




 本文深入探讨SQL语言中的查询技巧,包括基本查询语句、条件筛选、分组与聚合函数的应用,以及如何使用各种函数优化查询效果。通过实例演示,帮助读者掌握高效的数据检索方法。
本文深入探讨SQL语言中的查询技巧,包括基本查询语句、条件筛选、分组与聚合函数的应用,以及如何使用各种函数优化查询效果。通过实例演示,帮助读者掌握高效的数据检索方法。
在写sql的时候,大多数的时候都不是在做增删改,很大程度上都是在做查询的.
DQL
- 基本语法格式:
- select:查询字段(表达式)
- from:表(视图,结果集)
- where条件
- group by 分组
- having 检索
- order by 排序
- limit 限制结果
- 常见查询
- 下面两张表是做查询操作涉及的表
- 部门信息表(部门编号,部门名称,部门位置)
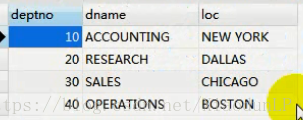 非
非- 员工信息表(员工编号,员工名称,职务,其上级领导的编号,入职信息,工资,奖金,部门编号)
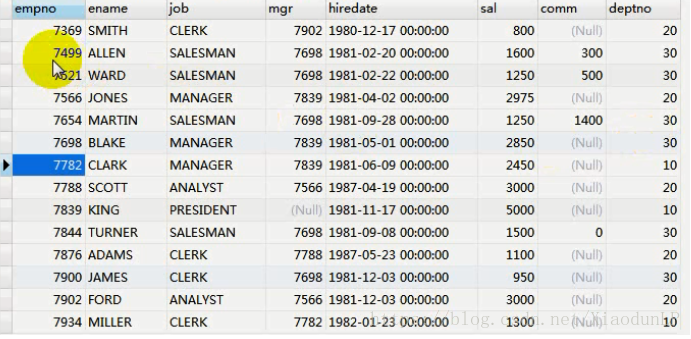
- 下面介绍一些简单的查询
#1.查询emp表中所有的员工信息
select * from emp;
#2.在emp中查询所有员工的姓名和职位信息。(查询指定列的数据)
select ename,job from emp;
#补充:(另外一张额外的user表)
#条件查询(单一):查询年龄>18的用户信息
select * from user where age > 18;
#条件查询(组合),多个条件使用and或or连接 :查询年龄>18的所有女生
select * from user where age>18 and sex='女';
#3.在emp表中查询所有的20号部门的员工信息。
select * from emp where deptno=20;
#4.在emp中查询工资>2000的员工的姓名和工资。
select ename,sal from emp where sal > 2000;
#5.在emp表中查询工资在1000到2000之间的员工信息。(范围查询)
select * from emp where sal >=1000 and sal <=2000;
select * from emp where sal between 1000 and 2000;
#6.在emp表中查询员工编号为7788,7369,7521的员工信息。(集合查询)
select * from emp where empno = 7788 or empno=7521 or empno=7369;
select * from emp where empno in (7788,7521,7369);
#7.在emp表中查询所有的职位信息(去重)
select distinct job from emp;
#8.在emp中查询工资提升5%后的员工姓名及其工资。(别名:字段,表达式,表,结果集等)
# [as] 别名
select ename,sal*1.05 nsal from emp;
select e.ename,e.sal from emp e;
#9.在emp表中查询所有没有奖金的员工信息。(comm值为null)
select * from emp where comm is null; #不为空 is not null
#10.在emp中查询工资最高的员工信息。
#1.倒序排序取第一个
#排序:order by 排序的字段(默认升序,asc升序|desc降序)
select * from emp order by sal desc;
#工资一样按照编号降序排序
select * from emp order by sal desc,empno desc;
#2.限制结果查询(limit 开始索引,长度,仅适用于mysql)
select * from emp limit 0,5; #从索引处开始0
select * from emp order by sal desc limit 1; #如果只是一个数值,默认代表1个记录,不是索引
#11.查询名称中包含s的员工信息。(模糊查询:like %:代表0到多个字符 _代表1位字符)
select * from emp where ename like '%s%'; #名字中带有s
select * from emp where ename like 's%'; #名字以s打头
select * from emp where ename like '%s'; #名字以s结尾
#查询名称第三个字符为L的员工信息
select * from emp where ename like '__L%';
后面再介绍多个表关联的情况下的查询
- 函数
- 单行函数
- 结果返回一条一行一列的记录
- 分类
- 数学函数
-
#1. select PI(); #求圆面积 select CEIL(-12.3); #向上取整,大于这个数的最小的整数 select FLOOR(-12.3); #向下取整,小于这个数的最大整数 select ROUND(12.54,-1); #四舍五入,第二个参数代表从小数点的第几位开始四舍五入,-1代表小数点前一位 select ROUND(12.54); #13 select ROUND(12.54,1); #12.5 select ABS(-10); #取绝对值 select RAND(); #随机数 0-1左闭右开 select POW(2,3); #幂运算 select SQRT(25); #开方 -
字符串函数
-
select LOWER(ename) from emp; #修改为小写 select LOWER('THIS IS'); select UPPER('this is'); #修改为大写 select CONCAT('e-',ename) from emp; #字符串连接 select SUBSTR('abcdef',1,3); #取子串,这里的1 是值得为之,不是索引,3是代表长度 abc select REPLACE('abcdef','cd','aa'); #替换 select TRIM(' a a '); #去掉前后空格 select LENGTH('aa'); #长度 select LPAD('abc',10,'*'); #左填充至第二个参数长度,用* select RPAD('abc',10,'*'); -
日期函数
-
select NOW(); #当前时间,日期时间都有 select SYSDATE(); #当前系统时间,同上 select CURRENT_TIMESTAMP(); #当前时间戳,同上 select CURRENT_TIME(); #当前时间,时分秒 select CURRENT_DATE(); #当前日期:年月日 select YEAR(NOW()); #取得年份 select MONTH(date); #取得月份 select DAY(date); #取得日 #日期计算 select DATE_ADD(NOW(),interval 2 MONTH); #第一个参数日期的后2个月的时间 select LAST_DAY(NOW()); #传入时间的月份的最后一天
- 聚合函数(*)
-
count():统计数目
-
sum():求和
-
max():最大值
-
min():最小值
-
avg():平均值
-
#统计员工数目 select count(*) from emp; select count(1) from emp; #上面两个结果一样,用1代替* 以后可以优化数据量很大事用*效率低的问题 select count(comm) from emp; #count()中传入字段名,统计非空字段数目 #sum() 和 max()等函数的用法和这个类似 #但是:一般聚合函数不单独使用,大部分都是和分组函数配合使用
-
- 分组函数(*)
-
group by 分组条件 having :分组之后实现检索
-
#每个部门的平均工资 select deptno,avg(sal) nsal from emp group by deptno; #注意下面的 select deptno,avg(sal),ename from emp group by deptno; #这个语句是不可取的,因为group by分组后,可能有3个组,但是里面的人可能n个,这里字段ename下的数据是每个组第一个人的名称 #在分组函数里面,select里面有些是不能写的,可以写的是 聚合函数 分组字段 #求平均工资大于2000的部门编号和平均工资 select deptno,avg(sal) nsal from emp group by deptno having nsal > 2000; -
having和where区别
-
顺序不同:having在group by之后,where在group by 之前
having中可以使用聚合函数,但是where中不可以
-
-
-
- 加密函数
-
实现数据加密
-
MD5加密--不可逆的:select MD5('root');
-
select SHA('root');
-
select PASSWORD('root');
-
上面显示的都是字符串,加密函数暂时作为了解.
-
-
- 单行函数
比较重要的都是分组函数,聚合函数,还有select查询语言
下面总结一下完整的sql语句组成部分:
(1)SELECT
(2)DISTINCT <column>
(3)FROM <left_table>
(4)<join_type> JOIN <right_table>
(5)ON <join_condition>
(6)WHERE <where_condition>
(7)GROUP BY <group_by_list>
(8)HAVING <having_condition>
(9)ORDER BY <order_by_condition>
(10)LIMIT <limit_number>
sql语句的正确执行顺序为:
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 DISTINCT <column>
8 SELECT
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
下面具体说明每个阶段的具体过程
1、FORM: 对FROM左边的表和右边的表计算笛卡尔积,产生虚表VT1。
2、ON: 对虚表VT1进行ON过滤,只有那些符合的行才会被记录在虚表VT2中。
3、JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3。
4、WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中。
5、GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5。
6、HAVING: 对虚拟表VT5应用having过滤,只有符合的记录才会被 插入到虚拟表VT6中。
7、SELECT: 执行select操作,选择指定的列,插入到虚拟表VT7中。
8、DISTINCT: 对VT7中的记录进行去重。产生虚拟表VT8。
9、ORDER BY: 将虚拟表VT8中的记录按照进行排序操作,产生虚拟表VT9。
10、LIMIT:取出指定行的记录,产生虚拟表VT10, 并将结果返回。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









