










 本文通过一个实际问题介绍了如何使用SQL查询实现数据的倒序排序并进行累计,直到达到特定条件为止。具体场景是用户表按最后修改时间倒序排序,累计年龄,当累计值超过100时停止。通过设置变量和WHERE子句,可以有效地完成这个任务。示例SQL查询展示了如何操作,并给出了查询结果。
本文通过一个实际问题介绍了如何使用SQL查询实现数据的倒序排序并进行累计,直到达到特定条件为止。具体场景是用户表按最后修改时间倒序排序,累计年龄,当累计值超过100时停止。通过设置变量和WHERE子句,可以有效地完成这个任务。示例SQL查询展示了如何操作,并给出了查询结果。
今天有个朋友遇到一个问题:
单据根据创建时间倒序排序
累计单据金额等于或者超过1000时停止查询,返回查出来的数据
当时我没有这样的表,于是我就用现成的一张表,设计了如下的场景,理论一样
有这样的业务场景:
用户表根据最后修改时间倒序排序;
然后从上往下累计年龄累计,当值超过或等于100时停止。
首先有如下的表:
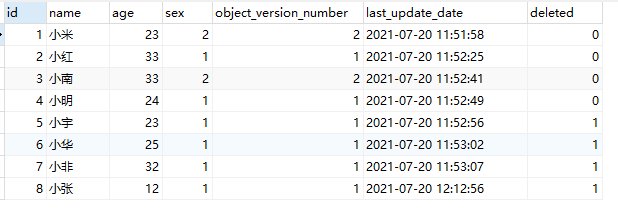
然后使用@参数保存累计的值,通过where来判断结果获取值,sql如下
SELECT
T1.id,
T1.num,
T1.NAME,
T1.age,
T1.last_update_date
FROM
(
SELECT
@tt := @tt + t.age AS num,
t.*
FROM
( SELECT * FROM `user` ORDER BY last_update_date DESC ) t,
( SELECT @tt := 0 ) T2
) T1
WHERE
T1.num - T1.age < 100
查出结果如下
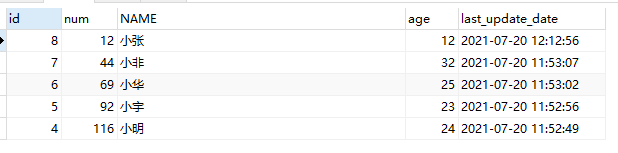
这样就完成了上述的问题了。

















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









