




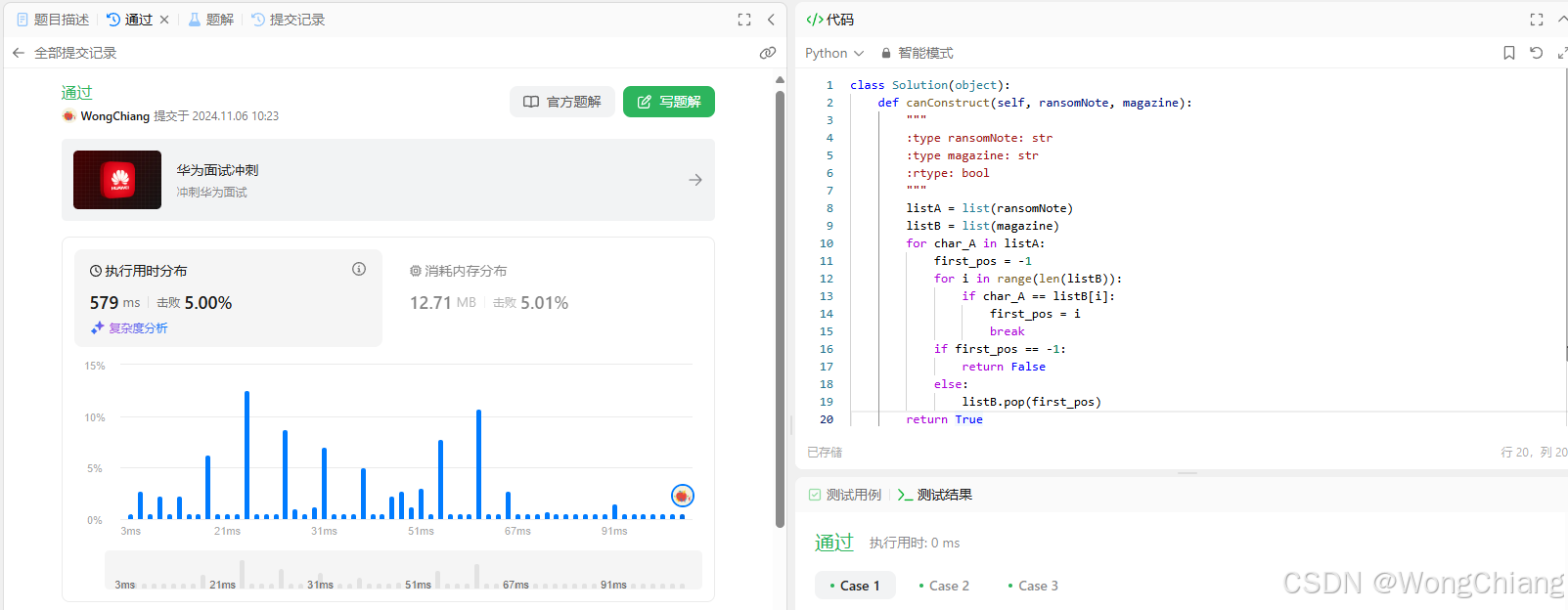
任务一:Leetcode 383(笔记中提交代码与leetcode提交通过截图)
暴力遍历:
class Solution(object):
def canConstruct(self, ransomNote, magazine):
"""
:type ransomNote: str
:type magazine: str
:rtype: bool
"""
listA = list(ransomNote)
listB = list(magazine)
for char_A in listA:
first_pos = -1
for i in range(len(listB)):
if char_A == listB[i]:
first_pos = i
break
if first_pos == -1:
return False
else:
listB.pop(first_pos)
return True
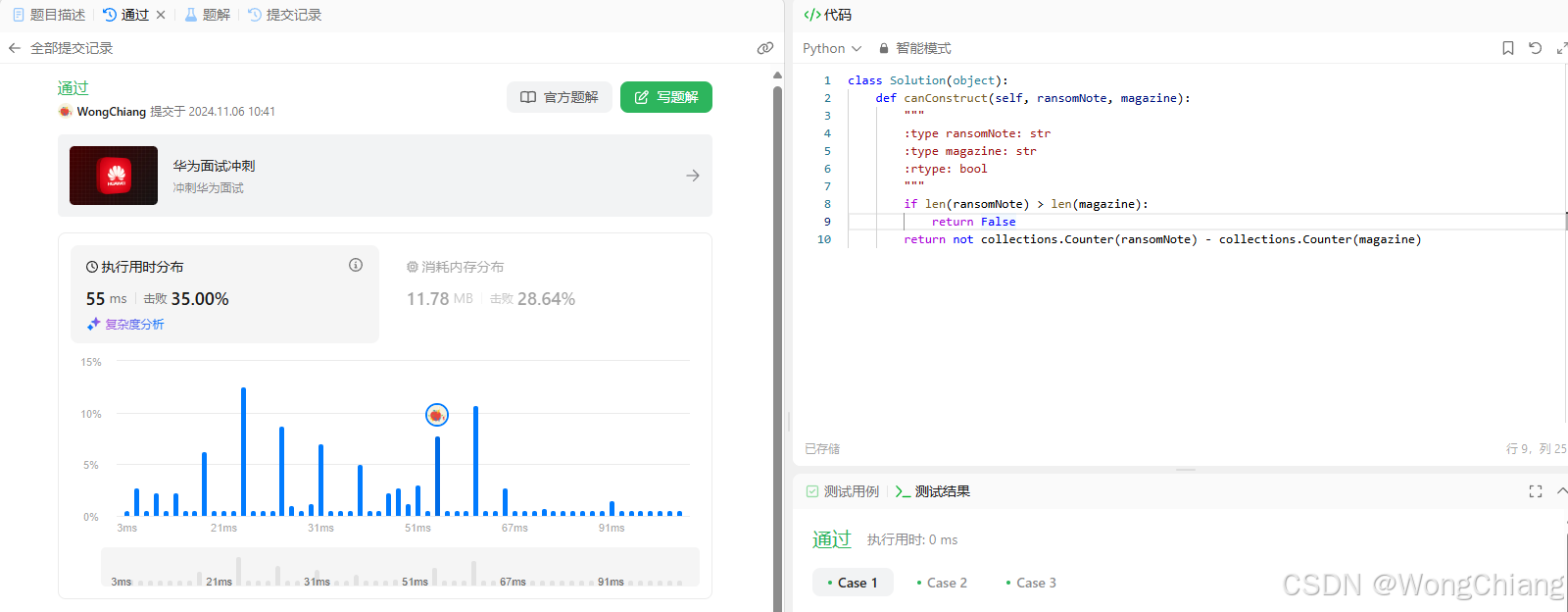
使用collections.Counter哈希表:
代码:
class Solution(object):
def canConstruct(self, ransomNote, magazine):
"""
:type ransomNote: str
:type magazine: str
:rtype: bool
"""
if len(ransomNote) > len(magazine):
return False
return not collections.Counter(ransomNote) - collections.Counter(magazine)
任务二:请使用本地vscode连接远程开发机,将上面你写的wordcount函数在开发机上进行debug,体验debug的全流程,并完成一份debug笔记(需要截图)。
下面是一段调用书生浦语API实现将非结构化文本转化成结构化json的例子,其中有一个小bug会导致报错。请大家自行通过debug功能定位到报错原因并做修正。
注意:
提交代码时切记删除自己的api_key! 本段demo为了方便大家使用debug所以将api_key明文写在代码中,这是一种极其不可取的行为!
作业提交时需要有debug过程的图文笔记,以及修改过后的代码。
from openai import OpenAI
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_json = json.loads(res)
print(res_json)
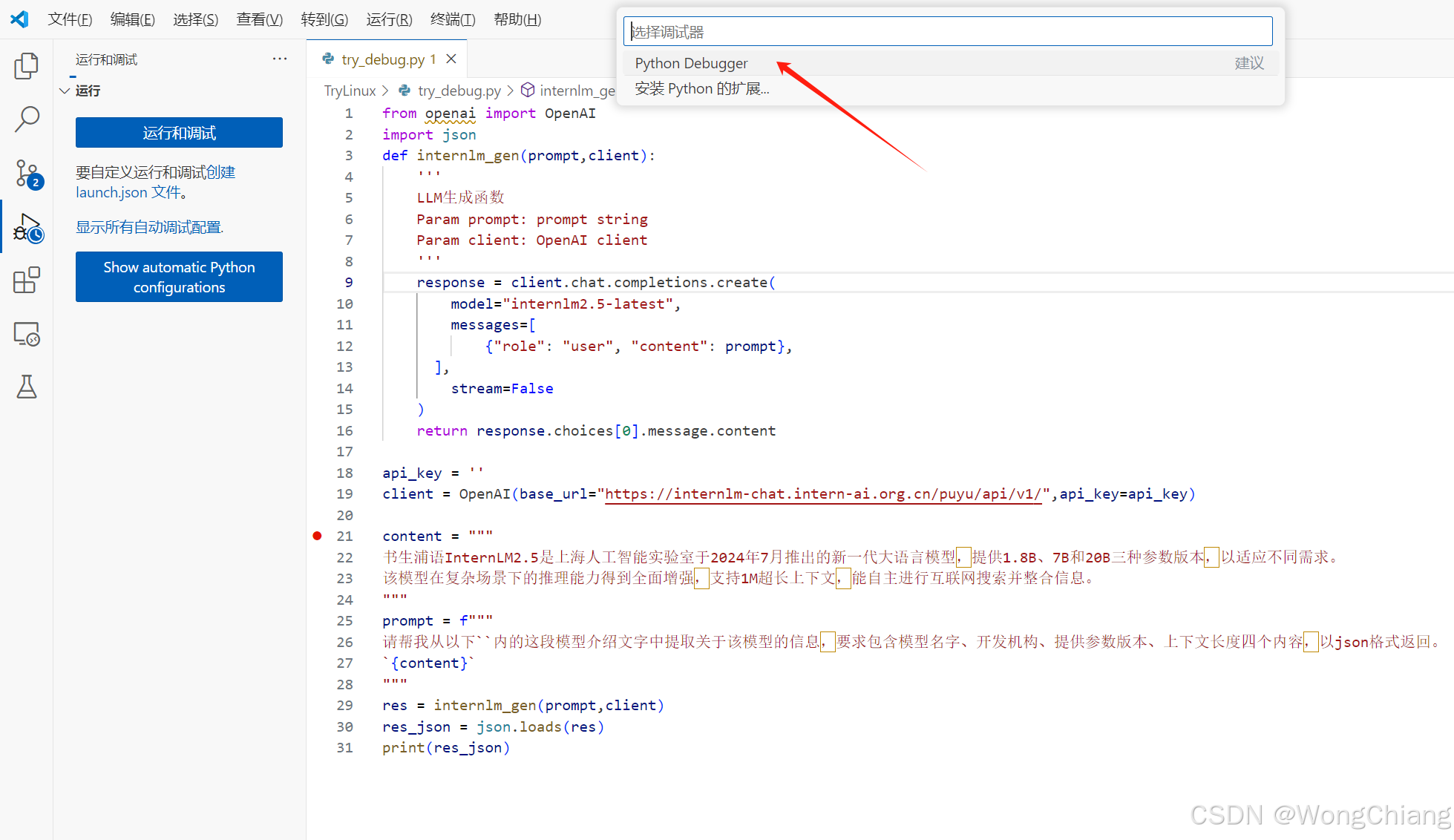
Step1
直接运行发现抱错,打断点在client后,看看这个client能否成功创建
Python Debugger直接选本地文献,如果经常要调试可以加一个launch.json配置文件
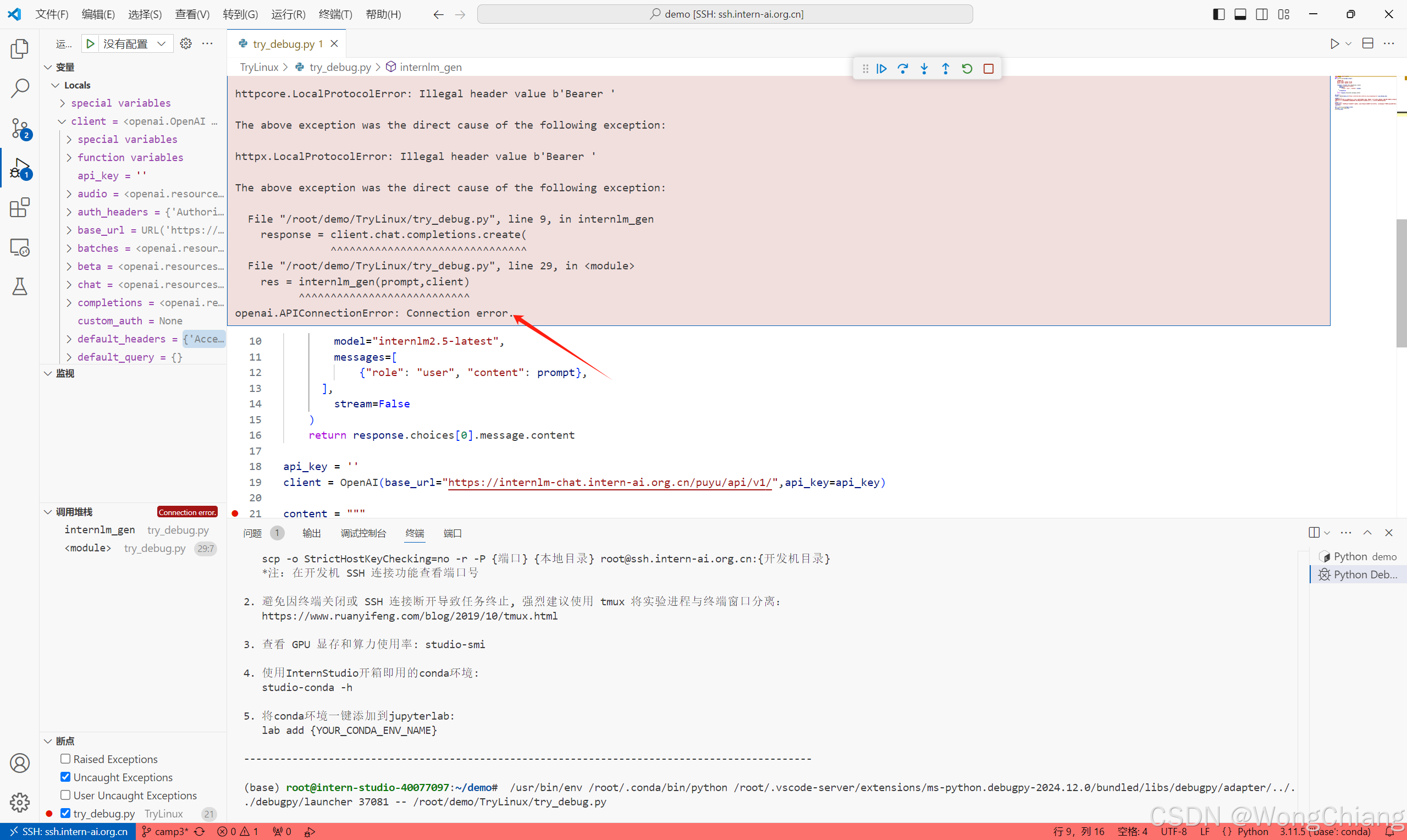
Step 2
断点后单步运行,发现是internlm_gen方法报错Connection Error,注意到这里api-key是空的,应该是需要一个api-key
去浦语官网:https://internlm-chat.intern-ai.org.cn
登陆后可以申请一个api-key,图里的api-key只有一半,注意保护自己的
Step 3
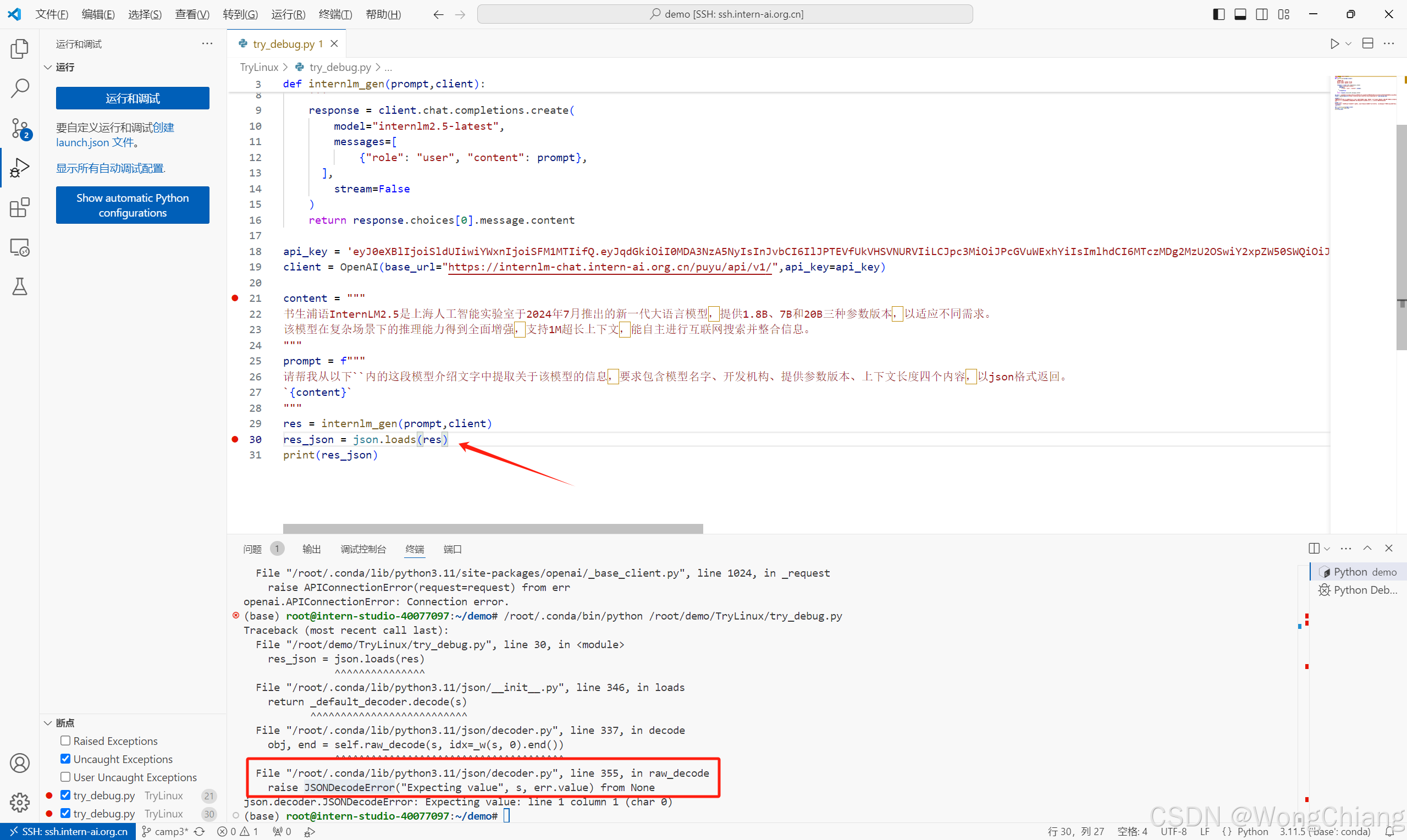
json解析报错,这里调试看一下传给loads方法的内容res
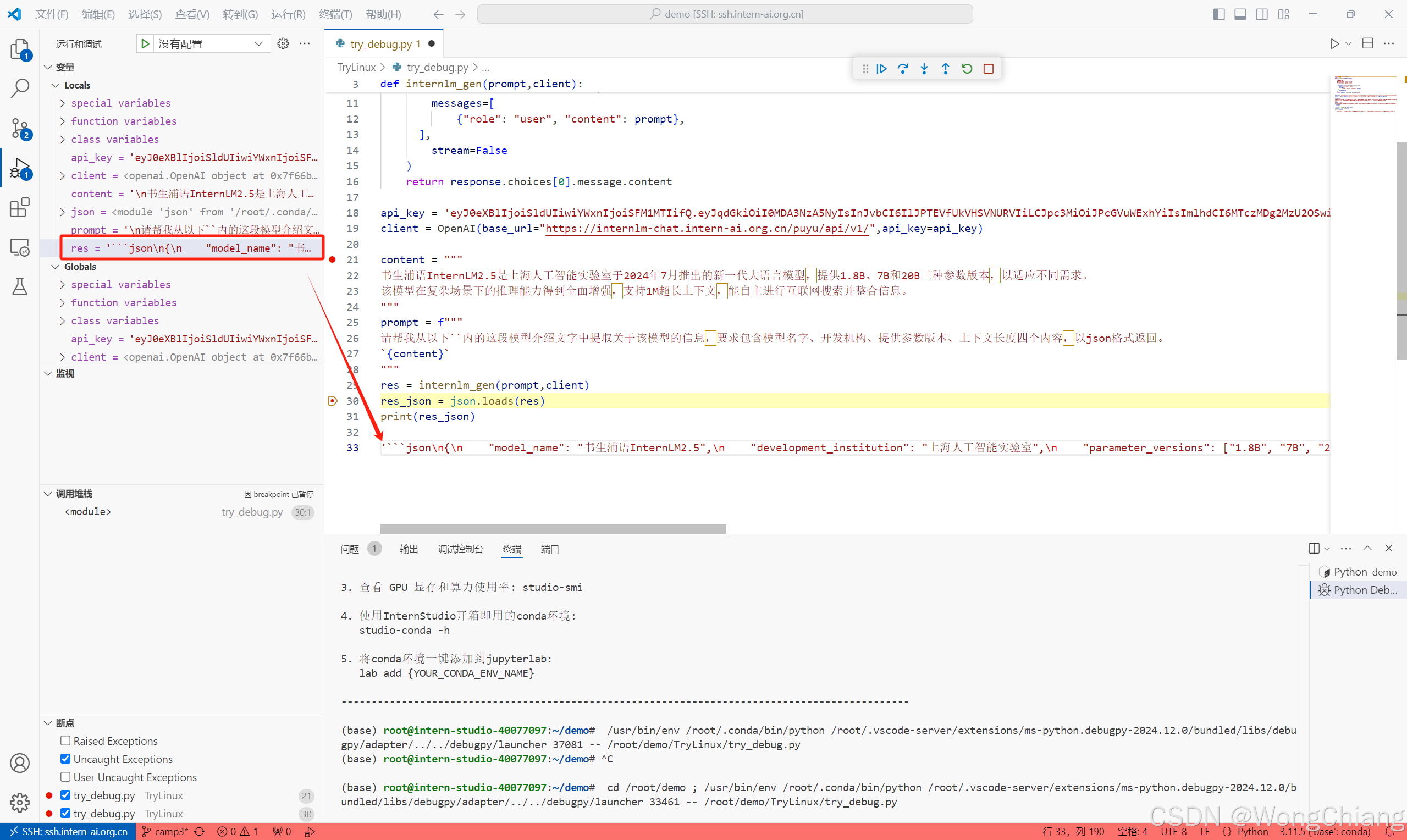
发现是markdown格式的字符串,可以直接print这个字符串就可以输出模型的回复了
Step 4
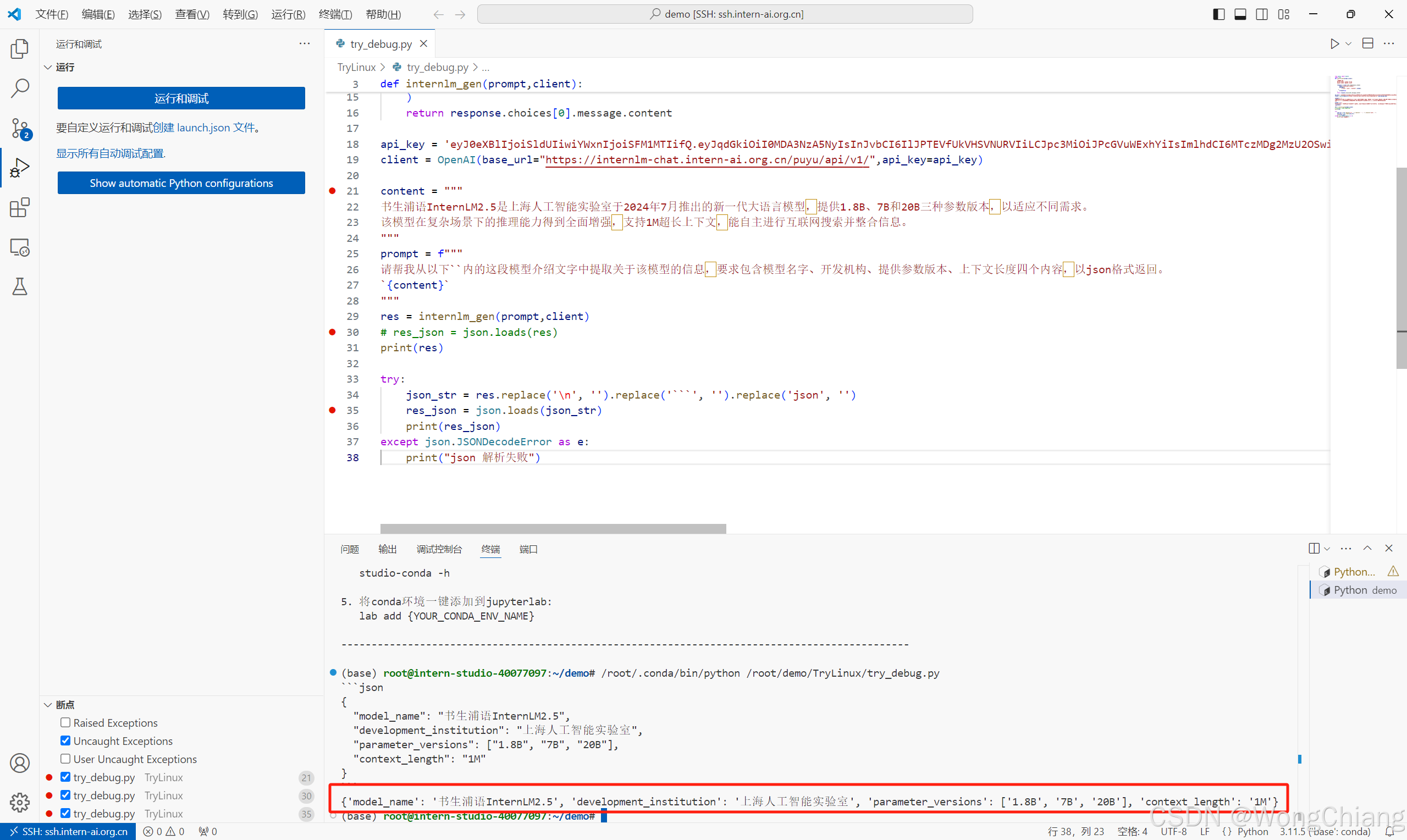
这里针对该case简单加一个try-catch对过滤掉部分markdown字符的string进行解析,如果要功能更全面的话应该仔细斟酌过滤的规则
这样就可以获取到json格式的模型参数了
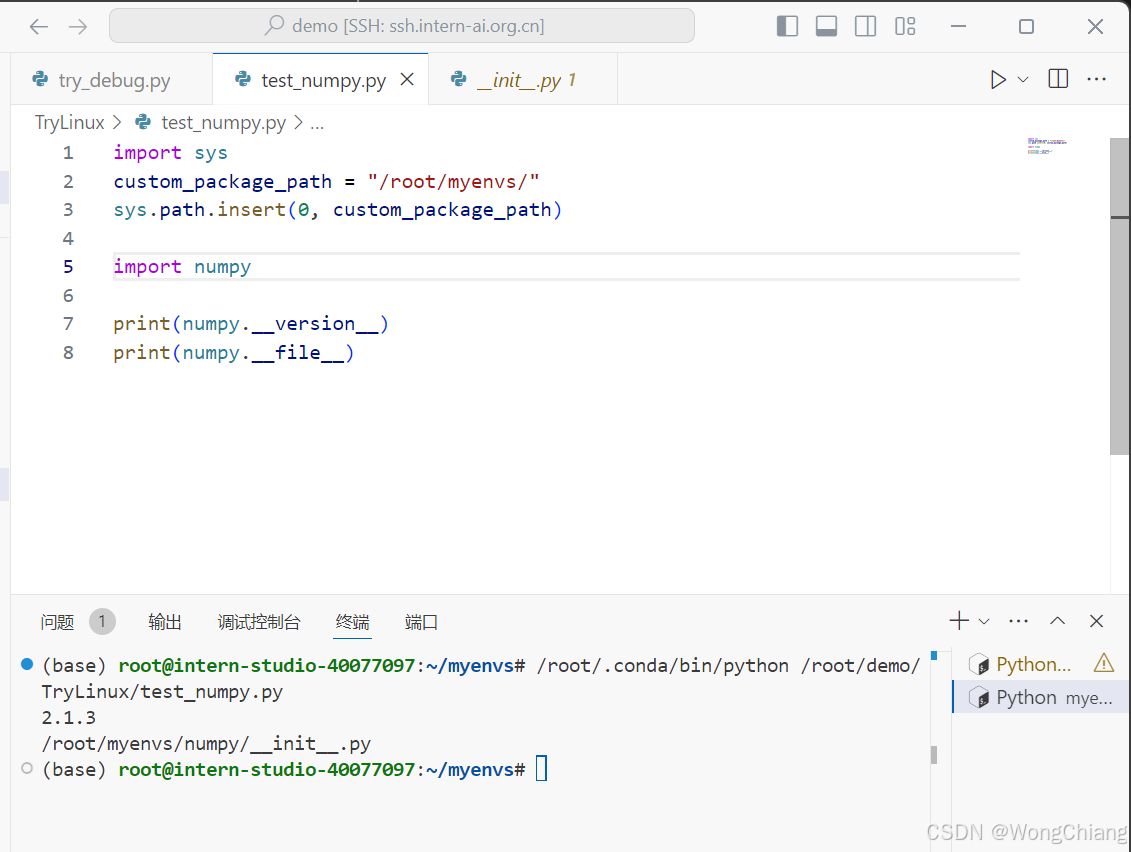
任务三(可选):使用VScode连接开发机后使用pip install -t命令安装一个numpy到看开发机/root/myenvs目录下,并成功在一个新建的python文件中引用。
安装命令:
pip install -t /root/myenvs numpy
使用:

















 1910
1910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









