







一、实验内容
编程并实现:
- 写出判断𝑎在模𝑚下是否有逆元,如果有求出逆元的程序。
- 写出求𝑛的欧拉函数值𝜑(𝑛)的程序。
二、实验目标
1. 通过编写逆元求解程序,深入理解数论中的逆元概念,以及如何通过扩展欧几里得算法求解逆元,掌握模运算的基本原理和应用。
2. 通过编写求欧拉函数的程序,掌握如何运用欧拉函数的性质和质因数分解的思想来解决问题,进一步理解数论中的基本函数及其应用场景。
3. 通过这些数论算法的编程实践,提升算法实现能力,加深对数论概念的理解,并掌握相应问题的解决方法。
三、实验原理
(一)问题一原理
2.3节定理4:
设m是一个正整数,a是满足(a, m)=1的整数,则存在整数a',1≤a'<m使得aa'≡1(mod m),其中称a'是(mod m)下a的逆元。
1.3节定理5:
设a, b是任意两个正整数,则存在整数s和t使得:sa+tb=(a, b)。
1.3节定理3:
设a, b, c是三个不全为零的整数。若a=bq+c,其中q是整数,则有(a, b)=(b, c)。
(二)问题二原理
2.3节定理7:
设正整数n有标准因数分解式
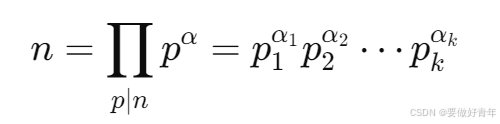
则
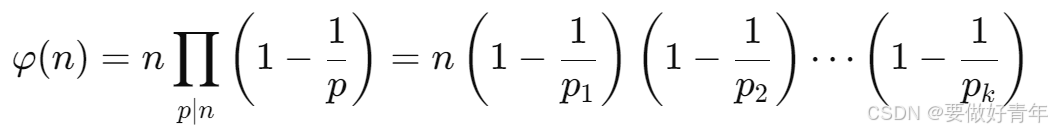
四、实验设计
(一)题1:写出判断𝑎在模𝑚下是否有逆元,如果有求出逆元的程序。
本题的起始思路是由2.3节定理4得来的:设m是一个正整数,a是满足(a, m)=1的整数,则存在整数a',1≤a'<m使得aa'≡1(mod m),其中称a'是(mod m)下a的逆元。
因此,判断a在模m下有无逆元的方法还是很简单的,只要求出(a, m)的值,然后判断它是否为1即可:如果(a, m)=1,则存在逆元;如果(a, m)!=1,则不存在逆元。
那么逆元的值怎么求呢?根据1.3节定理5:设a, b是任意两个正整数,则存在整数s和t使得:sa+tb=(a, b)。由此我们知道,对于a和m,则一定存在整数x和y,使得xa+ym=(a, m)。若a在模m下有逆元,此时(a, m)=1,则有xa+ym=1。对于这个式子,根据同余的定义,也就是ax≡1(mod m)。因此,x即为a的逆元,我们只要求出x,并把它标准化到[0, m)范围内即可。
现在,问题转化为了如何求出(a, m)的值以及使得xa+ym=(a, m)的x。显然,利用广义欧几里得算法和1.3节定理3:设a, b, c是三个不全为零的整数。如果a=bq+c,其中q是整数,则有(a, b)=(b, c),我们可以轻松得到我们需要的值。
接下来,进行编程实现,代码如下:
#include <iostream>
using namespace std;
// 使用广义欧几里得算法计算a和b的最大公因数,并求出x和y使得ax+by=gcd(a,b)
int extended_gcd(int a,int b,int &x,int &y){
if (b==0) {
x=1;
y=0;
return a; // 返回最大公因数
}
int x1, y1;
int gcd=extended_gcd(b,a%b,x1,y1);
x=y1;
y=x1-(a/b)*y1;
return gcd;
}
// 判断a在模m下是否有逆元,并求出逆元
bool modular_inverse(int a,int m,int &inverse){
int x,y;
int gcd=extended_gcd(a,m,x,y);
// 如果gcd(a,m)!=1,则a在模m下没有逆元
if(gcd!=1){
return false;
}
// a在模m下有逆元,计算逆元并将其标准化到[0, m)范围内
inverse=(x%m+m)%m;
return true;
}
int main(){
int a,m;
cout<<"请输入a和m的值:";
cin>>a>>m;
int inverse;
if(modular_inverse(a,m,inverse)){
cout<<"a在模m下的逆元是: "<<inverse<<endl;
}
else{
cout<<"a在模m下没有逆元"<<endl;
}
return 0;
}
我们来解释一下代码。首先,输入a和m的值后,定义逆元inverse,然后进入函数modular_inverse(a,m,inverse)。这个函数是用来判断a在模m下是否有逆元,并求出逆元的。根据modular_inverse()的返回值是ture or false,可以得到对应的输出。
而在modular_inverse()函数中,定义使得xa+ym=(a, m)的x和y,然后使用extended_gcd(a,m,x,y)函数算出a和m的最大公因数gcd。接着进行判断,如果gcd不为1,说明a在模m下没有逆元,直接返回false;如果gcd为1,说明a在模m下有逆元,返回true。然而,算出来的x可能是正数也可能是负数,并且范围也不确定,我们需要把它标准化到[0, m)的范围内。总的操作是inverse=(x%m+m)%m,其分步含义如下:
x%m:这个操作先将x转换成一个在(-m, m)之间的数。如果x是负数,x%m通常会给出一个负的同余结果。
例如,假设x=-3且m=5,则x%m=-3。
x%m+m:这个步骤的目的是确保结果是非负数。我们将x%m加上m,这样无论x%m是什么值,最终结果都会在(0, 2m)之间。
继续上面的例子,x%m+m=-3+5=2。
再次取模(x%m+m)%m:这一步确保结果是一个在[0, m-1]之间的数。如果前面x%m的结果已经是非负数,这个操作不会改变它。如果前面x%m是负数,加上m后,这个操作会确保最终结果在0到m-1之间。
在我们的例子中,(x%m+m)%m=2%5=2。
最终,这个表达式确保了逆元x在[0, m)这个范围内。
接下来,我们来具体看一下extended_gcd()这个函数。

这个函数按照定理3的原理来工作,我们先来解释一下代码。
// 使用广义欧几里得算法计算a和b的最大公因数,并求出x和y使得ax+by=gcd(a,b)
int extended_gcd(int a,int b,int &x,int &y){
if (b==0) {
x=1;
y=0;
return a; // 返回最大公因数
}
int x1, y1;
int gcd=extended_gcd(b,a%b,x1,y1);
x=y1;
y=x1-(a/b)*y1;
return gcd;
}函数接收两个整数a和b,以及两个引用变量x和y,这两个引用变量将用来存储x和y的值(即:ax+by=gcd(a, b)中的x和y)。首先,在传入a和b后,判断此时的b是否为0,这是递归的基线条件。如果为0则表示上一层的余数为0,则此时的a也即上一层的除数就是我们要的最大公因数。同时,要设置x=1,y=0,因为此时a×1+b×0=gcd(a, b)。
如果b不为0,则设置x1,x2后继续递归进入extended_gcd函数求得gcd,函数参数分别为b,a%b,x1,x2。即我们求出b和a%b的最大公因数,并返回相应的x1和y1使得bx1+(a%b)y1=gcd(b, a%b)。
在上面的extended_gcd函数返回后,我们可以通过递归结果更新当前 x 和 y 的值。
我们知道,在递归调用extended_gcd(b, a%b, x1, y1)之后,得到的解满足:
![]()
通过欧几里得算法可以写成:
![]()
整理上式后得到:
![]()
所以,我们可以更新x=y1,y=x1-(a/b)*y1。
至此,函数结束,我们得到了需要的gcd和x。
我们用课上的例子来走一下整个extended_gcd函数的流程。

第一层,a=1859,b=1573≠0,则定义当前层x1,x2后,进入第二层;
第二层,a=1573,b=286≠0,则定义当前层x1,x2后,进入第三层;
第三层,a=286,b=143≠0,则定义当前层x1,x2后,进入第四层;
第四层,a=143,b=0,此时设置x=1,y=0,并返回最大公因数a=143,返回第三层;
第三层,gcd=143,a/b=2,x=y1=0,y=x1-(a/b)*y1=1,返回最大公因数143,返回第二层;
第二层,gcd=143,a/b=5,x=y1=1,y=x1-(a/b)*y1=-5,返回最大公因数143,返回第二层;
第一层,gcd=143,a/b=1,x=y1=-5,y=x1-(a/b)*y1=6 ,返回最大公因数143。
函数结束后我们得到,(1859, 1573)=143,x=-5,y=6使得ax+by=(a, b)。
以上就是题1代码的全部解释。
(二)题2:写出求𝑛的欧拉函数值𝜑(𝑛)的程序。
本题的起始思路是由2.3节定理7得来的:
设正整数n有标准因数分解式
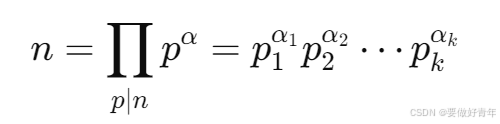
则
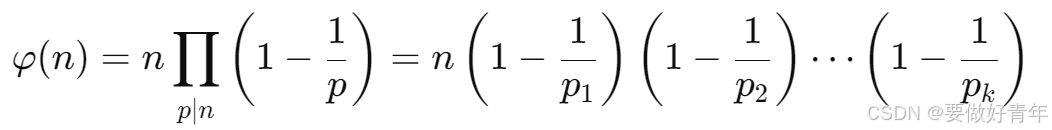
因此,我们的首要目标就是求出n的所有不同的质因数,并且在每次求得一个质因数后,要去除它的所有幂次。因为正整数n有标准因数分解式:
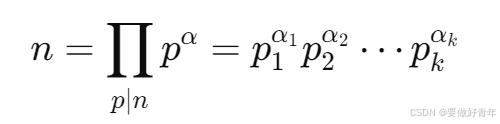
所以当把n中pi的所有幂次都去除以后,才能保证剩下的都是别的质因数的幂次。
而求质因数,只需要从2开始进行循环遍历即可。
进行编程实现,代码如下:
#include <iostream>
using namespace std;
// 求欧拉函数值的函数
int euler_totient(int n) {
int result=n; // 初始值为n
for(int p=2;p*p<=n;p++){
// 如果p是n的质因数
if(n%p==0){
while(n%p==0)
n/=p; // 去除p的所有幂次
result-=result/p; // 根据公式计算欧拉函数
}
}
// 如果n是一个大于sqrt(n)的质数
if(n>1)
result-=result/n;
return result;
}
int main() {
int n;
cout<<"请输入一个正整数n: ";
cin>>n;
cout<<"欧拉函数φ("<<n<<")="<<euler_totient(n)<<endl;
return 0;
}
代码的核心在于euler_totient()函数,它首先定义result变量并赋初值n。然后从2开始遍历质因数p,逐步检测n是否可以被p整除。如果p是n的质因数,先将n中p的所有幂次去掉,再使用公式result=result×(1−1/p)=result−result/p逐步更新欧拉函数值。由于乘法是对称的,如12=2×6=6×2,因此在遍历因子的时候,我们不需要从p=2一直遍历到n,只需要遍历到sqrt(n)即可。
遍历结束后,意味着我们已经处理完所有小于等于sqrt(n)的质因数,这时可能会出现以下两种情况:
- n经过所有质因数的处理后,已经变成了1。这说明n原来的所有质因数已经被完全分解。
- n还剩下一个大于sqrt(n)的质数,这是因为在分解过程中,没有质数能够整除它。这种情况下,说明n自身是一个质数。
例如,对于n=13,所有小于等于sqrt(n)的质数(2和3)都不能整除13,因此经过循环之后,n仍然是13这个质数。
对于第二种情况,如果n在完成循环后仍然是一个大于sqrt(n)的质数,则需要将其本身这个质因数考虑进去。
在代码中,体现为在循环结束后,检查n是否大于1,如果n还大于1,说明n本身是一个质数,并且在循环中没有被分解,要再用公式result=result×(1−1/p)=result−result/p更新欧拉函数值。如果n不大于1,说明n其已经在循环中被分解完毕了,则不用对结果result做进一步处理。
最终,result即为n的欧拉函数的最终值。
五、实验结果
(一)题1:写出判断𝑎在模𝑚下是否有逆元,如果有求出逆元的程序。
输入两个测试样例:a=2、m=7和a=1859、m=1573,程序运行结果如下:


可以看到,结果均正确。
(二)题2:写出求𝑛的欧拉函数值𝜑(𝑛)的程序。
输入两个测试样例:8和13,程序运行结果如下:


可以看到,结果均正确。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









