




 本文介绍了XML相关知识,包括其是可扩展标记语言,用于传输数据,可作框架配置文件。阐述了XML语法,如创建文档、元素定义、命名规则和语法规则等。还介绍了XML解析技术,如DOM、SAX,重点讲解了dom4j和XPath解析方法。
本文介绍了XML相关知识,包括其是可扩展标记语言,用于传输数据,可作框架配置文件。阐述了XML语法,如创建文档、元素定义、命名规则和语法规则等。还介绍了XML解析技术,如DOM、SAX,重点讲解了dom4j和XPath解析方法。
XML
XML简介
什么是XML?
XML(Extensible Markup Language)是一种可扩展标记语言,类似于HTML
PS:可扩展:标签可以自定义,XML标签没有被预定义,需要用户自行定定义标签
2.XML技术是W3C【万维网联盟 World Wide Web】组成提供,如前依旧遵守W3C组织于2000年发布的规范XML1.0规范
3.HTML:显示页面网页使用,需要学习你不标签
4.XML:传输数据【数据的量级较少】,而不是显示显示数据使用,并且XML在一些框架中可以作为配置文件存在。
XML语法
1.如何创建XML文档
1.创建一个xml文件–>选择项目功能内的某个文件夹,然后鼠标右键—》new —》 File —》 创建一个文件的名字,并使用文件名字的后缀【.xml】
2.对XML文件进行他编写
<?xml version="1.0" encoding="UTF-8"?>
<!--XML文件和HTML类似所以遵守HTML的注释-->
<!--
<?xml version="1.0" encoding="UTF-8"?>
相当于是XML 文件声明
属性:
version 代表版本号
encoding 是xml文件编码
standalone = "yes/no" 表示这个xml文件是独立的xml文件
XML中是没有定义标签,所以这里的标签随便定义,但是要遵守命名规则
标签要成对出现,在所有表的最外部,这对标签被称为 【根标签】
-->
<books>
<book id="SN1231234123456"><!--可以对标签添添加属性-->
<!--这些标签都是自定义,在标签与标签之间存在的数据就是XML文件中存储的数据-->
<name>Java编程思想</name>
<author>老外</author>
<price>9.9</price>
</book>
<book id="SN1231234123456"><!--可以对标签添添加属性-->
<!--这些标签都是自定义,在标签与标签之间存在的数据就是XML文件中存储的数据-->
<name>数据库从入门到放弃</name>
<author>中国</author>
<price>11111.1</price>
</book>
</books>
3.XML文件和HTML文件类似,HTML文件可以在浏览器展示,XML文件是够可以在浏览器中展示?
可以在浏览器中展示并验证,但是不能通过浏览器进行修改
XML注释和HTML是一样的,并且使用HTML类似的标签
语法:
<自定义标签名 可以对标签添加属性>要封装的数据</自定义标签名>
PS:XML页写单标签 <标签名/> 但是不建议,建议写双标签
标签名大小写不敏感,标签的属性【基本数据和事件属性】
标签一定要闭合,【在HTML中不会报错,但是在XML中不要这样】
什么是XML的元素
XML元素是指从(且包含)开始标签直到(且包含)结束标签的部分,元素可以包含其他元素、文本或者两者的混合,元素可以拥有自己的属性
PS:XML文件,编写的时候必须有一个 【根标签】,根标签的范围就是开始和结束
XML属于一个标签语言,只要标签范围内产生的数据,都是元素
例如
<books>
<book id="SN1231234123456"><!--可以对标签添添加属性-->
<!--这些标签都是自定义,在标签与标签之间存在的数据就是XML文件中存储的数据-->
<name>Java编程思想</name>
<author>老外</author>
<price>9.9</price>
</book>
<book id="SN1231234123456"><!--可以对标签添添加属性-->
<!--这些标签都是自定义,在标签与标签之间存在的数据就是XML文件中存储的数据-->
<names>数据库从入门到放弃</names>
<author>中国</author>
<price>11111.1</price>
</book>
</books>
PS: 对于books这个标签而言,book这个标签就是其拥有的元素
book而言 name author price都是他的元素
name也是标签,但是name有元素码?
因为name中并无其他标签,但是有一些文本内容,这里就可以称为标签中存储了数据
PS: 元素其实可以理解为时标签, 元素就范围为 Element
XML命名规则
XML元素【标签】必须遵守以下命名规则
1.见名知意,名称可以包含字母和数字以及其他字符【但是建议使用英文单词(不要写拼音)】
2.名称不能以数字或标点符号开头【写单词】
3.名称不能以【XML或xml 或Xml】开头
4.名称不能包含空格
xml中的元素(标签)也单标签和双标签,无论单双都可以支持属性
单标签
<标签名 属性=“值” 属性=“值”..../>
双标签【推荐】
<标签名 属性=“值” 属性=“值”....>数据或子标签</标签名>
XML的属性和HTML中属性类似,可以对标签提供额外信息,XML中属性必须使用引号【“ ”】引起来
PS:HTML中属性是对标签形式提供,XML中的属性是提供数据使用
XML语法规则
1.所有XML(标签)元素都必须是闭合
2.XML标签需要应对大小写敏感
3.XML必须是正确的嵌套
正确形式:
<books>
<book id="SN1231234123456">
<name>Java编程思想</name>
<author>老外</author>
<price>9.9</price>
</book>
</books>
错误形式:
<books>
<book id="SN1231234123456">
<name>Java编程思想</name>
<author>老外</author>
<!--这样做就是一个错误嵌套,原因在于price位置是不对-->
<price>9.9
</book>
</price>
</books>
4.XML文档中必须有根标签(元素)
PS:根元素就是顶级元素,没有父类的元素,就叫做顶级元素
根元素是没有父类标签(元素),所以他是唯一的
<books>
<book id="SN1231234123456">
<name>Java编程思想</name>
<author>老外</author>
<price>9.9</price>
</book>
</books>
PS: books这个标签就是根比标签即根元素
book就是books的子标签即子元素
name就是book的字标签 即book是name的父标签
name、author、price 他们三个是 兄弟标签【平级标签】
5.XML的属性必须添加值必须引号
6.XML中的特殊字符
在标签存数据的位置,是允许引入特殊字符【HTML特殊符号】
<books>
<book id="SN1231234123456">
<name>Java编程思想</name>
<!--对数据添加了特殊符号 < < 小于 > > 大于-->
<author><老外></author>
<price>9.9</price>
</book>
</books>
7.文本区域(CDATA区)
CDATA语法可以告诉XML解析器,我CDATA里的文本内容,只是纯文本必须要xml语法解析
CDATA格式
<![CDATA[这里可以把你输入的字符原样输出,不会解析XML]]>
在标签存数据的位置,是允许引入特殊字符【HTML特殊符号】
<books>
<book id="SN1231234123456">
<name>Java编程思想</name>
<![CDATA[我是就是一个纯文本]]> <!--这里的操作不会进行解析就是纯文本-->
<author>老外</author>
<price>9.9</price>
</book>
</books>
XML文件解析(dom4j)
1.xml解析技术介绍
XML是可扩展标标记语言,不管是html还是xml文件它们都是标记型文档,都是使用w3c组织指定的dom技术来进行解析
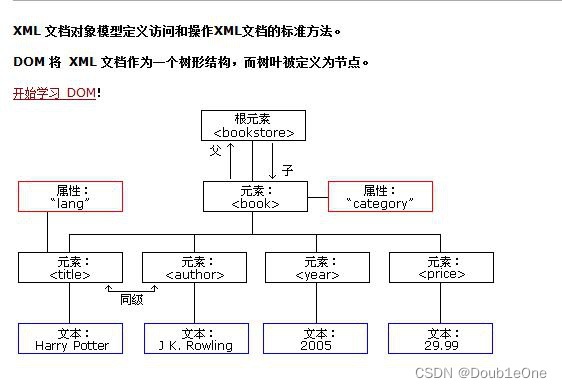
早期的JDK为了我们提供了两种xml解析技术DOM解析和SAX解析【已经过时,我们知道就可以】
dom解析是现阶段使用比较广泛的解析方式,它是W3C组织定义
DOM:【Document Object Model】文档对象模型,把文档中成员描述成一个一个对象【一个标签就是一个对象】
PS:Java本身就对dom解析进行了实现
sun公司在JDK5时候对dom解析技术进行了升级SAX(Simple API for XML)
SAX解析,它W3C指定解析不太一样,他是以,类似事件机制通信回调以告诉用户正在解析内容
【它是一行一行的读取XML文件进行解析,并且不会创建大量dom对象】
所以它在解析XML的时候,在内存的使用上和性能上,都由于DOM解析
在实际开发中我们需要一种简便速度快并且还是文档解析形式的工具来解析XML文件
最开始的时候有一个三方插件jdom是在原有dom解析的方式上进行了封装和优化,dom4j又对jdom进行二次封装和优化,所以现在解析XML文档都是在使用dom4j这个手段在解析
dom4j介绍和使用
简介:
DOM4J(DOM for Java),当初设计DOM这个帮人,出去之后又搞出的一个新项目DOM4J,相当于原始的DOM而言,原理是一样,但是简便性和性能都高于原有DOM
PS:DOM4J在JavaEE中的框架级别使用比较频繁,因为框架都会使用XML作自身的配置文件
使用:
1.找到dom4j-1.6.1.jar包,添加到工程中,将jar包加载到工程
2.DOM是一个文档对象模型所以宗旨就是以文档对象来存标签内容,即和【ORM映射是一个道理】
步骤1:需要创建一个实体类,这个实体类用来存储数据【XML】
//对象文档的封装
public class Book {
//书名
private String name;
//作者
private String author;
//价钱
private double price;
public Book(){}
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.ArrayList;
import java.util.List;
public class TestDomParseXML {
public static void main(String[] args) throws DocumentException {
//1.需要先创建一个Document对象,就需要使用到DOM4J找那个一个类SAXReader
SAXReader saxReader = new SAXReader();
//2.使用这个reader对象读取xml文件,返回一个Document对象
//参数是一个文件文件
Document document = saxReader.read("XMLFile/Book.xml");
//3.Document对象已经拿到了XML文件根元素对象
Element rootElement = document.getRootElement();
//这里可以看一下根节点是什么,以便验证是否正确 asXML方法可以将元素转换为String对象
//System.out.println(rootElement.asXML());
//4.通过根节点获取book标签对象,返回结果值是一个List集合
//为什么是集合,原因在于,不能确定子标签一共有多少个,List集合即可以存1个也可以存储多个
//这个返回值的List集合是没有泛型的,建议使用Dom4j中提供Element作为泛型存在
//原因在于:每一个标签就是一个元素,所以就可以把标签看做时元素,所Element就是代表元素的意思
List<Element> books = rootElement.elements("book");
//再次验证 集合中存储方数据是否争取,是够可以获取
// for(Element book : books){
// System.out.println(book.asXML());
// }
//获取存在book标签下子标签的值,因为子标签没有在嵌套的标签了,所以直接获取元素的值
List<Book> list = new ArrayList<>();
for(Element book : books){
//拿到book下面name元素的对象【相当于是值】
//这个返回时一个Element对象
Element name = book.element("name");
Element author = book.element("author");
Element price = book.element("price");
//通过Element对象的getText方法将会对象转变为String类型
Book b = new Book(name.getText(),author.getText(),Double.parseDouble(price.getText()));
list.add(b);
}
list.forEach(System.out::println);
}
}
XPath解析
dom4j需要遍历标签后才能获取对应标签的值,如果XML文件中的标签过多使用dom4j操作起来就比较麻烦了,此时可以使用类似于路径解析的方式直接获取对应值
XPath是在XML文档中查找信息的语言
XPath通过元素和属性进行查找,简化了Dom4j查找节点的过程,是w3c组织发布的标准
使用XPath必须导入 jaxen-1.1-beta-6.jar 包
两个核心方法:
selectSingleNode(“路径”) 获取单个值
selectNodes(“路径”)获取多个值
可以查看XPathTutorial(菜鸟必备).chm文档里面有路径说明
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.util.List;
/**
* XPath形式
*/
public class XPathParesXML {
public static void main(String[] args) throws DocumentException {
//1.需要先获取Document对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read("XMLFile/book.xml");
//2.XPath只要是有路径就可以拿到节点值
//1.获取单个节点值 返回的值是一个节点对象,但是这个Node不好操作
//所以建议转换为Element对象
Element element = (Element)document.selectSingleNode("/books/book[@id='SN1231234123456']");
//2.获取book节点下的数据
String name = element.elementText("name");
String author = element.elementText("author");
double price = Double.parseDouble(element.elementText("price"));
Book book = new Book(name,author,price);
System.out.println(book);
//3.多个节点获取
List<Element> list = document.selectNodes("/books/book");
for(Element e : list){
System.out.println(e.elementText("name"));
}
}
}


















 3066
3066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









