




最近自己玩爬虫玩得很嗨。想到爬QQ空间主要是因为在看网课的时候有不少人刷弹幕要去爬前女友空间。。咳咳,虽然我没有前女友,但是这不失为一个有趣的练手机会。(爬完之后发现不会留下访客记录!确实很适合爬前女友空间hh)写这篇博客主要是想捋一捋思路。
目标
爬取QQ好友的说说内容,保存到文件,分析词频生成词云。
1.登录网页版QQ
首先进入QQ空间网页版,我们需要先登录进入自己的空间。这个时候就用selenium来模拟人的操作。具体来说就是先点击“账号密码登录”,定位账号、密码输入框并输入相应内容,定位登录按钮,点击登录。
要注意的是这个页面是有框架的,在源码里可以看到"login_frame",所以要先切换到框架。
def login():
# 无头浏览器的写法
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# driver = webdriver.Chrome(options=chrome_options)
driver = webdriver.Chrome()
driver.get(login_url)
driver.switch_to.frame('login_frame')
#切换到账号密码登录
log_method = driver.find_element_by_id('switcher_plogin')
log_method.click()
#输入账号密码,登录
account_input = driver.find_element_by_id('u')
account_input.send_keys(account)
password_input = driver.find_element_by_id('p')
password_input.send_keys(password)
login_button = driver.find_element_by_id('login_button')
login_button.click()
time.sleep(5)
driver.switch_to.default_content()
return driver
这个还是很容易实现的。我没有用无头浏览器,因为还可以看一看自己有没有被验证码卡住hh,被卡住的话后续会抛出异常。
2.目标站点分析
然后我就选择了一个好友的空间进入,看“说说”界面的源代码,会发现源代码里面没有半点“说说”的内容,这个时候就要抓包、不能直接上了。
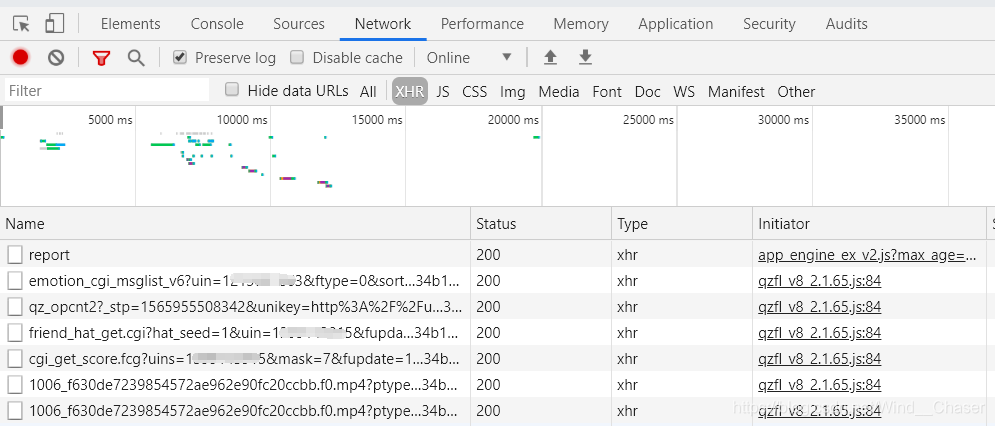
可以看到有这么些东西,点开一个查看Headers(下面这个是打开了emotion_cgi_msglist_v6?uin=…),可以复制Request URL到浏览器里看一看内容,可以看到有好友说说的内容。说明我们应该是请求这个url来获取说说内容。
接下来分析这个url,有几个参数我们要注意。一个是uin,后面很明显接的是好友的QQ号。所以我们可以先获取一个好友QQ号的列表,之后作为参数传进来。第二个是pos,后面接的是页码,要爬取多页的内容就可以控制它来翻页。然后是g_tk,这个参数有两处,它是一个经过加密生成的随机串(你会发现不同时候打开的值是不同的),通过cookie可以获取加密后的g_tk,这里直接搬运的大佬的方法。最后是qzonetoken,这个是在登录页面里面获取的,具体怎么也不是很懂,直接搬运了。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









