






一、List
特点:元素有序,且可重复
遍历:下标,foreach,迭代器
扩容:
初始容量10, 负载因子0.5, 扩容增量0.5倍
新容量 = 原容量 + 原容量 * 0.5 , 如 ArrayList的容量为10,一次扩容后是容量为15实现:
ArrayList
①:遍历方法
public void listIt03 () { Iterator<Integer> it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); } }②:删除的方法
for删除 public void remove03() { for (int i = list.size() - 1; i >= 0; i--) { if (list.get(i) == 3) { list.remove(i); } } System.out.println(list); } for(int i=list.size()-1;i>=0;i--){ if(list.get(i)==3){ list.remove(i); } }迭代器删除方法 public void remove05() { Iterator<Integer> it = list.iterator(); while (it.hasNext()) { if (it.next() == 3) { it.remove(); } } System.out.println(list); }③:删除的问题
public void remove01() { for (int i = 0; i < list.size(); i++) { if (list.get(i) == 3) list.remove(i); } System.out.println(list); } //问题:如果出现重复的会只删除一个另一个会挤上去代替public void remove07() { /*list.add(1); list.add(2); list.add(3); list.add(3); list.add(3); list.add(4);*/ list.remove(Integer.parseInt("2")); System.out.println(list); } //“2”要是引用类型删除指定对象,基本类型删除是下标public void testListDel02() { Integer[] arr = {1, 2, 3, 4, 5}; List<Integer> list = Arrays.asList(arr); //此时在迭代器上调用remove会报异常UnsupportedOperationException //如果将数组获取的方式改为List<Integer> list = new ArrayList<>(Arrays.asList(arr)); 则可以。 Iterator<Integer> iter = list.iterator(); while (iter.hasNext()) { Integer item = iter.next(); if (item == 3) { iter.remove(); } } }
LinkedList
LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部
线程不安全
LinkedList可被用作堆栈(stack)【包括了push,pop方法】,队列(queue)或双向队列(deque)
以双向链表实现,链表无容量限制,允许元素为null,线程不安全
适合做随机的增加或删除
反向输出:
//利用ListIterator 对List集合进行反序输出 @Test public void demo3() { ListIterator<Student> it = list.listIterator(list.size()); while(it.hasPrevious()) { Student pre = it.previous(); System.out.println("pre = " + pre); } }
Vector:
线程安全
并行性能慢,不建议使用CopyOnWriteArrayList:
写时复制
线程安全
适合于读多,写少的场景
写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给array
比Vector性能高
最终一致性
实现了List接口,使用方式与ArrayList类似
二、Set
特点:无序,不重复
思考:如果对List容器中的元素去重?
遍历:foreach,迭代器
扩容: 初始容量16,负载因子0.75,扩容增量1倍实现:
HashSet
它存储唯一元素并允许空值
依据对象的hashcode来确定该元素是否存在
由HashMap支持
不保持插入顺序
非线程安全
性能参数:初始容量,负载因子
默认值: 初始容量16,负载因子0.75
示例:new HashSet<>(20, 0.5f);public void test01() { List<Integer> tmp = new ArrayList<>(new HashSet<Integer>(list)); System.out.println(tmp); }
添加方法:
public void testSetAdd() { //如果Student没有重新实现hashCode,equals方法,则可以添加进去 boolean b0 = set.add(new Student(1, "zs")); set.forEach(t->System.out.println(t)); System.out.println(b0); }删除方法:
public void testSetDel01() { //在使用增强循环时进行删除时,只能删除单个元素,且删除后必须马上break, for(Student stu: set) { if(stu.getId() == 1) { set.remove(stu); break; } } }迭代器删除方法:
@Test public void testSetDel02() { Iterator<Student> it = set.iterator(); while(it.hasNext()) { //没有调用next,直接调用remove,将报异常 it.next(); it.remove(); } set.forEach(t->System.out.println(t)); }
TreeSet
是一个包含有序的且没有重复元素的集合
作用是提供有序的Set集合,自然排序或者根据提供的Comparator进行排序
TreeSet是基于TreeMap实现的public void demo() { TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { // TODO Auto-generated method stub return o2.getId() - o1.getId(); } });//排序的方法,根据id排序 set.add(new Student(1, "zs")); set.add(new Student(2, "li")); set.add(new Student(3, "ww")); set.add(new Student(4, "zl")); set.forEach(t -> System.out.println(t)); }
三、Map
特点:
无序,键值对,键不能重复,值可以重复,
键重复则覆盖,没有继承Collection接口
扩容:初始容量16,负载因子0.75,扩容增量1倍
遍历:
先获取所有键的Set集合,再遍历(通过键获取值)
取出保存所有Entry的Set,再遍历此Set即可public void demo9() { Iterator<Entry<String, String>> it = map.entrySet().iterator(); while(it.hasNext()) { Entry<String, String> entry = it.next(); System.out.println(entry.getKey() + ": " + entry.getValue()); } } //获取键和值
实现:
HashMap
线程不安全,最常用,速度快
内部采用数组来存放数据
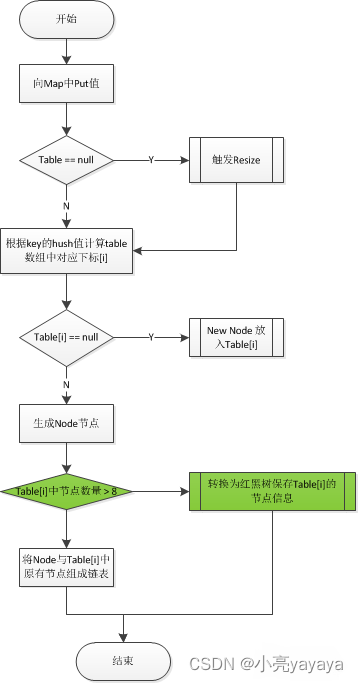
基本原理
put执行过程
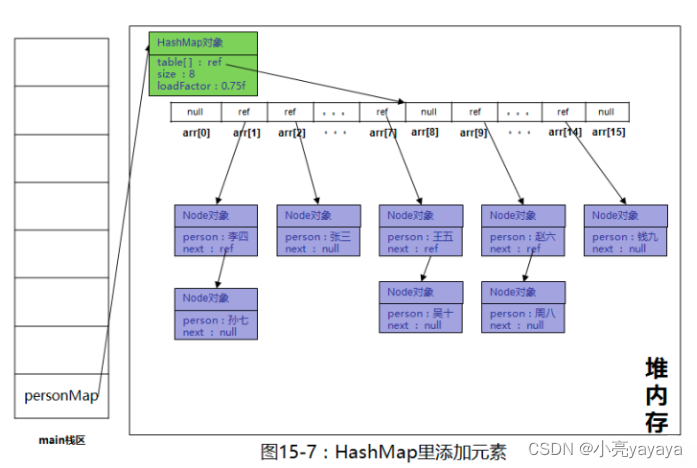
Table数组中的的Node链表结构示意图
红黑树结构示意图
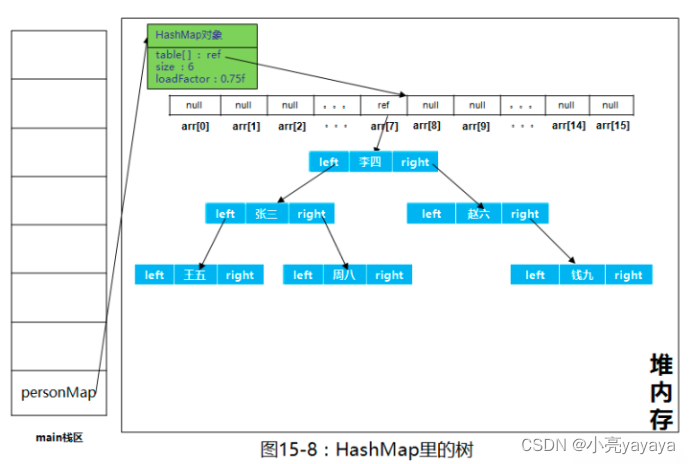
流程图中绿色标出的部分为JDK8新增的处理逻辑,目的是在Table[i]中的Node节点数量大于8时,通过红黑树提升查找速度
HashTable
线程安全,不太常用
遍历:
@Test public void demo12() { Hashtable<String,String> table = new Hashtable(); table.put("1", "xx"); table.forEach((key,val) -> System.out.println(key + ": " + val)); }
ConcurrentHashMap
线程安全,比HashTable性能高
public void demo13() { ConcurrentHashMap<String,String> table = new ConcurrentHashMap<>(); table.put("1", "xx"); table.forEach((key,val) -> System.out.println(key + ": " + val)); }
TreeMap
key值按一定的顺序排序
添加或获取元素时性能较HashMap慢
因为需求维护内部的红黑树,用于保证key值的顺序public void setup() { treeMap = new TreeMap<String,Student>(new Comparator<String>() { @Override public int compare(String o1, String o2) { // TODO Auto-generated method stub // 负数 0 正数 return o1.compareTo(o2); } }); treeMap.put("1", new Student(1, "zs")); treeMap.put("2", new Student(3, "ls")); treeMap.put("3", new Student(2, "ww")); treeMap.put("4", new Student(4, "zl")); }
LinkedHashMap
继承HashMap
LinkedHashMap是有序的,且默认为插入顺序
当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMapMap<String, String> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("name1", "josan1"); linkedHashMap.put("name2", "josan2"); linkedHashMap.put("name3", "josan3"); Set<Entry<String, String>> set = linkedHashMap.entrySet(); Iterator<Entry<String, String>> iterator = set.iterator(); while(iterator.hasNext()) { Entry entry = iterator.next(); String key = (String) entry.getKey(); String value = (String) entry.getValue(); System.out.println("key:" + key + ",value:" + value); }

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









