




 本文是关于深度神经网络在机器翻译中的论文学习笔记,介绍了seq2seq模型在机器翻译中的应用,以及FNN、RNN、RAE、RecursiveNN和CNN等神经网络在自然语言处理中的角色。重点探讨了这些模型如何处理序列数据,以及它们在统计机器翻译和神经机器翻译中的应用。
本文是关于深度神经网络在机器翻译中的论文学习笔记,介绍了seq2seq模型在机器翻译中的应用,以及FNN、RNN、RAE、RecursiveNN和CNN等神经网络在自然语言处理中的角色。重点探讨了这些模型如何处理序列数据,以及它们在统计机器翻译和神经机器翻译中的应用。
论文学习笔记
Deep Neural Networks in Machine Translation: An Overview
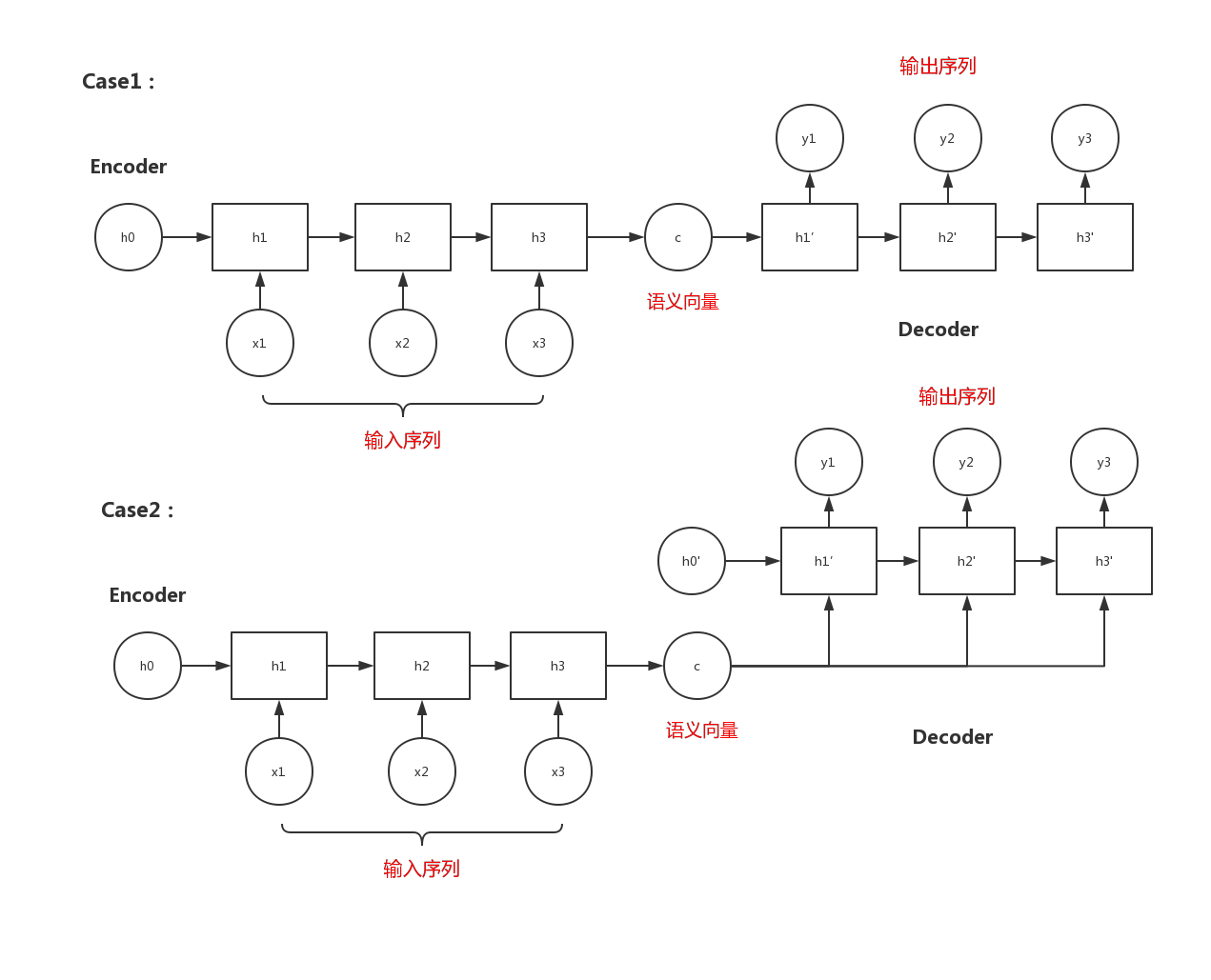
1.拓展:seq2seq模型(encoder-decoder结构的一种)
- 输入和输出不等长
- 从一个序列到另一个序列的转换
- 常用于机器翻译、聊天对话场景
- 两个RNN:一个做Encoder,一个做Decoder
Encoder:将输入序列压缩成一个语义向量c
Decoder:根据语义向量c生成一个指定的序列
两种模式:
(1)将语义向量c作为decoder的初始状态
(2)将语义向量c当做decoder每一步的输入
2.几种常用的神经网络
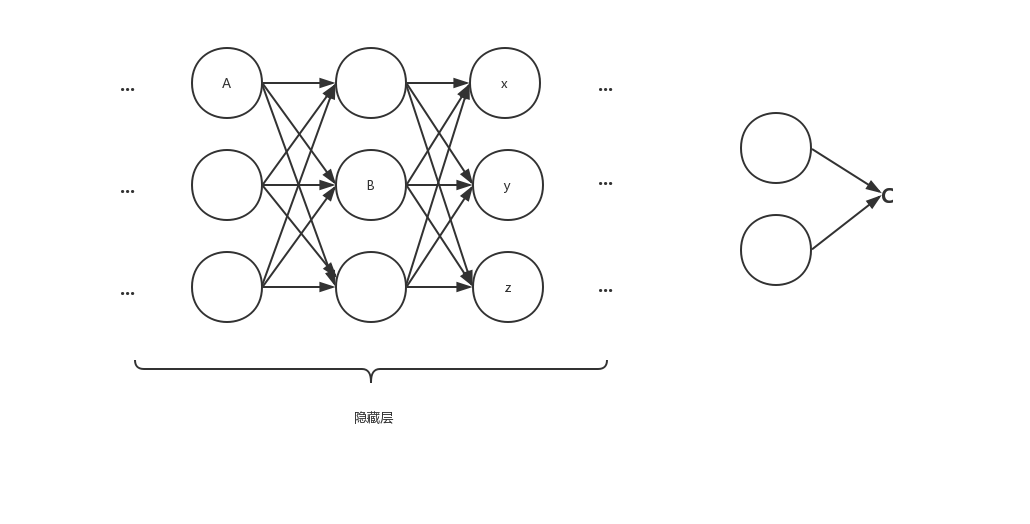
(1)FNN(Feed-Forward Neural Network/前馈神经网络)
- 拓展:
简介:各神经元从输入层开始,接收前一级输入,并输入到下一级,直至输出层。整个网络中无反馈。
-
模型参数(隐藏层边的权值)的计算:
要减小Loss C => 求梯度 =>链式求导法则(计算量大(许多都是重复计算),需优化!)
优化算法:BP算法(反向传播算法)
一个多输出的网络,损失函数:
E(w)=12∑d∈D∑k∈outputs(tkd−okd)2 E(w)=\frac{1}{2}\sum_{d∈D}\sum_{k∈outputs}(t_{kd}-o_{kd})^2E(w)=21d∈D∑k∈outputs∑(tkd−okd)2
D:样本空间
tkdt_{kd}tkd:第d个样本的第k个实际输出
okdo_{kd}okd:第d个样本的第k个预期输出
- FNN语言模型:
尝试在给定固定窗口历史单词的情况下,预测下一个单词的条件概率。
(为什么预测概率?)
(拓展:统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = ⟨w1, · · · , wT ⟩ ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。一个句子的概率越高,说明它越像人说出来的句子)
T-word sentence:w1,w2,...,wt,...,wTw_1,w_2,...,w_t,...,w_Tw1,w2,...,wt,...,wT
任务:已知历史单词:wt−3,wt−2,wt−1w_{t-3},w_{t-2},w_{t-1}w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









