



使用ollama本地部署qwen2并api调用
选型
ollama是一个集成了许多模型的工具,自带实现了API的整合和调用,只需要命令就可以运行一些支持的常见大模型,且支持对gguf类型的模型进行部署。微调模型可以直接压缩成这个类型的文件,对后续微调模型提供基础。
安装
在wsl中运行 curl -fsSL [https://ollama.com/install.sh](https://ollama.com/install.sh) | sh 命令,直接抓取安装指令,自动安装,并且配置到环境中。
运行 ollama -v 出现 ollama version is 0.1.45 的输出,ollama安装成功。
运行 ollama run qwen2 ,即可开始对话

Api调用
通过查阅资料,ollama会在本地的11434端口自动开启服务
查阅官方的api参考文档,得到使用说明。
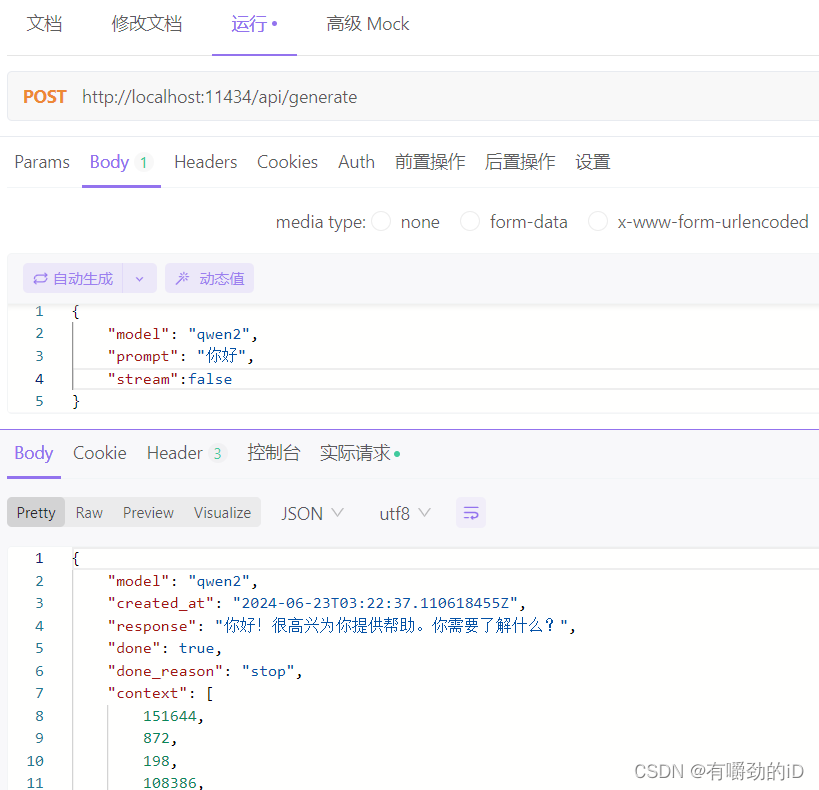
尝试apifox调用

发现返回值会用每一个token单独返回,不利于开发。
查阅文档后发现要加入 "stream":false 的参数。
加入后再次运行,返回顺利。
编写代码
创建一个 askLocalQwen2Model 方法,传入参数prompt,按照JSON传入,得到与api工具直接调用相同的结果。
最后再使用JSON工具包提取出返回值,String的返回参数是response的结果。
public static String askLocalQwen2Model(String prompt) throws IOException {
String urlString = "http://localhost:11434/api/generate";
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// 设置请求方法为POST
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "application/json; utf-8");
conn.setRequestProperty("Accept", "application/json");
conn.setDoOutput(true);
// 创建要发送的JSON对象
JSONObject jsonInput = new JSONObject();
jsonInput.put("model", "qwen2");
jsonInput.put("prompt", prompt);
jsonInput.put("stream", false);
// 将JSON输入写入请求的输出流
try (OutputStream os = conn.getOutputStream()) {
byte[] input = jsonInput.toString().getBytes("utf-8");
os.write(input, 0, input.length);
}
// 读取响应内容
try (BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"))) {
StringBuilder response = new StringBuilder();
String responseLine;
while ((responseLine = br.readLine()) != null) {
response.append(responseLine.trim());
}
// 解析JSON响应并提取response字段
JSONObject jsonResponse = new JSONObject(response.toString());
return jsonResponse.getString("response");
}
}


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









