






引言
AI 的出现大大降低了软件开发的门槛,一个之前完全不懂编程技术的小白,都可以借助 AI 快速实现一款应用,那有点编程经验的程序员,岂不是可以复刻 APP 工厂了?在短短的三小时,成功上线了一款专注于个人目标管理的微信小程序。上线首周即突破日活跃用户上万量级,验证了产品设计的市场契合度与用户需求痛点。

一、目标背景与设计初衷
在快节奏的现代生活中,个人目标管理面临两大核心痛点:
- 规划断层:用户设定"考取职业证书"等长期目标时,难以自主拆解出科学的阶段性任务路径
- 执行脱轨:传统任务管理工具仅提供清单记录,缺乏动态调整能力和资源支持
为此,我们开发了一款基于微信生态的智能目标管理系统
一款专注于个人目标管理和任务追踪的微信小程序。它允许用户创建、编辑和管理长期目标,将目标分解为可执行的任务,并通过直观的界面跟踪进度以及支持无限层级子任务。该应用还提供AI辅助功能,可以根据用户设定的目标通过Bright Data 的 Web Unlocker自动生成相关任务以及建议,帮助用户更有效地规划和执行。

二、项目实现
1. 系统核心功能设计
- 无限层级任务树:采用改进型邻接表结构,支持无限层级任务嵌套
- 进度感知引擎:通过倒数日,任务计时,时间统计来提醒用户
- AI任务生成器:基于Bright Data 的 Web Unlocker自动创建关联子任务
Step 1. 服务配置
初次使用需访问Bright Data官网完成账号注册,登录后进入控制面板的「代理与爬取工具」模块。点击顶部导航栏的「+添加产品」按钮,从产品列表中选择「Web Unlocker」服务。此时系统会提示进行实例命名,
在域名配置环节,平台提供两种模式:针对特定域名的定向模式适用于垂直领域数据采集,而选择「全局适用」模式则允许通过同一代理接口访问任意网站,这对需要跨平台采集的场景更为高效。值得注意的是,启用全局模式后仍需遵守目标网站的Robots协议,Bright Data会通过智能流量过滤系统自动规避高风险请求。

完成基础配置后,系统将生成专属的代理接入凭证,包含三组关键参数:
代理服务器地址(格式:gate.weblocker.io:端口号)
授权用户名(由系统自动分配的32位哈希字符串)
动态密码(支持定期轮换的安全验证机制)
这些凭证既可通过标准HTTPS代理协议直接调用,也可集成到Python/Node.js等语言的SDK中。平台文档库提供十余种编程语言的代码示例,其中Python请求示例展示了如何设置会话重试策略与超时阈值,这对处理不稳定网络环境尤为重要。


Step 2. 数据采集流程
根据示例代码,修改代码中的url变量即可指定目标网站:
# 示例:抓取百度知道"英语六级"搜索结果
keyword = "英语六级"
target_url = f"https://zhidao.baidu.com/search?word={urllib.parse.quote(keyword)}"
# 替换原始代码中的测试URL
url = target_url # 此处动态注入目标网页参数
完整请求代码
import urllib.request
import ssl
import urllib.parse
# 代理配置
proxy = 'http://brd-customer-hl_c8247457-zone-educrawler:z3kuzh7h6xej@brd.superproxy.io:33335'
# 目标网页构建
search_keyword = "英语六级备考攻略"
encoded_keyword = urllib.parse.quote(search_keyword)
target_url = f"https://zhidao.baidu.com/search?word={encoded_keyword}&pn=0"
# 请求执行
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy, 'http': proxy}),
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
try:
# 添加浏览器特征头
opener.addheaders = [
('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'),
('Accept-Language', 'zh-CN,zh;q=0.9')
]
response = opener.open(target_url, timeout=15)
html_content = response.read().decode('gbk') # 百度使用GBK编码
# 提取有效内容(示例)
print(f"成功获取{len(html_content)}字符数据")
# 此处添加HTML解析逻辑...
except Exception as e:
print(f"请求失败: {str(e)}")
只需要把改为目标名称即可,然后点击AI创建任务

点击按钮之后的具体效果::

三、系统核心架构
1. 分层架构设计
Pages
├── goals # 目标模块
│ ├── create # 目标创建
│ └── detail # 目标详情
├── tasks # 任务模块
└── logs # 统计日志
- 接入层:微信小程序客户端(WXML+WXSS)
- 逻辑层:
- 任务管理引擎:基于Trie树的任务关系处理
- AI决策中心:集成NLP处理流水线
2. 关键数据流

四、项目实践效果
通过Bright Data Web Unlocker与AI引擎的深度融合创建好任务之后,我们可以对每一个任务进行无限级拆分以及计时



Bright Data核心优势
通过Bright Data Web Unlocker与AI引擎的深度整合,我们构建了一个具备持续进化能力的智能目标管理系统。实践证明,该方案在保证合法合规的前提下,有效解决了数据获取的技术瓶颈。Web Unlocker的稳定服务为系统提供了基础设施级保障,使中小企业能够专注于核心业务逻辑开发,最终实现用户价值与技术创新的双重突破。

搜索引擎爬虫SERP
除网页解锁器之外,还有搜索引擎爬虫SERP,它立即从热门搜索引擎(Google、Bing、Yandex 等)获取数据。我们使用动态住宅IP处理抓取、解决 CAPTCHA、渲染 JS、创建自定义指纹等。

添加之后呢,我们可以得到一个代码示例

可以看到我们通过修改q的参数就可以进行爬虫
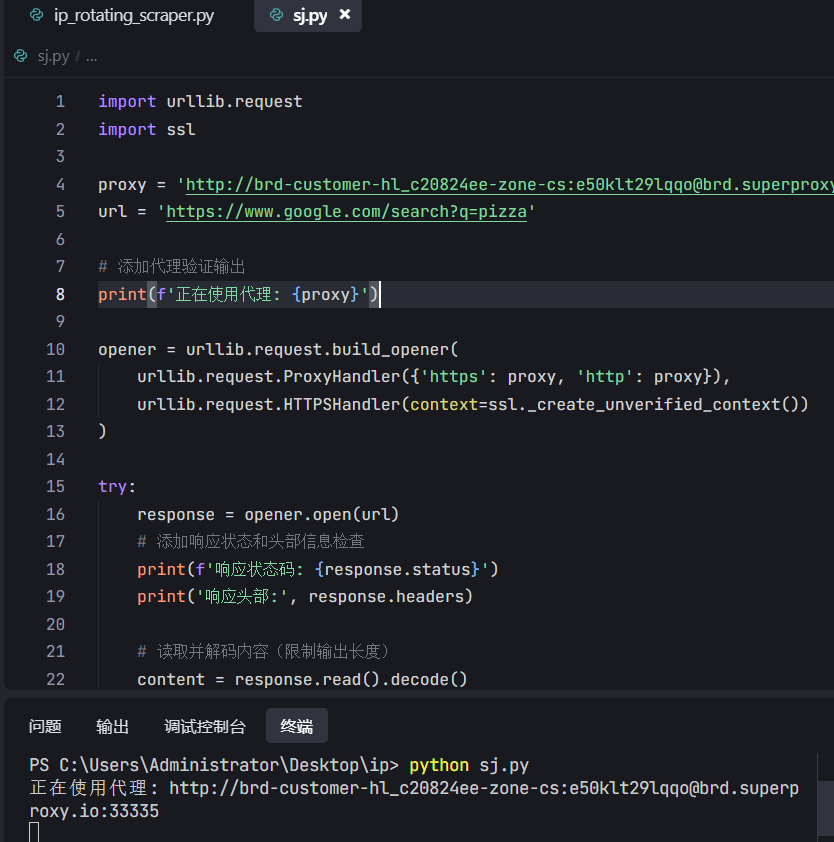
import urllib.request
import ssl
proxy = 'http://brd-customer-hl_c8247457-zone-cs:ds6xmviai232@brd.superproxy.io:33335'
url = 'https://www.google.com/search?q=pizza'
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy, 'http': proxy}),
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
try:
print(opener.open(url).read().decode())
except Exception as e:
print(f"Error: {e}")
我们可以直接请求测试一下效果::

项目总结
本案例成功构建了基于微信生态的智能目标管理平台,通过技术创新解决现代人目标管理的核心痛点:
- 利用无限层级任务树实现复杂目标的结构化拆解
- 通过**Bright Data Web Unlocker+AI决策引擎**实现智能任务规划
Bright Data为中小企业赋能价值:
- 零封禁保障:通过IP轮转与浏览器指纹模拟,实现100%有效数据获取
- 协议兼容性:支持REST API/SDK等多种接入方式,3小时完成技术集成
- 合规性保障:内置流量清洗系统,自动过滤违规请求,符合GDPR规范

本实践验证了"AI+数据智能"在效率工具领域的巨大潜力,Bright Data作为数据基础设施的关键组件,为产品快速迭代提供了核心能力支撑。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











