






 该博客围绕Linux运维展开,介绍了文本处理工具、文件查找工具、文本处理三剑客及格式化命令;总结了grep命令的基本和扩展正则表达式;阐述变量命名规则与不同类型变量使用;还包含shell编程实例、磁盘术语、MBR和GPT结构,以及分区、文件系统和SWAP管理命令。
该博客围绕Linux运维展开,介绍了文本处理工具、文件查找工具、文本处理三剑客及格式化命令;总结了grep命令的基本和扩展正则表达式;阐述变量命名规则与不同类型变量使用;还包含shell编程实例、磁盘术语、MBR和GPT结构,以及分区、文件系统和SWAP管理命令。
1、文本工具
1.1、文本处理工具
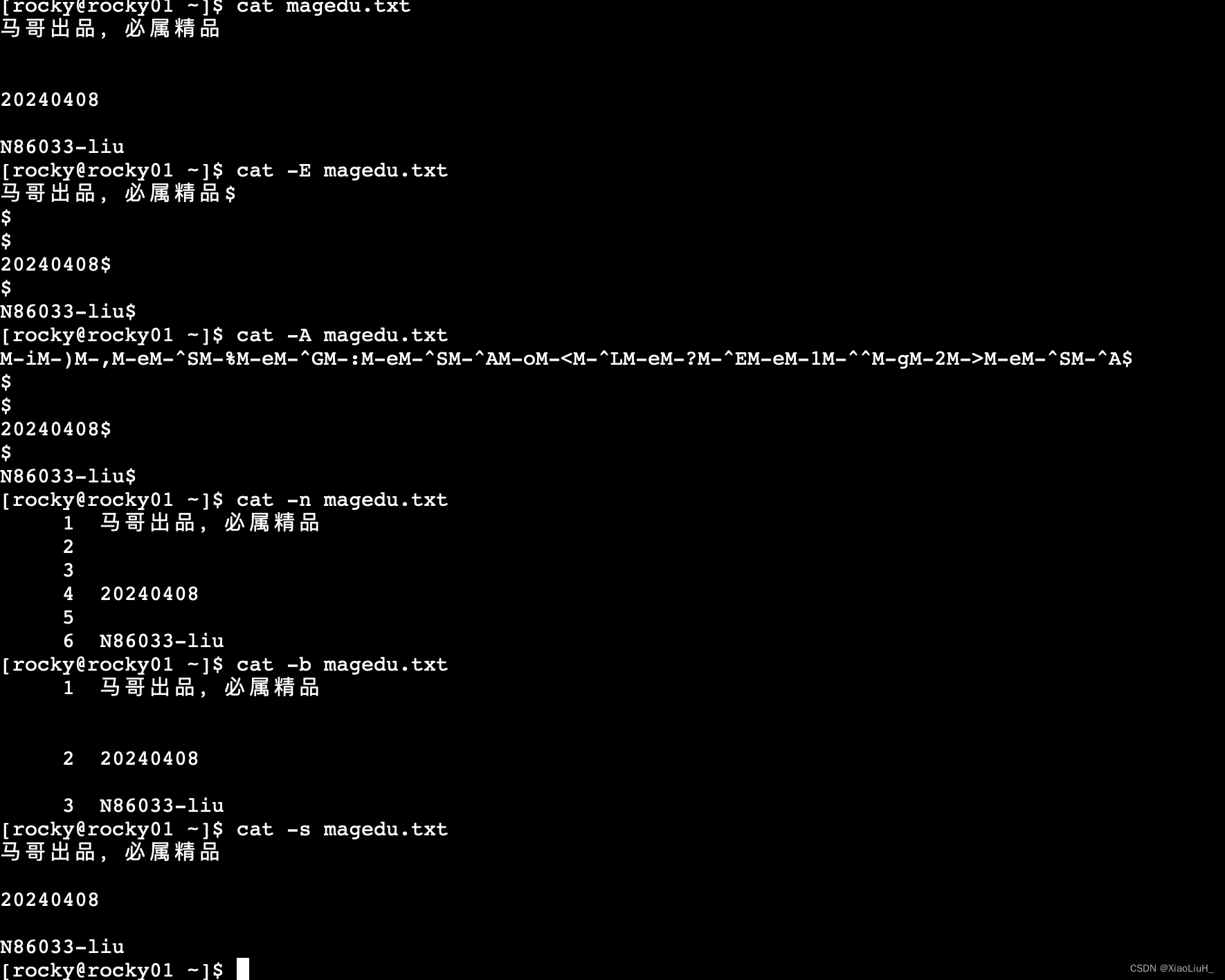
cat 可以查看文本内容
常见选项
-E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
nl
显示行号,相当于cat -b

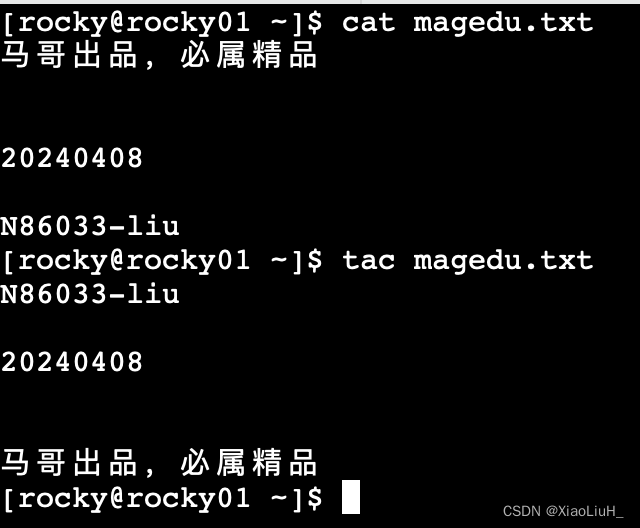
tac
逆向显示文本内容
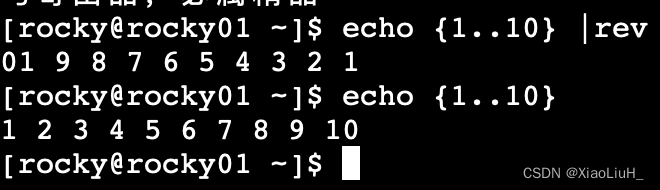
rev
将同一行的内容逆向显示
查看非文本文件内容
范例:hexdump
分页查看文件内容
more 可以实现分页查看文件,可以配合管道实现输出信息的分页
格式
more [OPTIONS...] FILE...
选项:
-d: 显示翻页及退出提示less 也可以实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
查看时有用的命令包括:
/文本 搜索 文本
n/N 跳到下一个 或 上一个匹配
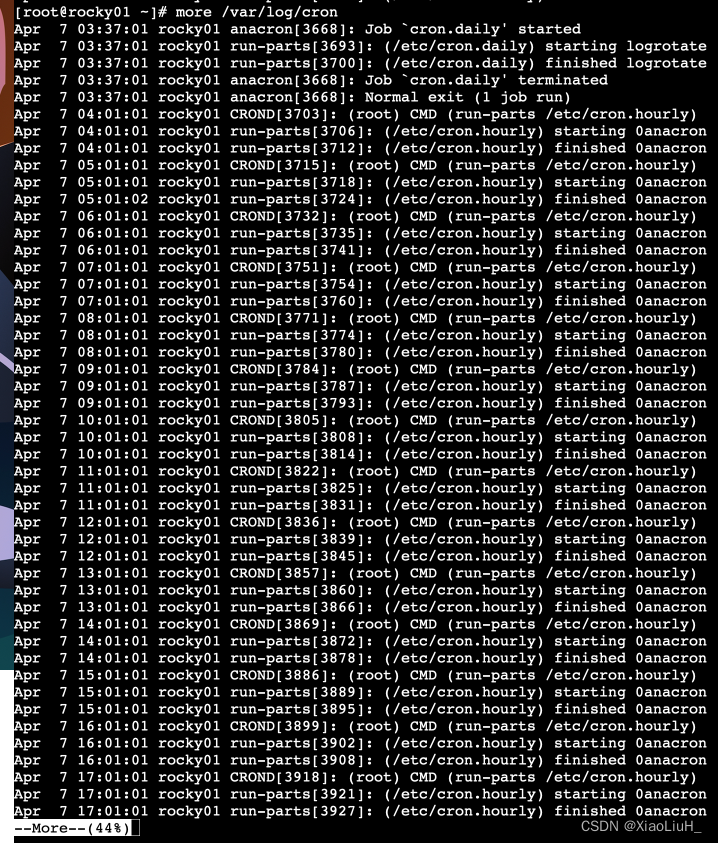
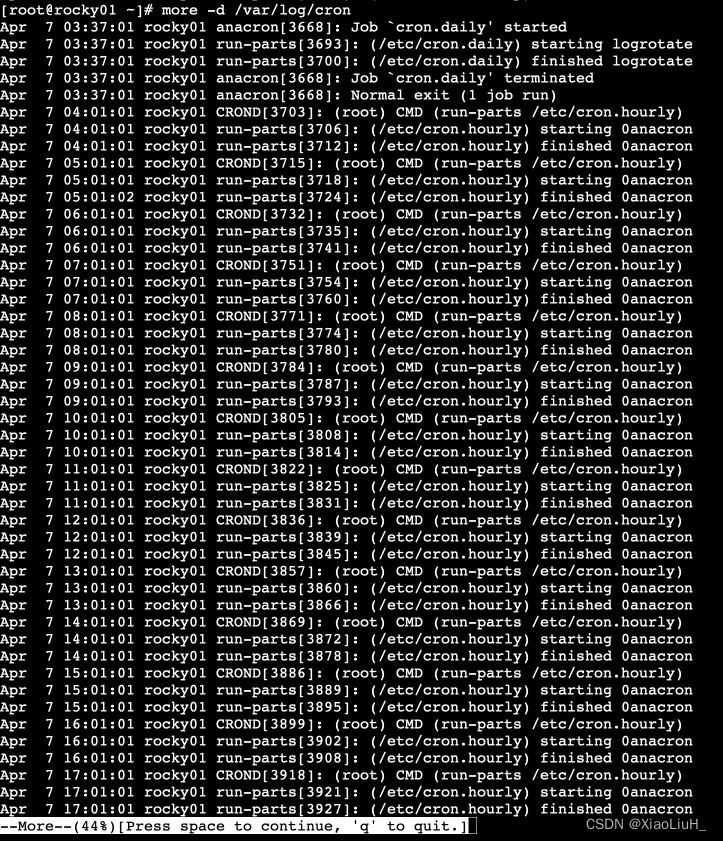
显示文本前面或后面的行内容
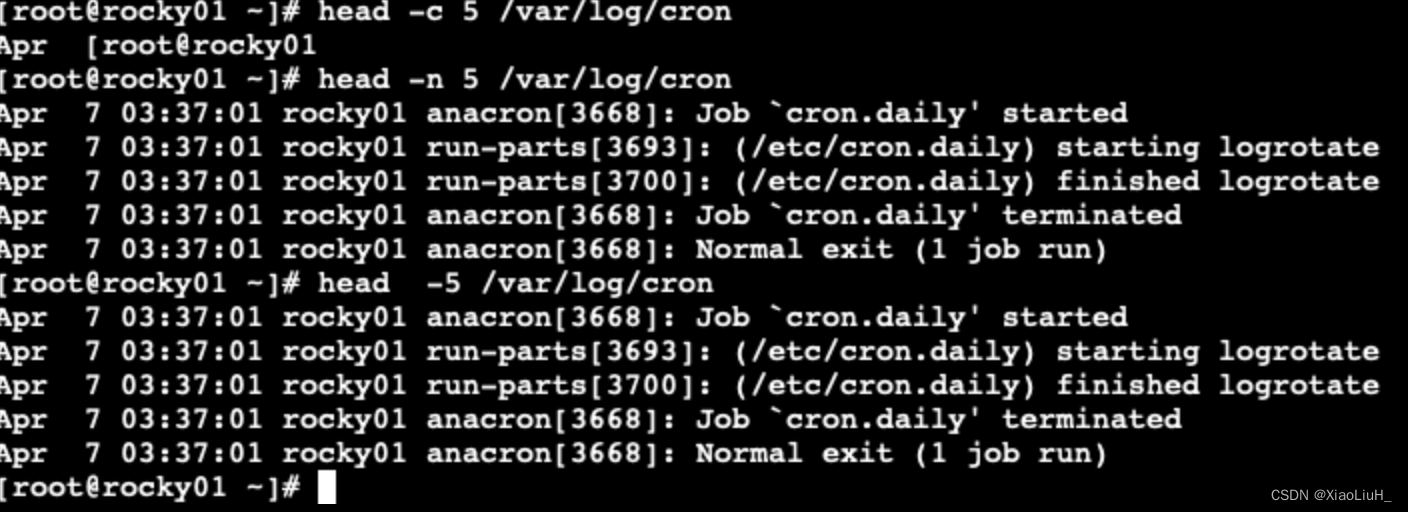
head
可以显示文件或标准输入的前面行 格式:
head [OPTION]... [FILE]...
选项:
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前-# 同上
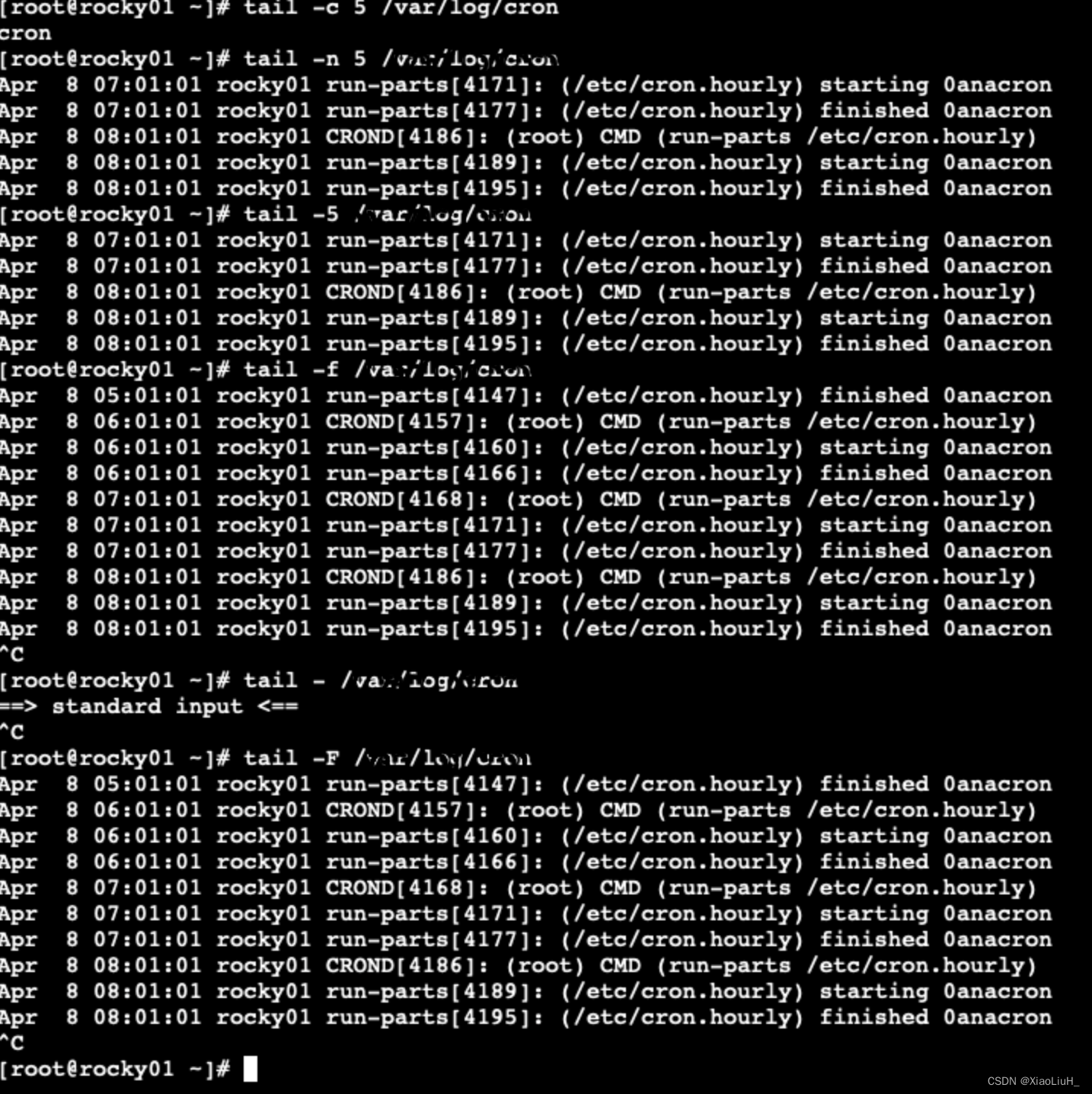
tail
tail 和head 相反,查看文件或标准输入的倒数行格式:
tail [OPTION]... [FILE]...常用选项:
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新建同名文件,将无法继续跟踪文件
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件
tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8已经无此工具
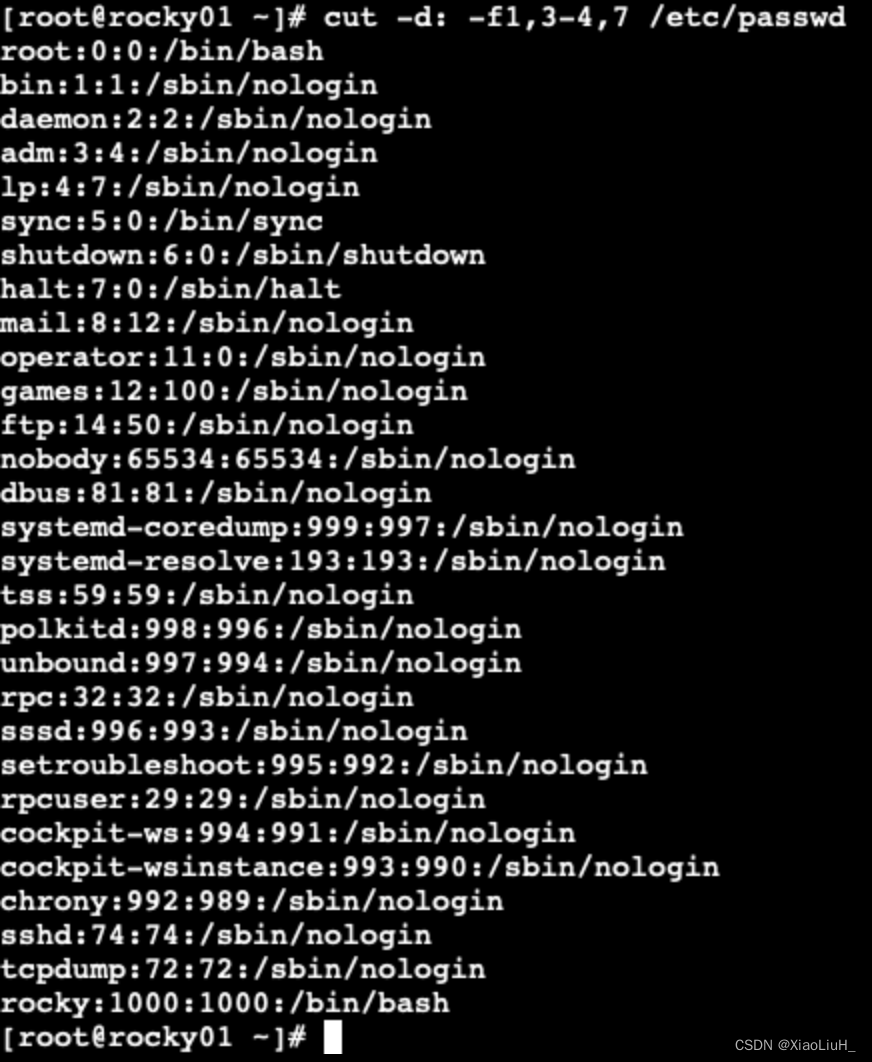
按列抽取文本 cut
cut 命令可以提取文本文件或STDIN数据的指定列 格式
cut [OPTION]... [FILE]...
常用选项-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
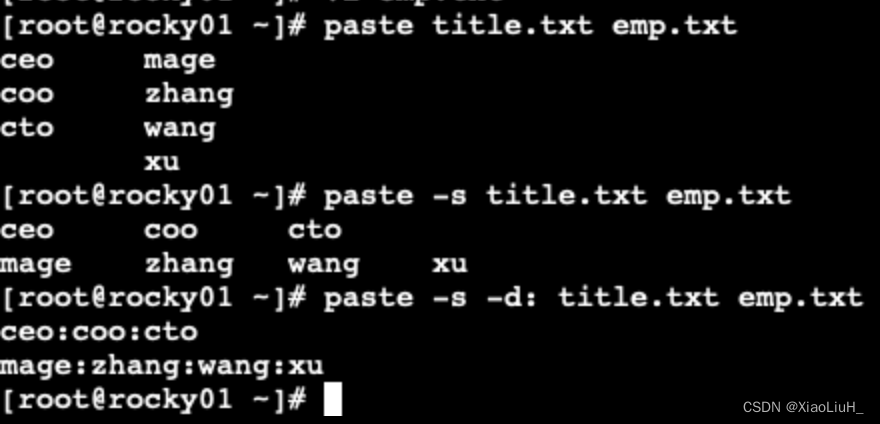
合并多个文件 paste
paste 合并多个文件同行号的列到一行
格式
paste [OPTION]... [FILE]...
常用选项:
-d #分隔符:指定分隔符,默认用TAB-s #所有行合成一行显示
分析文本的工具
文本数据统计:wc
整理文本:sort
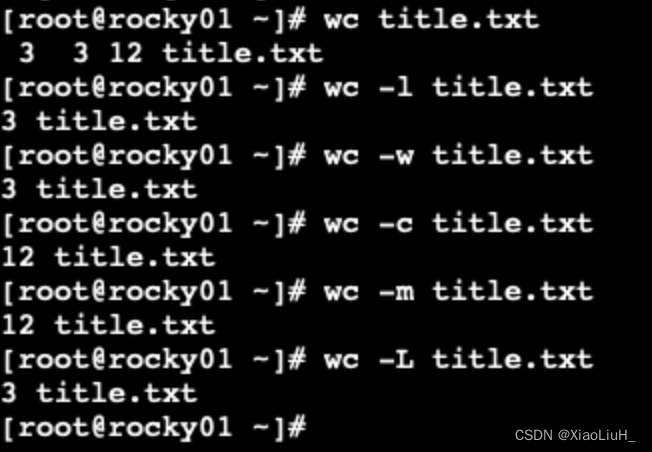
比较文件:diff和patch收集文本统计数据 wc
wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数 可以对文件或STDIN中的数据统计
常用选项
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
文本排序 sort
把整理过的文本显示在STDOUT,不改变原始文件格式:
sort [options] file(s)
常用选项
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t c 选项使用c做为字段界定符
-k # 选项按照使用c字符分隔的 # 列来整理能够使用多次
去重 uniq
uniq命令从输入中删除前后相接的重复的行格式:
uniq [OPTION]... [FILE]...
常见选项:
-c: 显示每行重复出现的次数 -d: 仅显示重复过的行
-u: 仅显示不曾重复的行
uniq常和sort 命令一起配合使用:
范例:
sort userlist.txt | uniq -c
1.2、文件查找工具
locate
格式:
locate [OPTION]... [PATTERN]...常用选项
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目 -r 使用基本正则表达式范例:
#搜索名称或路径中包含“conf"的文件
locate conf
#使用Regex来搜索以“.conf"结尾的文件 locate -r '\.conf$'
find
格式:
find [OPTION]... [查找路径] [查找条件] [处理动作]指定搜索目录层级
-maxdepth level 最大搜索目录深度,指定目录下的文件为第1级 -mindepth level 最小搜索目录深度范例:
find /etc -maxdepth 2 -mindepth 2根据文件名和inode查找
-name "文件名称"
#支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来
-iname "文件名称"
#不区分字母大小写
-inum n
#按inode号查找
-samefile name
#相同inode号的文件
-links n
#链接数为n的文件
-regex “PATTERN"
#以PATTERN匹配整个文件路径,而非文件名称范例:
find -name snow.png
find -iname snow.png
find / -name ".txt"
find /var –name "log*"
[root@centos8 data]#find -regex ".*\.txt$"
./scripts/b.txt
./f1.txt根据属主、属组查找
-user USERNAME #查找属主为指定用户(UID)的文件
-group GRPNAME #查找属组为指定组(GID)的文件
-uid UserID #查找属主为指定的UID号的文件
-gid GroupID #查找属组为指定的GID号的文件
-nouser #查找没有属主的文件
-nogroup #查找没有属组的文件根据文件类型查找
-type TYPE
TYPE可以是以下形式:f: 普通文件
d: 目录文件l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
空文件或目录
-empty范例:
[root@centos8 ~]#find /app -type d -empty组合条件
与:-a ,默认多个条件是与关系,所以可以省略-a
或:-o
非:-not !范例:
[root@centos8 ~]#find /etc/ -type d -o -type l |wc -l
307
[root@centos8 ~]#find /etc/ -type d -o -type l -ls |wc -l
101
[root@centos8 ~]#find /etc/ \( -type d -o -type l \) -ls |wc -l307
排除目录
范例:
#查找/etc/下,除/etc/security目录的其它所有.conf后缀的文件
find /etc -path '/etc/security' -a -prune -o -name "*.conf"
#查找/etc/下,除/etc/security和/etc/systemd,/etc/dbus-1三个目录的所有.conf后缀的文件 find /etc \( -path "/etc/security" -o -path "/etc/systemd" -o -path "/etc/dbus- 1" \) -a -prune -o -name "*.conf"
#排除/proc和/sys目录
find / \( -path "/sys" -o -path "/proc" \) -a -prune -o -type f -a -mmin -1根据文件大小来查找
-size [+|-]#UNIT #常用单位:k, M, G,c(byte),注意大小写敏感
#UNIT: #表示(#-1, #],如:6k 表示(5k,6k]
-#UNIT #表示[0,#-1],如:-6k 表示[0,5k]
+#UNIT #表示(#,∞),如:+6k 表示(6k,∞)
范例:
find / -size +10G根据时间戳
#以“天"为单位
-atime [+|-]#
# #表示[#,#+1) +# #表示[#+1,∞]-# #表示[0,#)
-mtime
-ctime
#以“分钟"为单位
-amin -mmin -cmin根据权限查找
-perm [/|-]MODE
MODE #精确权限匹配
/MODE #任何一类(u,g,o)对象的权限中只要有一位匹配即可,或关系,+ 从CentOS 7开始淘汰 -MODE #每一类对象都必须同时拥有指定权限,与关系
0 表示不关注
1.3、文本处理三剑客
sed
awk
grep
1.4、文本格式化命令(printf)
相当于增强版的 echo, 实现丰富的格式化输出 格式
printf "指定的格式" "文本1" "文本2"...示例格式说明符:
%s:字符串。%d:十进制整数。%c:单个字符。%f:浮点数(尽管在一些shell版本中可能不支持)。%x,%X:十六进制整数。%b,%o,%d,%u:分别代表二进制、八进制、十进制和无符号十进制整数。%p:内存地址(在某些shell实现中可用)。换行与特殊字符:
\n:新行符,用于输出后换行。\t:制表符,用于缩进。- 可以通过转义字符
\来输出特殊字符本身,例如\%输出百分号%。
2. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
2、grep命令相关
2.1、grep命令基本正则表达式
通配符:
.(点号):匹配任意单个字符。*(星号):匹配前面的字符零次或多次。?(问号):匹配前面的字符零次或一次。边界匹配:
^(脱字号):匹配行首。$(美元符号):匹配行尾。字符集:
[abc]:匹配括号内任意一个字符,如a、b或c。[!abc]或[^abc]:匹配不在括号内的任何字符。量词:
- 在基本正则表达式中,量词通常使用反斜杠加字符的方式来表示重复次数,如
\{m,n\}表示匹配前面的字符m到n次,但基本正则表达式不常用这种方式,更多在扩展正则表达式中使用。反斜杠转义字符:
\用于转义特殊字符,如\.会匹配实际的.字符。
2.2、grep命令扩展正则表达式
特殊字符:
.(点号):匹配任意单个字符(与BRE相同)。*(星号):匹配前面的字符零次或多次(与BRE相同)。+(加号):匹配前面的字符一次或多次。这是ERE特有的,BRE中需要写作\+。?(问号):匹配前面的字符零次或一次。这也是ERE特有,BRE中需要写作\?。边界匹配:
^(脱字号):匹配行首(与BRE相同)。$(美元符号):匹配行尾(与BRE相同)。字符集:
[abc]:匹配括号内任意一个字符,如a、b或c(与BRE相同)。[!abc]或[^abc]:匹配不在括号内的任何字符(与BRE相同)。量词:
{m,n}:匹配前面的字符m到n次,例如a{2,3}匹配连续的2个或3个'a'字符。这是ERE特有的,BRE中需要使用\{m,n\}。圆括号(捕获组):
(pattern):定义子表达式或捕获组,方便组合和重复使用表达式片段。这部分也是ERE特有,BRE中需要转义为\(...\)。逻辑OR:
|(管道符):匹配管道两侧的任一模式。例如cat|dog匹配包含"cat"或"dog"的行。反斜杠转义:
- 反斜杠
\仍然用于转义特殊字符,如果要匹配\本身,则需要写成\\。
3. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
3、变量相关
3.1、变量命名规则
字符组成:
- 变量名只能由字母、数字和下划线
_组成。- 变量名不能以数字开头,必须以字母或下划线开头。
大小写敏感:
- Shell脚本中的变量名是大小写敏感的,即变量
MyVar与myvar被视为两个不同的变量。保留关键字:
- 变量名不能与Shell保留关键字相同,否则会导致语法错误或意外的行为。可以通过
help命令查看Shell的保留关键字列表。空格与特殊字符:
- 变量名中不能包含空格、标点符号(除了下划线
_)以及其他特殊字符(如*、?、$、!、#等)。长度限制:
- 没有固定的长度限制,但实际上由于环境变量名会出现在环境变量列表中,过长的变量名可能会导致环境变量列表溢出等问题。
3.2、不同类型变量使用
在Linux Shell脚本中,主要存在以下几种类型的变量:
普通变量: 普通变量是通过赋值声明的,例如:
my_var="Hello, World!"
echo $my_var这里
my_var就是一个普通字符串变量。环境变量: 环境变量可在整个Shell会话中使用,通常以大写字母命名,并可通过
export命令导出为环境变量:export PATH="/usr/local/bin:$PATH"
此处
PATH就是一个环境变量,它存储了一组目录列表,系统在执行命令时会按照这些目录顺序查找可执行文件。位置参数变量: 当Shell脚本被执行时,可以通过位置参数变量(如
$1、$2等)来获取传给脚本的命令行参数:特殊变量:
$0:当前脚本的文件名。$#:传递给脚本的参数个数。$@或$*:所有传递给脚本的参数列表。$?:上一条命令的退出状态码。$-:当前Shell选项列表。$!:最后一个后台进程的PID。数组变量: Bash也支持数组变量,可以存储一组有序的数据:
fruits=("apple" "banana" "cherry")
echo "${fruits[0]}"这里
fruits是一个数组变量,通过索引可以访问数组中的元素。局部变量: 在Shell函数内部定义的变量,默认情况下为局部变量,仅在该函数内部可见:
function my_function {
local local_var="Local variable"
echo $local_var
}
4. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
4、shell编程(鸡兔同笼)
通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
[rocky@rocky01 ~]$ cat ChickenAndRabbitSums.sh
#!/bin/sh
#auth:lhecho "请输入鸡和兔共有多少个头:"
read headsecho "请输入鸡和兔共有多少个脚:"
read foots#heads=$1
#foots=$2Rabbit=$[(foots-heads-heads)/2]
Chicken=$[heads-Rabbit]
echo "鸡:$Chicken只"
echo "兔:$Rabbit只"

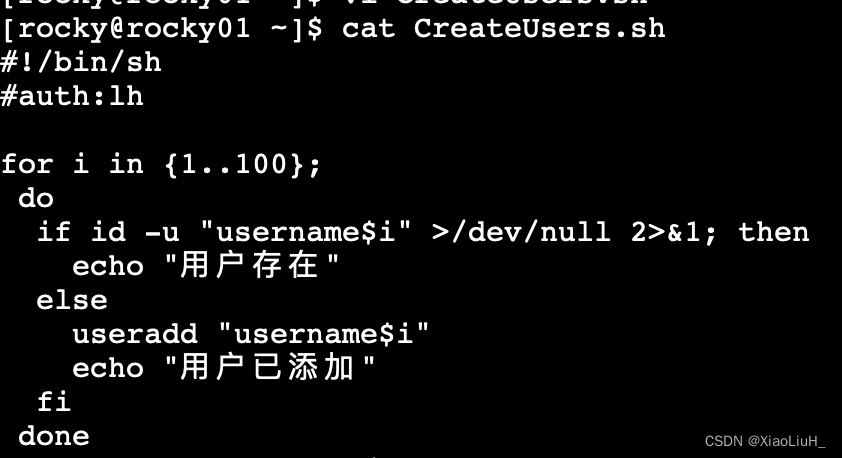
5、shell编程(创建用户)
结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1..100
2)先id判断是否存在
3)用户存在则说明存在,用户不存在则添加用户并说明已添加。

6、磁盘术语
Head(磁头): 磁头是磁盘驱动器内部的一个部件,负责读写磁盘上的数据。每个磁盘通常有多组磁头,每组对应一个磁盘表面。磁头悬挂在读写臂(Actuator Arm)上,能够在磁盘旋转的同时沿磁盘径向运动,定位到磁盘的不同位置进行读写操作。
Track(磁道): 磁道是磁盘表面上同心的圆形轨迹,它是数据存储的基础单元之一。每个磁盘面上的所有磁道都是从外向内依次编号,同一磁道上的所有位点的数据存储密度相同。当磁头定位到某一磁道上时,随着磁盘的旋转,磁头就能读写该磁道上的数据。
Sector(扇区): 扇区是磁道进一步细分的存储区域,它是磁盘上数据存取的最小物理单元。通常一个磁道会被分成若干个扇区,每个扇区包含固定大小的数据块(早期通常是512字节,现代硬盘多为4KB或更大)。扇区不仅存在于磁道上,而且在整个磁盘的各个磁道上按相同的位置划分,形成一个个环状的扇区群组。
Cylinder(柱面): 柱面是由同一磁道编号的所有磁盘面上的磁道组成的假想圆柱体。在多碟片硬盘中,所有盘片上对应的同一编号磁道共同组成一个柱面。在传统的CHS寻址方式中,柱面是硬盘寻址的重要组成部分,一个柱面内的所有扇区可以被同时读写,从而提高数据传输效率。
7. 总结MBR,GPT结构。
7、MBR,GPT结构
MBR(主引导记录):
- MBR诞生于较早时期,主要用于BIOS系统和较老的操作系统。
- MBR分区表位于硬盘的第一个扇区(512字节),其中前446字节是主引导加载程序(Boot Loader),紧接着64字节是分区表记录,最后2字节是分区表的魔数。
- MBR分区表只能支持四个主分区或三个主分区加一个扩展分区(扩展分区可以包含多个逻辑分区)。
- MBR分区表的最大限制是每个分区的大小上限约为2 TB(2^32个扇区),并且不支持超过此大小的磁盘。
- MBR不包含冗余备份,如果MBR受损,可能导致系统无法启动。
GPT(全局唯一标识分区表):
- GPT是较新的分区表格式,适用于支持UEFI(统一可扩展固件接口)的系统,也可兼容传统的BIOS系统。
- GPT分区表存储在磁盘头部和尾部各有一个备份,增强了数据安全性。
- GPT消除了分区数量限制,理论上可以支持大量分区,实际上大多数操作系统(如Windows)限制在128个主分区。
- GPT支持超大容量硬盘,理论上最大可支持高达18 EB(2^64个扇区)的硬盘。
- GPT使用全局唯一标识符(GUID)来标识分区,从而避免了传统MBR分区表可能出现的名称冲突问题。
- GPT分区表还包括分区类型GUID,可用于标识分区的具体类型和目的,比如EFI系统分区、Microsoft基本数据分区等。
8. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例
fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
8、分区、文件系统、SWAP管理总结
fdisk
- 功能:用于创建、修改和删除硬盘分区表。
- 示例:
- 查看硬盘分区信息:
fdisk -l- 进入交互模式创建/修改分区:
fdisk /dev/sda- 新增分区(在交互模式中):
n // 创建新分区
p // 选择主分区(或e选择扩展分区)
输入分区号
输入起始和结束扇区(或直接回车使用默认值)
w // 写入分区表并退出
parted
- 功能:更为强大的分区工具,支持大于2TB的大容量硬盘和GPT分区表。
- 示例:
- 查看硬盘信息:
parted /dev/sda print- 创建分区:
parted /dev/sda mkpart primary ext4 1MiB 10GiB- 删除分区:
parted /dev/sda rm 1mkfs
- 功能:创建文件系统。
- 示例:
- 创建ext4文件系统:
mkfs.ext4 /dev/sda1- 创建vfat文件系统:
mkfs.vfat /dev/sdb1tune2fs
- 功能:调整ext2/ext3/ext4文件系统的参数。
- 示例:
- 查看文件系统信息:
tune2fs -l /dev/sda1- 设置文件系统有效期:
tune2fs -e usage=mountcount=100 /dev/sda1(当文件系统被挂载100次后过期)xfs_info
- 功能:查看XFS文件系统的详细信息。
- 示例:
xfs_info /dev/sda2fsck
- 功能:检查并修复文件系统错误。
- 示例:
- 检查ext4文件系统:
fsck.ext4 /dev/sda1- 自动修复文件系统(交互模式):
fsck -y /dev/sda1mount
- 功能:挂载文件系统。
- 示例:
- 挂载ext4文件系统:
mount /dev/sda1 /mnt/mydisk- 挂载时指定选项(例如nosuid,noexec):
mount -o nosuid,noexec /dev/sda1 /mnt/mydiskumount
- 功能:卸载已挂载的文件系统。
- 示例:
umount /mnt/mydiskswapon
- 功能:启用交换分区供系统使用。
- 示例:
swapon /dev/sda3swapoff
- 功能:关闭已启用的交换分区。
- 示例:
swapoff /dev/sda3


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









