







 该论文提出一种结合表示学习和多头注意力的新型神经网络方法,用于改进生物医学领域的跨句n元关系抽取。通过知识图谱中的表示学习,模型能学习到实体和关系的先验知识,多头注意力机制则能捕获全局依赖关系。实验表明,这种方法在跨句n元关系抽取中表现出色,特别是在处理长序列和复杂关系时。
该论文提出一种结合表示学习和多头注意力的新型神经网络方法,用于改进生物医学领域的跨句n元关系抽取。通过知识图谱中的表示学习,模型能学习到实体和关系的先验知识,多头注意力机制则能捕获全局依赖关系。实验表明,这种方法在跨句n元关系抽取中表现出色,特别是在处理长序列和复杂关系时。
【论文阅读-BMC Bioinformatics (2020)】Incorporating representation learning and multihead attention to improve biomedical cross-sentence n-ary relation extraction
文章目录
Abstract
背景:要处理跨句的多元关系。现在主流的跨句多元关系抽取方法不仅太依赖语义解析,而且忽略了先验知识
方法:
利用了从知识图中学习到的多头注意和知识表示。
1)自注意力机制(可以直接捕捉两个词之间的关系,而不考虑它们的句法关系)
2)利用知识库中的实体和关系信息(帮助预测)
结果:
1、直接对序列进行操作
2、 并学习如何对句子的内部结构进行建模。
3、我们将从知识图中学习到的知识表示引入到跨句n元关系抽取中。基于知识表示学习的实验表明,在知识图中可以提取出实体和关系,编码这些知识可以提供一致的收益。
Background
Binary relation
1、rule-based method
基于规则的方法主要利用语言学家设计的句法规则从文档中提取实体之间的关系。随着跨句文档长度的增长,人工设计的语言规则的使用变得复杂且效率低下[7]。
2、machine learning-basedmethod
神经网络在基于机器学习的方法中占主导地位。神经网络不需要人工设计特性,而且性能非常好。
CNN
CNN(CNN通过卷积核学习序列局部特征。)
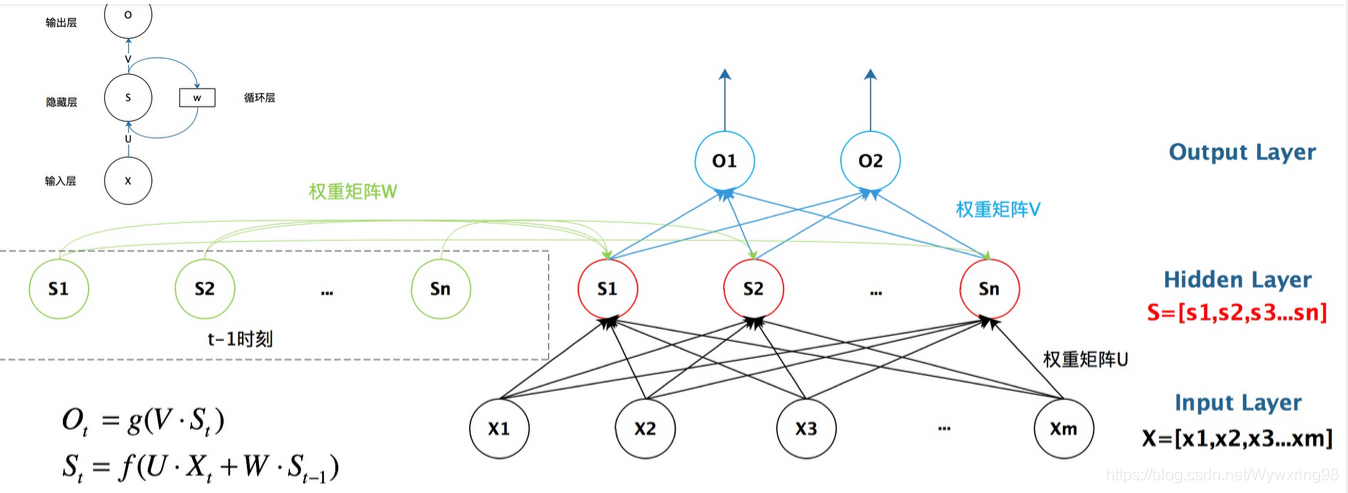
RNN
RNN(RNN是一种线性神经网络,是处理序列特征的理想方法。与CNN相比,大多数生物医学关系提取方法以RNN为主要框架。)
RNN的局限性:1)随着序列长度的增长,需要强大的存储能力来保存长序列的完整信息。2)它很难处理树状结构文档,忽略了词的依赖关系。
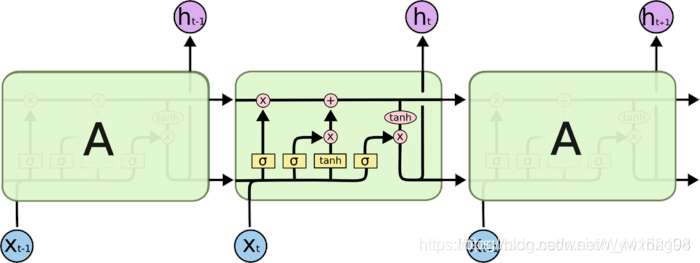
LSTM
 >
>n-ary relation
例:(The deletion mutation on exon 19) of the( EGFR gene) was present in 16 patients, while (the L858E point mutation on exon 21) was noted in 10. All patients were treated with (gefitinib )and showed a partial response.。显示出基因、突变、药物 的关系。
LSTM’s variants
Tree LSTM(解决第二个问题:树LSTM中的隐藏层单元不仅包含前一个序列信息&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









