 Kafka学习:原理、架构与生产消费过程
Kafka学习:原理、架构与生产消费过程




 本文是Kafka学习笔记,介绍了Kafka消息队列内部实现原理,消费者获取数据有“pull”和“push”两种模式,说明了使用消息队列的好处。还阐述了Kafka架构特点,分析了生产过程的分区原则、写入流程及ACK应答机制,以及消费过程等内容。
本文是Kafka学习笔记,介绍了Kafka消息队列内部实现原理,消费者获取数据有“pull”和“push”两种模式,说明了使用消息队列的好处。还阐述了Kafka架构特点,分析了生产过程的分区原则、写入流程及ACK应答机制,以及消费过程等内容。
Kafka学习笔记(一)
2019.07.11
1. Kafka消息队列内部实现原理
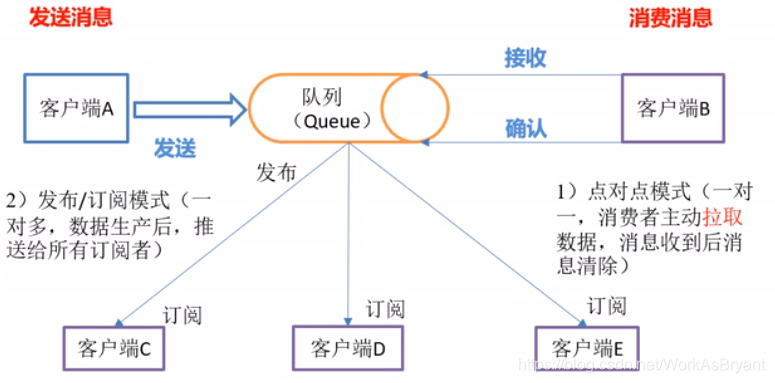
消费者可通过两种模式获取数据,一种是“pull”,主动拉取数据;一种是"push",将数据推送给所有订阅者。
第一种方式的缺点是需要实时监控数据有没有更新。
为什么需要消息队列?
- 解耦;
- 冗余;
- 扩展(集群的扩展性);
- 灵活性&峰值处理能力;
- 可恢复性;
- 顺序保证;
- 缓冲。
无论是Kafka集群,还是comsumer都依赖于zookeeper集群保存一下meta(例如当前consumer消费到的offset)信息。(producer不依赖zookeeper集群)
2. Kafka架构
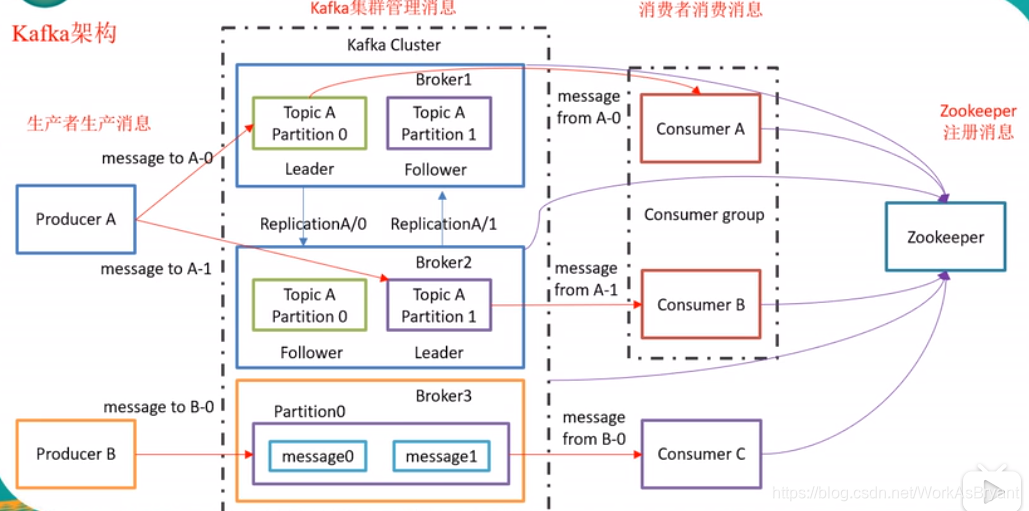
1. 副本(follower)是不会对客户端请求进行响应的,只做备份(与zookeeper的leader、follower有所不同);
2. 同一个组的消费者不能消费同一个分区的数据;
3. Kafka缓存的数据是要落盘的;
4. Kafka副本数不能超过集群中节点数目;
5. 新版Kafka将offset信息维护在Kafka集群,而不用维护在zookeeper集群,这样可以提高效率。例如在启动console consumer时有一个参数是--bootstrap-server,在老版本里用的是--zookeeper-server,--bootstrap-server指定的是Kafka集群
3. Kafka生产过程分析
分区的原则:

副本:

producer写入流程:
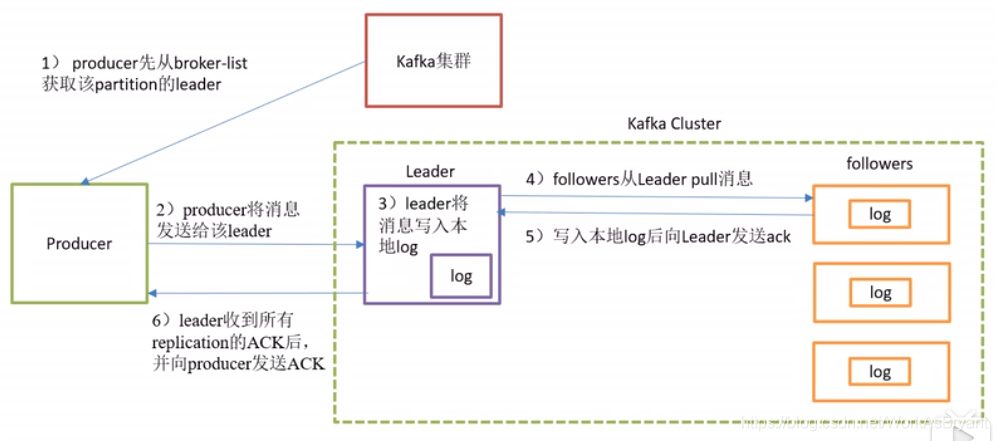
上述写入流程ACK应答机制取得值是ALL,也就是leader和follower全部都写完再向producer发送ACK信息(ACK还可取值为0或1)。文字总结如下:

4. Broker保存消息

5. Kafka消费过程分析

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









