




 本文深入探讨了用于视频动作识别的Two-Stream卷积网络,强调了光流在时间流ConvNets中的作用。通过不同的光流输入配置,如光流叠加、双向光流和平均流差集,研究了它们对识别效果的影响。实验表明,多帧信息和光流处理对于提高识别准确性至关重要。
本文深入探讨了用于视频动作识别的Two-Stream卷积网络,强调了光流在时间流ConvNets中的作用。通过不同的光流输入配置,如光流叠加、双向光流和平均流差集,研究了它们对识别效果的影响。实验表明,多帧信息和光流处理对于提高识别准确性至关重要。
Two-Stream Convolutional Networks for Action Recognition in Videos
将单帧的图像信息和帧与帧之间的变化信息进行融合,单帧的图像可以形成对空间的描述,而通过光流法等方法形成的时间的描述(差分),从而达到时间和空间互补的目的。而本篇文章重点在讲述光流部分,考虑了几种不同的基于光流的输入。
Two-stream architecture
视频可以分解为空间和时间组成部分。空间部分,以独立的帧形式存在,有着关于场景、对象等信息;时间部分,以帧与帧之间的运动形式存在,传递着观察者和场景的相对运动。本文设计的视频识别架构分为两种流,如图1所示。
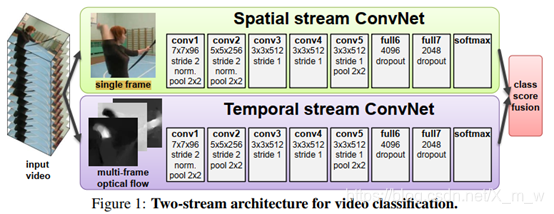
每一种stream都是用深度卷积网络构造的,最后再将两者softmax分数融合。文章考虑了两种融合方法:averaging and training a multi-class linear SVM [6] on stacked L2-normalised softmax scores as features. 另外从输入可以看出,一个是单帧图像,一个是多帧之间的光流(optical flow),这两个都是提前提取好的(可用OpenCV里面的方法)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5599
5599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









