




Compute Canada平台及其常见命令介绍
前言
大家好,笔者目前身处加拿大,在学习神经网络的过程中由于无法使用国内服务器进行网络的训练和学习,一度感到十分不便。然而,幸运的是,我发现了Compute Canada——这是一个专为科研和学术研究设计的高性能计算平台,非常适合需要进行大规模计算和数据处理的项目,尤其是神经网络的训练。在本文中,笔者将详细介绍这一计算平台的优势,并提供一些实用的操作指令,希望能帮助身处海外的研究人员有效利用该平台。
优势
-
高性能计算资源:Compute Canada 拥有多个节点,每个节点都配备了多个高性能GPU,这使得它非常适合进行神经网络的训练。这些GPU加速的计算节点可以大大缩短训练时间,提高研究效率。
-
广泛的数据管理选项:该平台提供的数据存储和管理服务确保了数据的安全和易于访问,支持复杂的数据分析任务。用户可以轻松地存储、访问和处理大量数据。
-
全面的软件支持:Compute Canada 提供了广泛的软件库,涵盖从机器学习到数据科学的各种工具,这些工具都是预先配置好的,可以直接使用,极大地方便了用户。
-
专业的技术支持和培训:除了硬件资源,Compute Canada 还拥有一支专业的支持团队,他们为用户解决技术问题提供帮助。此外,平台还定期举办培训和研讨会,帮助用户更好地利用这些资源。
使用方法
要开始使用Compute Canada,你首先需要通过其网站进行注册和申请访问权限。一旦获得批准,你就可以开始配置和运行你的计算作业了。关于该平台,有一份官方出具的详细的Wikipedia说明在该网址,是纯英文的,大家可自行阅读。笔者在这里主要介绍是一些常见的命令和操作,可以帮助你开始使用。
1. 检查模块
不带版本号
在加载任何模块之前,我们需要先确认该模块是否存在于 Compute Canada 平台上。我们可以使用以下命令来查询模块的详细信息。以 Python 和 CUDA 为例:
module spider python
module spider cuda
命令一执行结果:
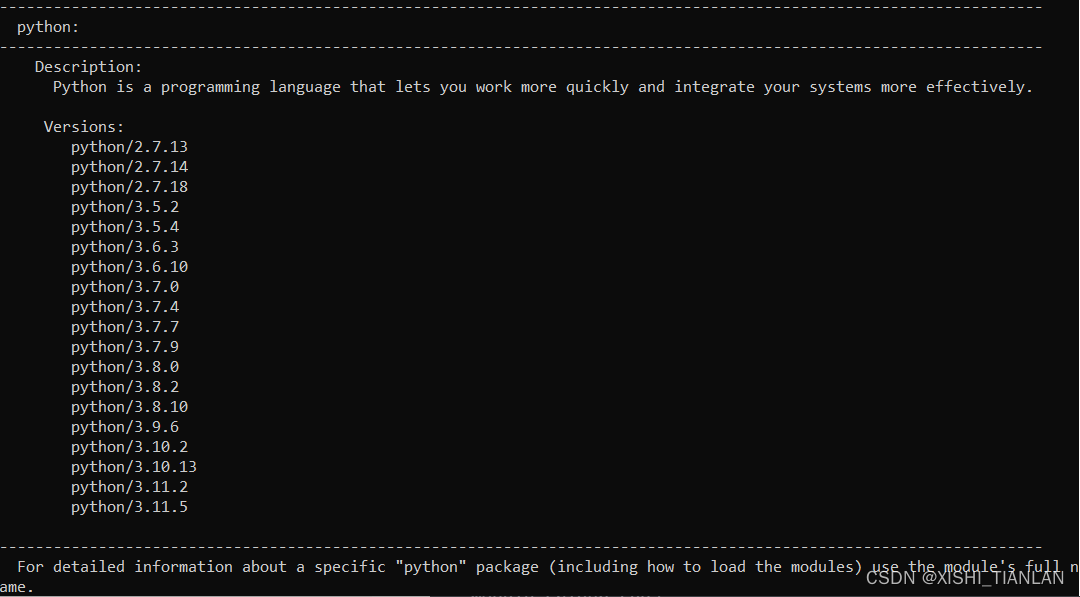
命令二执行结果: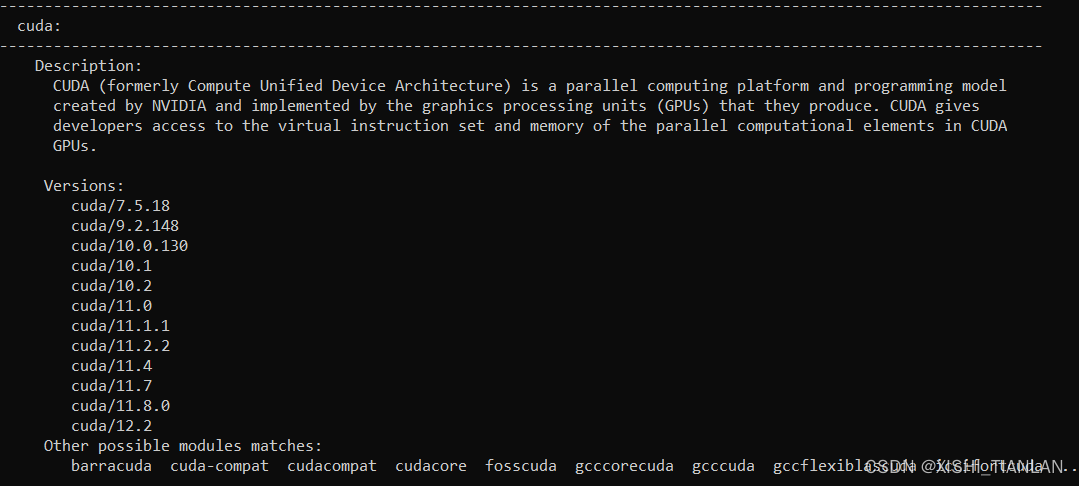
执行上述命令后,你会看到所有可用的模块版本,从中可以选择适合自己的版本进行加载。
带版本号
我们也可以在模块后方加上版本号来进行查询,这样就可以查到我们输入模块的一些安装提示:
module spid 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









