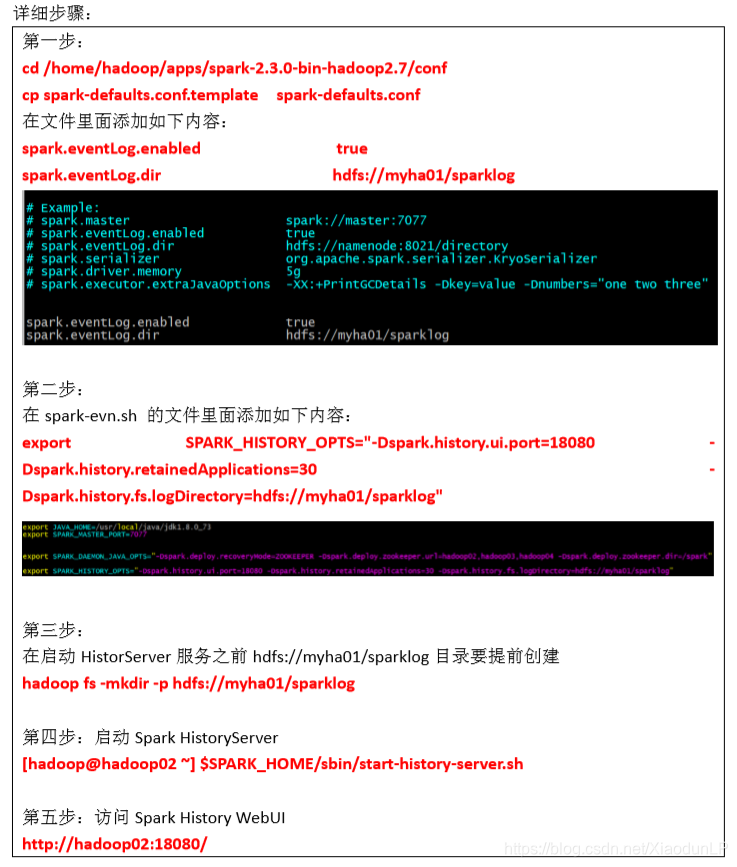

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









