



A novel conditional weighting transfer Wasserstein auto-encoder for rolling bearing fault diagnosis with multi-source domains一种新的多源域滚动轴承故障诊断条件加权传递Wasserstein自编码器
a b s t r a c t
基于单一源域到目标域的迁移学习在滚动轴承跨域故障诊断任务中受到了广泛的关注。然而,实际问题往往包含多个源域数据,而目标域所包含的信息在不同的源域之间差异很大。
因此,从多源域到目标域的转移模式无疑具有更光明的应用前景。
在此基础上,提出了一种多源域迁移学习方法——条件加权迁移Wasserstein自编码器,以解决跨域故障诊断的难题。
与传统的直接对准源域和目标域的分布对齐思路不同,本文提出的框架采用间接潜在对齐的思路,即利用高斯先验分布在潜在特征空间中间接对准源域和目标域的特征分布,从而实现更好的特征对齐。
此外,考虑到不同源域包含目标域信息的可变性,设计了一种巧妙的条件加权策略来量化不同源域与目标域的相似度,进一步帮助所提模型最小化条件分布的差异。
跨域故障诊断任务充分验证了所提框架能够将各源领域的知识充分传递到目标领域,具有广泛的应用前景。
1. Introduction
滚动轴承被称为“工业接头”。作为齿轮箱、减速器、风机、发电机、发动机等机械设备中应用最广泛的零部件。当故障发生时,至少会影响使用,导致停机甚至人员伤亡[1-3]。因此,滚动轴承的状态监测和故障诊断是旋转机械系统维护中非常关键的一部分[4,5]。
基于深度学习的故障诊断算法已广泛应用于滚动轴承故障识别任务中[6-9]。然而,这些故障诊断算法成功应用的一个重要前提是训练数据和测试数据的分布一致[10,11]。在实际工程中,通常难以获得测量数据的标签,这限制了这些故障诊断算法在实际应用中的应用。迁移学习可以利用现有的专业知识来解决新的相关问题,这意味着它在应对上述问题的挑战方面具有很大的潜力[12,13]。
目前,已成功应用于滚动轴承故障诊断的迁移学习方法可分为三类。
第一种是基于传统的迁移学习算法,包括迁移分量分析(TCA)、联合分布自适应(JDA)和流形嵌入式分布对齐(MEDA)。
Ma等人利用增强的TCA传递故障诊断。实验结果表明,该方法的诊断性能随着目标域中标注数据量的增加而显著提高,但当目标域中标注数据未知时,该方法的诊断准确率仅为53.54%[14]。
Wu等人针对JDA提出了一种迁移学习方法来进行故障诊断的迁移。结果表明,该方法在目标域内标记数据与未标记数据的比例很小的情况下,可以达到较高的诊断准确率[15]。
Zhao等人设计了一种新的MEDA传递故障诊断。结果表明,当目标域中标记数据与未标记数据的比例为1:155时,该方法的诊断准确率为96.42%[16]。然而,这两种方法不能直接用于处理未知标记数据的问题。
从上述描述中可以推断,这些基于传统迁移学习算法的故障诊断方法对源域和目标域分布的对齐能力有限,在处理跨域故障诊断任务时仍需借助少量标注数据,对目标域未知标注数据的处理能力有限甚至没有,这也限制了传统迁移学习算法在故障诊断中的进一步发展。
由于传统迁移学习算法的局限性,深度迁移学习算法因其强大的特征提取能力而备受关注,并已成为解决从单一源域到目标域诊断问题的主流算法[17-20]。
深度迁移学习算法主要通过添加正则化项来约束深度模型的特征提取过程,提取源域和目标域的相似特征和共同特征,最后利用标记的源数据实现对目标数据的精确分类。
此外,正则化项包括Wasserstein距离、最大平均距离(MMD)、联合MMD和对抗域自适应。Zhang等人提出了一种新的方法,通过Wasserstein距离和对抗性领域适应来解决不同领域的问题。
结果表明,当源域与目标域差异较小时,该方法的诊断准确率可达到99%左右,但当源域与目标域差异较大时,该方法的诊断准确率较差[21]。
Wang等人设计了一种对抗转移网络,采用Wasserstein距离和对抗域自适应来学习不同域之间的域不变特征。实验结果表明,该网络对所有跨域故障诊断案例的平均准确率约为90%,明显优于其他深度迁移学习方法[22]。
Yang等人利用烟雾理论构建了多层领域自适应网络来传递诊断知识。结论表明,该方法在诊断不同设备之间复杂的跨域问题时,准确率可达到80%左右[23]。
Guo等人将MMD发展为卷积神经网络(CNN)来提取域不变特征。结论证明该方法比其他方法更能满足跨域任务的挑战[24]。
Han等人设计了一种基于联合MMD的转移网络,对边缘分布和条件分布的域特征进行对齐。结果表明,该方法可以精确地解决单源到目标域传输模式下的跨域故障诊断任务[25]。
Jiao等人利用残差CNN构建了一个深度网络,利用联合MMD和对抗域自适应,帮助残差CNN获得不同域的域不变和类别判别特征。结论表明该方法优于现有方法[26]。
由以上描述可以推断,单源域方法的更新迭代速度非常快,现有方法可以较好地解决单源到目标域转移模式下的故障诊断问题。然而,实际问题往往包含多个源域数据,而目标域所包含的信息在不同的源域之间差异很大。如果直接采用这些单源域方法,可能会导致某些转移情况下的识别精度不能满足实际需要,因此这些方法难以处理多源域问题。
对于实际问题中的多源域问题,与其选择特定的源域,不如直接将多个源域的信息组合起来识别未知的目标域。
因此,多源域转移故障诊断方法能够综合利用多个域准确识别未知域,成为近年来的研究热点[27,28]。
Yang等人采用直接对齐源域和目标域数据分布的思路,利用多源集成传输网络解决多域旋转机械故障诊断问题。
结果表明,该框架在诊断性能上优于其他单源域方法[29]。**Li等人设计了一种结合强化学习和集成学习的迁移学习方法,直接对齐不同域的特征分布。**实验结果表明,所设计的方法可以很好地解决具有多个源域的跨域任务[30]。Rezaeianjouybari等人提出了一种多源域自适应网络,将源域和目标域的分布在特征级和任务级进行对齐,其结论与上述两种方法一致[31]。
纵观相关文献,多源域转移故障诊断的研究还处于起步阶段。现有的方法忽略了所有源域之间的差异,通过直接对齐域分布来实现源到目标的识别。然而,这种对齐思路很难学习到不同域之间的公共特征空间,从而影响最终的诊断结果。
综上所述,现有的迁移学习方法均采用源域和目标域直接对齐的思路,但当源域和目标域的数据分布差异较大时,上述对齐思路存在明显缺陷。
因此,本文设计了一种间接对齐思想,利用高斯先验分布在潜在特征空间中对源和目标的特征分布进行对齐。
之前的想法和提出的特征对齐思想之间的比较如图1所示。此外,现有的多源域迁移学习方法对所有源域都是平等对待的,因此需要制定适当的加权策略来量化不同源域与目标域的相似度。
新的生成算法 Wasserstein 自动编码器(WAE)[32] 结合了变异自动编码器[33] 和生成对抗网络[34] 的优点,可以将原始数据的分布编码成近似的标准正态分布,然后进行解码,从而获得高质量的数据。
因此,在WAE的启发下,提出了一种用于多源域滚动轴承故障诊断的条件加权传递WAE (CWTWAE)。
为了更清晰地说明我们的框架,将多源域故障诊断任务划分为多个单源域故障诊断任务。
首先,将源域数据输入到特征编码器中,利用Wasserstein距离惩罚近似高斯先验分布;
其次,将编码后的目标分布和高斯先验分布输入到特征解码器中,得到重构数据,并采用设计的不配对L1距离惩罚最小化差异;
最后,将编码后的源分布和目标分布输入特征鉴别器进行判断。
此外,针对多源域故障诊断任务,设计了一种巧妙的条件加权策略,量化不同源域与目标域的相似度,使模型的条件分布差异最小化。分类器将输出目标域的最终识别结果。CWTWAE的主要新颖之处总结为:
(1) 针对多源域传输故障诊断,提出了一种复杂的传输框架——条件加权传输Wasserstein自编码器。
(2) 该框架采用间接潜在对齐过程,利用高斯先验分布对潜在特征空间中的特征分布进行对齐。
(3) 设计了一种巧妙的条件加权策略来量化不同源域与目标域的相似度,并帮助所提出的模型最小化条件分布的差异。
本文的其余部分设计如下。第2节描述了多源域故障诊断问题和Wasserstein距离。第3节将详细介绍CWTWAE。第4节专门演示所建议方法的有效性。第5节对本文进行总结。
2. Preliminary
2.1. 多源域故障诊断问题
假设包含丰富标记数据的K个源域表示为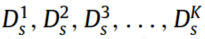 ,未标记的目标域记为
,未标记的目标域记为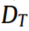 。
。
第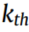 个源域记为
个源域记为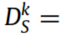
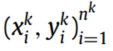 ,未标记的目标域记为
,未标记的目标域记为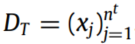 ,其中
,其中 和
和 分别表示
分别表示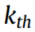 源域和目标域的样本个数。
源域和目标域的样本个数。
由于所有源域在分布上都与目标域不一致,因此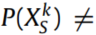
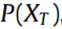
,其中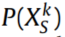 表示第k个源域的数据分布,
表示第k个源域的数据分布,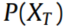 表示目标域的数据分布。此外,故障条件空间在所有数据集上是一致的,这表明所有域共享相同的标签空间。
表示目标域的数据分布。此外,故障条件空间在所有数据集上是一致的,这表明所有域共享相同的标签空间。
上述任务的核心思想是使用多个标记的源域建立一个分类器,使未标记的目标域的识别误差最小化。
难点在于源域和目标域的数据分布不同,不同源域的数据分布也不同。
因此,CWTWAE利用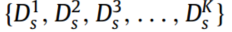 和
和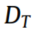 来训练分类器以准确预测DT的故障状态。
来训练分类器以准确预测DT的故障状态。
2.2. Wasserstein distance
将沃瑟斯坦距离视为最优运输问题,其目的是寻找最优运输策略。
Wasserstein距离不仅可以度量离散分布与连续分布之间的距离,还可以在将一种分布转化为另一种分布的过程中保持分布本身的几何特征。
因此,在本文提出的框架中引入Wasserstein距离,将源数据分布转化为近似正态分布。分布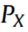 与
与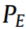 之间的Wasserstein距离可表示为:
之间的Wasserstein距离可表示为:
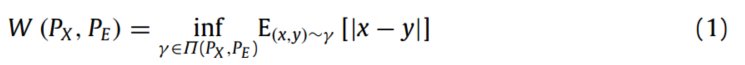
式中,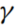 为联合概率分布,
为联合概率分布,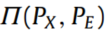 为联合概率分布γ的集合。
为联合概率分布γ的集合。
3.1. The conditional weighting strategy 条件加权策略
我们设计了一种巧妙的条件加权策略来量化不同源域与目标域的相似性,并帮助所提出的模型最大限度地减少条件分布的差异。
假设第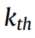 个源域的权值为
个源域的权值为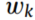 ,值越大表示与目标域的相似度越高。为了减少不同域之间条件分布的差异,我们使用类条件MMD来计算
,值越大表示与目标域的相似度越高。为了减少不同域之间条件分布的差异,我们使用类条件MMD来计算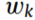 和第k个源域与目标域的不相似度,其公式为:
和第k个源域与目标域的不相似度,其公式为:
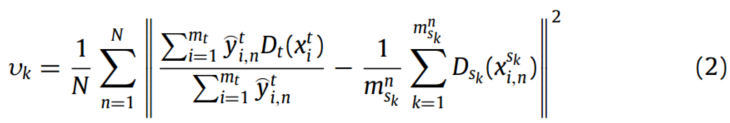
式中,N为故障条件个数,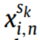 为第k源域故障条件N下的第i个样本,
为第k源域故障条件N下的第i个样本,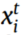 为目标域的第i个样本。
为目标域的第i个样本。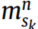 为
为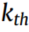 源域故障条件n下的样本个数,
源域故障条件n下的样本个数,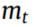 为目标域的样本个数。
为目标域的样本个数。 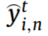 表示
表示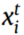 属于故障条件n的概率。
属于故障条件n的概率。
下一个关键是使用获得的不相似度来计算相应源域的权重,其中不相似度越大意味着权重越小。因此,将权重定义为:
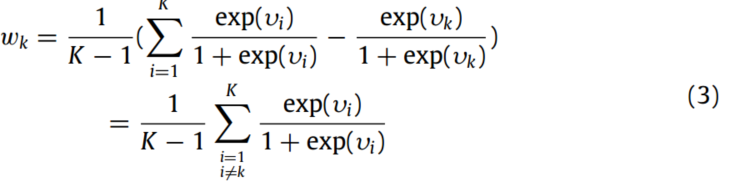
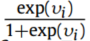 的取值范围为[0.5,1],而由式(3)可以推导出
的取值范围为[0.5,1],而由式(3)可以推导出 的取值范围也为[0.5,1],并且
的取值范围也为[0.5,1],并且 的取值由除k以外的所有i决定。从
的取值由除k以外的所有i决定。从 的取值范围可以看出,所有源域都可以参与CWTWAE的训练过程,并赋予相应的权值。
的取值范围可以看出,所有源域都可以参与CWTWAE的训练过程,并赋予相应的权值。
随着CWTWAE训练的进行,条件分布差值会减小, 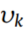 的值会更加准确,相应的权值也会更加合理。
的值会更加准确,相应的权值也会更加合理。
3.2. 条件加权转移wasserstein自编码器
本文重点解决了同一滚动轴承在不同工况下的跨域故障诊断问题,研究在实际应用中具有重要意义。
由于滚动轴承的实际运行条件是不断变化的,我们往往无法掌握滚动轴承在所有运行条件下的数据分布。
因此,当运行条件发生变化时,如何准确识别滚动轴承的工作状态是保证设备健康运行的必要条件。
此外,由于所有数据都来自同一轴承,当失效模式相同时,虽然不同工况下的数据分布具有一定的相似性,但如果直接应用深度学习模型进行处理,分布差异较大将导致识别效果较差。
因此,我们的研究目的是通过采用已知部分工况下的滚动轴承数据来识别未知的滚动轴承数据。
需要强调的一点是,上述假设源域和目标域具有相同的失效模式在现有研究中非常普遍[17-31]。
现有的迁移学习方法总是直接对齐特征分布,但在实践中往往很难将不同的复杂特征分布对齐到一个共同的特征空间中。
基于最优传输成本(Wasserstein)的 WAE 可以将原始数据分布转化为近似高斯分布,然后通过对抗训练生成高度近似的数据。
因此,受 WAE 的启发,我们开发了一种新型框架 CWTWAE 来解决多源滚动轴承故障诊断问题。
CWTWAE采用间接潜在对齐过程,利用高斯先验分布构造公共特征空间,并采用巧妙的条件加权策略量化不同源域与目标域的相似度,使所提出的模型在条件分布上的差异最小化。提出的框架CWTWAE如图2所示。
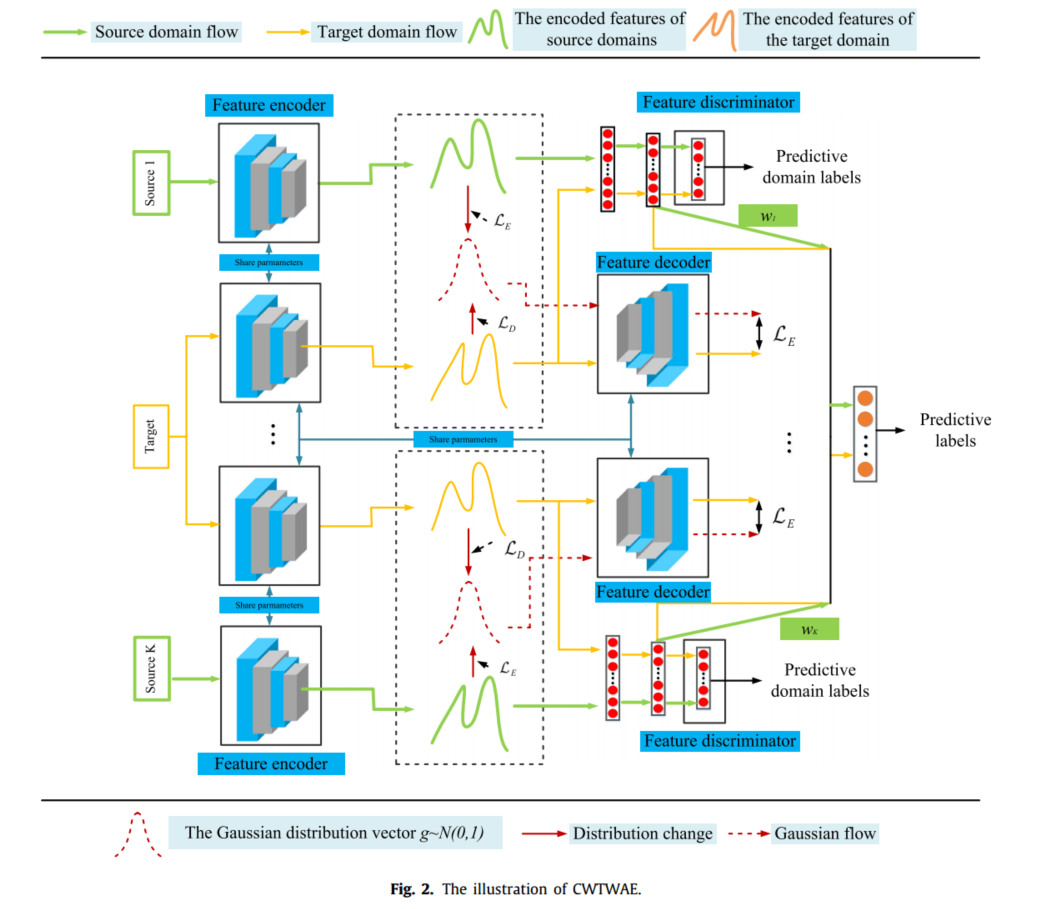
如图2所示**,CWTWAE主要包括特征编码器、特征解码器、特征鉴别器和分类器四个部分**。各部件的结构参数见表1。
特征编码器的作用是将所有域映射到潜在特征空间中。
特征解码器的功能是利用高斯先验分布和目标域特征分布对数据进行重构。
特征鉴别器的作用是区分源或目标的特征分布,
分类器的作用是获取标签。
然后,我们将详细描述CWTWAE的每个部分。
(1) Feature extractor
特征提取器包括特征编码器和特征解码器。
由于CNN具有出色的特征提取能力和在生成模型中的广泛应用,因此利用CNN构建CWTWAE的特征编码器和特征解码器。
特征编码器将所有域编码到潜在特征空间中,编码后的源特征分布在Wasserstein距离惩罚约束下接近高斯先验分布。
所有编码后的源特征分布对高斯先验分布的分布差异损失LE计算为:
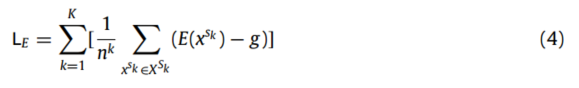
式中,K表示源域总数,n K表示第K个源域样本个数,E(·)表示编码过程,g为高斯先验分布。
考虑到WAE独特的编解码结构可以从潜在空间生成数据,因此利用解码器从编码后的目标域特征分布和高斯先验分布生成数据。
利用非配对 L1 距离惩罚直接减少两组重建数据之间的差异,从而减少分布差异。两组重建数据之间的分布差异损失 LD 定义为
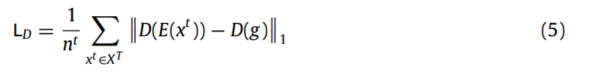
其中,nt表示目标域样本的个数,D(·)表示解码过程。
需要注意的是,在CWTWAE的训练过程中,编码器和解码器共享参数信息。随着训练的继续,编码后的源特征分布和编码后的目标特征分布将逐渐接近高斯先验分布,它们之间的分布差异将逐渐减小。
(2)特征鉴别器
特征编码器和特征鉴别器采用对抗性训练,使编码后的源特征分布和编码后的目标特征分布更加相似。
其中,前者用于提取源域和目标域的潜在特征分布,后者用于识别潜在特征分布的源。
通过对抗性训练,特征编码器可以提取更近似的潜在特征分布,使得特征鉴别器无法准确识别潜在特征分布的来源。
上述损失可表示为:
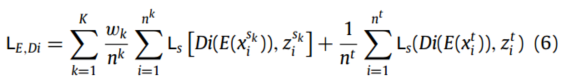
其中,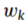 为第k个源域的权值,Ls[·,·]表示平方损失,Di(·)表示判别过程。
为第k个源域的权值,Ls[·,·]表示平方损失,Di(·)表示判别过程。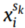 表示KTH源域的第I个样本,
表示KTH源域的第I个样本,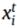 表示目标域的第I个样本。
表示目标域的第I个样本。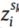 和
和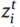 分别表示对应于
分别表示对应于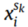 和
和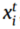 的域标签。
的域标签。
(3) Classifier
分类器主要有两个功能,一是借助相应的标签准确识别源域的故障情况,二是获取目标域的伪标签进行权值计算,并输出最终的识别结果。识别损失表示为:
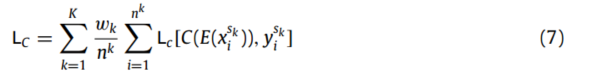
式中![Lc[·,·]](https://i-blog.csdnimg.cn/direct/41905aa9940b43baa3db22cd20cc5ee3.png) 表示交叉熵损失,
表示交叉熵损失,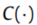 表示分类过程,
表示分类过程,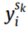 表示
表示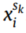 对应的标签。
对应的标签。
3.3. Training objective of CWTWAE
拟议框架的训练 CWTWAE 在特征提取器和分类器中最小化,在特征判别器中最大化,CWTWAE 的总损失描述为:
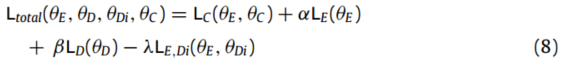
其中α, β和λ是平衡因子。θE、θD、θDi、θC分别为特征编码器、特征解码器、特征鉴别器、分类器的参数。
采用随机梯度下降法对CWTWAE进行优化,优化后的参数计算为:
采用随机梯度下降法对CWTWAE进行优化,优化后的参数计算为:
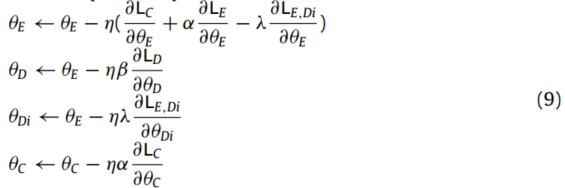
在满足迭代停止条件后停止训练。然后得到训练好的特征提取器、特征鉴别器和分类器,使训练好的CWTWAE能够对未知目标域的故障情况进行准确分类。
4. Experiments
4.1. Data illustration
数据集1:Case Western Reserve University轴承数据集[35]待测轴承由功率约为1.5 kW的三相交流电机驱动。滚动轴承故障均为单点故障,包括内圈故障、外圈故障和球故障,损伤尺寸分别为7mil、14mil和21mil,采样频率为48 kHz。电机转速分别设置为1730、1750、1772。因此,测量数据包含三个不同分布的数据集,分别为C1(1730 rom)、C2(1750 rom)和C3(1772 rom),并基于这三个数据集实现了三个多源域故障诊断案例。C1、C2和C3的频率数据被分成2000个样本,每个样本有784个数据点。
数据集2:江南大学轴承数据集[36],试验台如图3所示。轴承状态分别为正常、内圈、外圈和滚子故障,采样频率为50 kHz。主轴转速分别设置为600、800、1000。
因此,测量数据包含三个不同分布的数据集,分别表示为D1(600 rom)、D2(800 rom)和D3(1000 rom),并基于这三个数据集实现三个多源域故障诊断案例。D1、D2和D3的频率数据分成1000个样本,每个样本有784个数据点。
数据集3:帕德博恩大学轴承数据集[37]。模块化测量装置如图4所示。该数据集从32个轴承中测量,其中有6个正常轴承,其余为损坏轴承,采样频率为64 kHz。损坏的原因既有人为损坏的,也有加速寿命试验的,故障情况有正常(N)、轻微外圈(SlOR)、严重外圈(SeOR)、轻微内圈(SlIR)和严重内圈(SeIR)五种。测量数据包含4种工况,分别为E1(1500 rpm、0.1 Nm和1000 N)、E2(1500 rpm、0.7 Nm和400 N)、E3(1500 rpm、0.7 Nm和1000 N)和E4(900 rpm、0.7 Nm和1000 N),并基于这4个数据集实现了12个多源域故障诊断案例。E1、E2、E3和E4的频率数据分成1500个样本,每个样本有784个数据点。


















 6808
6808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









