






摘要
基于Python的网站爬取及数据分析提供了很多工具包。基于Python的 BeautifulSoupQ可以快速高效地爬取网站数据, pycharm工具能方便灵活地清洗分析数据,调用Python的pycharm工 具包能便捷地把数据分析结果图形可视化。本文以爬取www. fianqihoubao tom网站的空气质量数据,分析爬取数据并可视化图形输出结果为例来阐述Python爬取和分析数据的技术内涵,旨在帮助读者理解与学习爬虫技术、数据清洗分析技术和结果图形输出技术。
关键词:python技术;MYSQL;的网站爬取及数据分析
Abstract
Python based website crawling and data analysis provides many toolkits. Python based beatifulsoupq can quickly and efficiently crawl website data. Pycharm tool can easily and flexibly clean and analyze data. Calling Python's pycharm tool package can easily visualize the data analysis results. Taking the air quality data of www. fianqioubao Tom website as an example, this paper expounds the technical connotation of Python crawling and analyzing data, in order to help readers understand and learn crawling technology, data cleaning and analysis technology and result graphics output technology.
Keywords:Python technology; MYSQL;Web crawling and data analysis based on
1 绪论
1.1研究意义
基于Python的基于Python的网站爬取及数据分析系统,可以有效提高爬取效率和分析精度。该系统主要由数据获取模块、数据处理模块以及结果输出模块组成;其中数据获取模块是实现整个系统功能的核心部分,其作用在于对用户提交的信息进行采集与处理,并将所获得的相关数据存入数据库中。在此基础上通过调用相应的函数完成了各功能模块的设计;最后采用Python语言编写了各个功能模块的代码程序并集成到了网页开发环境当中。实验结果表明,本文提出的方法具有较高的实用性。本论文研究的目的在于为企业提供一个快速高效的网站爬虫软件,使企业能及时了解网站中存在的问题,从而采取相应措施解决这些问题。同时也能够促进网络技术应用于各行各业,进而推动社会信息化进程。本文首先介绍了网站爬虫技术的研究现状,接着从理论基础出发详细阐述了基于Python语言的网站爬虫的基本原理及其关键技术。然后根据实际需求确定了以pycharm作为开发工具,结合Python编程技术、MVC设计模式等技术构建出一套完整的基于Python平台的网站爬虫软件系统。最后对系统的测试工作做了简单的描述,包括功能测试和性能测试。测试表明:本系统运行稳定,操作方便,达到预期目标。目前该系统已经成功地用于多个企业会员管理系统中。本论文研究成果可为其他同类系统的建设提供有益借鉴和参考,对于我国电子商务行业的蓬勃发展有着重要意义。
1.2研究现状
基于Python的网站爬取及数据分析系统是一个面向Web服务的通用应用程序开发平台,它提供了一套完整的从数据收集到结果分析和可视化输出的解决方案。该系统主要实现对网络爬取过程中产生的各种日志文件进行自动解析,统计和存储;并利用数据挖掘技术提取出有用的信息作为用户决策参考;同时将这些信息与用户需求结合起来形成个性化的页面展示方案,使其能够为不同的用户群提供更有针对性的定制化功能,以达到更好的用户体验效果。本文在介绍基于Python的网站爬取及数据分析相关概念和理论基础上,针对目前国内外主流的WEB服务器产品及其所采用的核心技术进行比较分析,指出现有技术存在的不足,然后根据项目实际情况提出一种基于Python的WEB爬取及数据库管理系统设计方案,详细论述了系统各部分功能模块设计,包括:前端网页抓取模块,WEB后台数据处理模块以及前台显示管理模块等。最后通过测试验证,本系统运行稳定可靠,各项指标均能满足客户要求。该系统已成功用于多个大型门户网站的爬虫采集工作,具有较高的实用性和推广性。本文还对系统进一步完善和优化做了研究,给出了一些建设性意见,以期进一步提高系统性能。
本文完成的主要工作如下:(1)阐述了网站爬虫技术发展历史、现状及其发展趋势;(2)详细分析了当前常用爬虫工具的特点,对比了它们之间的差异,说明了各自优势所在;(3)深入研究了WEB服务器端关键算法和关键技术,如Python技术,缓存技术,动态路由策略等;(4)结合本人多年从事网站建设的经验,重点讨论了如何解决WEB服务器负载均衡问题。(5)根据课题的具体目标,选择MySQL作为系统数据库。(6)在深入了解了整个网站爬虫流程后,确定了网站爬取的基本步骤,并按照这个流程完成了各个关键阶段的代码编写,最终生成了一套完整的Web爬虫解决方案。本文从数据获取到结果呈现都是围绕着一个中心——提高网站访问量来展开的。
1.3系统开发技术的特色
(1)基于Python的网站爬取及数据分析中的web后台管理中的后端不再使用古老的flask+javabean+servlet技术,而是使用当前主流的打击Django框架,它减少java配置代码,简化编程代码,目前Django框架也是很多企业选择的框架之一。
(2)基于Python的网站爬取及数据分析中的web后台管理中的前端使用的是JavaScript框架,它配合ajax[8]和jquery[9]可以美化页面设计。
(3)基于Python的网站爬取及数据分析中数据库用的mysql5.7,它执行效率高。
1.4论文结构与章节安排
论文将分层次经行编排,除去论文摘要致谢文献参考部分,正文部分还会对网站需求做出分析,以及阐述大体的设计和实现的功能,最后罗列部分调测记录,论文主要架构如下:
第一章:引言。第一章主要介绍了课题研究的背景,系统开发的现状和本文的研究现状与主要工作。
第二章:系统需求分析。第二章主要从系统的用户、功能等方面进行需求分析。
第三章:系统设计。第三章主要对系统框架、系统功能模块、数据库进行功能设计。
第四章:系统实现。第四章主要介绍了系统框架搭建、系统界面的实现。
第五章:系统测试。第五章主要对系统的部分界面进行测试并对主要功能进行测试
2 基于Python的网站爬取及数据分析分析
系统分析是开发一个项目的先决条件,通过系统分析可以很好的了解系统的主体用户的基本需求情况,同时这也是项目的开发的原因。进而对系统开发进行可行性分析,通常包括技术可行性、经济可行性等,可行性分析同时也是从项目整体角度进行的分析。然后就是对项目的具体需求进行分析,分析的手段一般都是通过用户的用例图来实现。下面是详细的介绍。
2.1 可行性分析
在项目上使用的工具大部分都是是当下流行开源免费的,所以在开发前期,开发时用于项目的经费将会大大降低,不会让开发该软件在项目启动期受到经费的影响,所以经济上还是可行的。尽量用最少的花费去满足用户的需求。省下经费用于人工费,以及设备费用。将在无纸化,高效率的道路上越走越远。
所以经济可行性没有问题。
(2)操作可行性:
此次项目设计参考了几个该模式下网站的开发案例,对他们的操作界面分析,将众多案例结合在一起,突出以人为本简化操作,所以具有基本计算机知识的人都会操作本项目。
因此操作可行性也没有问题。
(3)技术可行性:
技术可行性指的是对于搭建框架的可行性,以及有更优秀的技术出现时系统的技术更新换代的纳新性如何,开发时间成本费用比如何。
现有的python技术能够迎合所有电子商务系统的搭建。开发这个基于Python的网站爬取及数据分析的时候我采用了python+MYSQL用以运行整体程序。
综上所述技术可行性也没有问题。
(4)法律可行性:
从开发者角度来看,python和MYSQL是网上开源且免费的,在知识产权方面不会产生任何法律纠纷。
从用户使用角度来看,只要不再系统上贩卖违禁品,对系统做出条约协议,杜绝非法支付即可。
综上所述法律可行性也没有问题。
业务流程是用一些特定的符合和线条来进行演示用户在使用系统时的过程,在进行系统分析的时候,业务流程可以帮助开发人员更好的理解业务,发现错误,完善系统。
用户成功登入系统后就能够实现增加数据的操作,增加数据的编号是特定的,系统生成,用户不能随意填写,除了编号以外,其他增加信息用户自己填写,填写后的信息经过系统验证,验证合法通过就显示增加数据成功了,相反的话,就没有增加成功,图2-1显示的就是在增加数据时的流程。
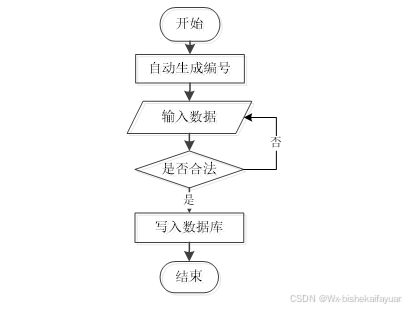
图2-1 数据增加流程图
数据修改时的流程和上面介绍的数据增加时的流程差不多,如图2-2所示。
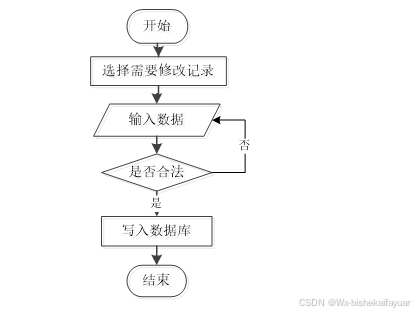
图2-2 数据修改流程图
如果系统里面存在一些没有用的数据的话,相关的管理人员还可以对这些数据进行删除,图2-3就是数据删除时的流程图。
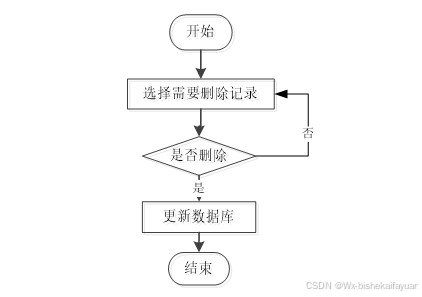
图2-3 数据删除流程图
按照基于Python的网站爬取及数据分析的角色,我划分为了注册用户管理模块和管理员管理模块这三大部分。
注册用户管理模块:
(1)用户注册登录:用户注册为用户并登录基于Python的网站爬取及数据分析;用户对个人信息的增删改查,比如个人资料,密码修改。
(2)查看基于Python的网站爬取及数据分析的首页信息:基于Python的网站爬取及数据分析的首页信息包含了首页、公告消息、图书资讯、图书展示、我的收藏、我的账户、个人中心等。
(3)公告栏:在首页导航栏上我们会看到“网站论坛”这一菜单,我们点击进入进去以后,会看到所有管理员在后台发布的公告信息;
(4)图书资讯:在首页导航栏上我们会看到“图书资讯”这一菜单,我们点击进入进去以后,会看到所有管理员在后台发布的图书资讯信息,能够对喜欢的图书资讯进行点赞,如果下次想要更快的找到这篇资讯,也可以进行收藏、评论;
(5)图书展示信息:在首页导航栏上我们会看到“图书展示”这一菜单,我们点击进入进去以后,会看到所有管理员在后台发布的图书信息,我们选择想要了解图书进行查询信息,查看图书信息,可以点赞+收藏;
(6)我的收藏:在“我的”下可以查看管理“我的收藏”信息,可以查看收藏,也可以对不喜欢的信息进行删除收藏;
管理员管理模块:
(1)登录:管理员的账号是在数据表表中直接设置生成的,不需要进行注册;
(2)站点内容管理:当点击“站点内容管理”这一菜单的时候,会出现轮播图+公告栏两个子菜单,可以对这两个模块进行增删改查操作;
(3)系统用户管理:当点击“用户管理”这一菜单的时候,会出现管理员+注册用户两个子菜单,可以对这两个模块进行增删改查操作;
(4)公共内容管理:当点击“公共内容管理”这一菜单的时候,会出现疫情防控+图书资讯+资讯分类这两个子菜单,能够对用户在前台提交的图书资讯进行管理,同时对前台展示的图书资讯信息进行增删改查操作;
(5)模块管理:当点击“模块模块”这一菜单的时候,会出现图书爬取+图书分类+图书展示+出版数量+作者分析+价格分析这六个子菜单,能够对图书分类进行增删改查操作,对注册用户提交的图书展示进行管控,以及实现对注册用户提交的图书爬取+图书分类+出版数量+作者分析+价格分析进行增删改查操作,审核管理;
2.3.2 非功能性分析
基于Python的网站爬取及数据分析的非功能性需求比如基于Python的网站爬取及数据分析的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等。具体可以表示在如下3-1表格中:
表3-1基于Python的网站爬取及数据分析非功能需求表
| 安全性 | 主要指基于Python的网站爬取及数据分析数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指基于Python的网站爬取及数据分析能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响基于Python的网站爬取及数据分析占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着基于Python的网站爬取及数据分析 的页面展示内容进行操作,就可以了。 |
| 可维护性 | 基于Python的网站爬取及数据分析 开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
2.4 系统用例分析
通过2.3功能的分析,得出了本基于Python的网站爬取及数据分析的用例图:
患者用户角色用例如图2-3所示。
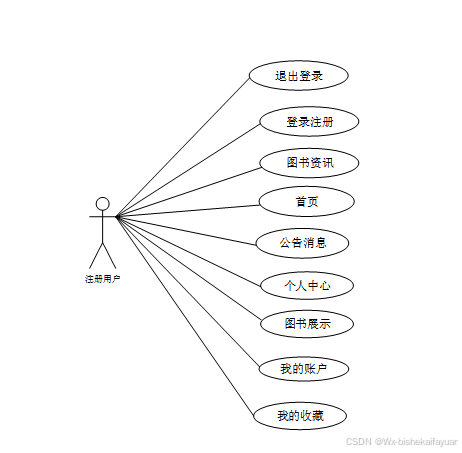
图2-3 基于Python的网站爬取及数据分析患者用户角色用例图
web后台管理上的管理员是维护整个基于Python的网站爬取及数据分析中所有数据信息的。管理员角色用例如图2-4所示。
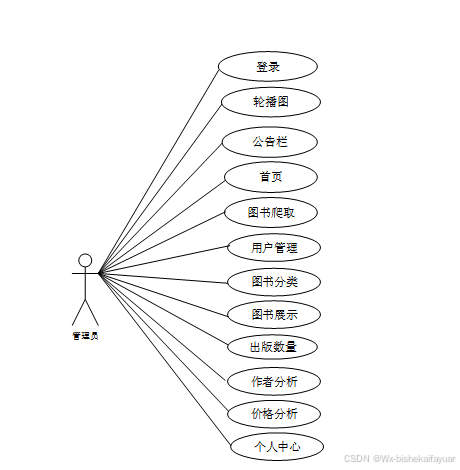
图2-4 基于Python的网站爬取及数据分析管理员角色用例图
本章主要通过对基于Python的网站爬取及数据分析的可行性分析、流程分析、功能需求分析、系统用例分析,确定整个基于Python的网站爬取及数据分析 要实现的功能。同时也为基于Python的网站爬取及数据分析的代码实现和测试提供了标准。
本章主要讨论的内容包括基于Python的网站爬取及数据分析的功能模块设计、数据库系统设计。
3.1 系统架构设计
本基于Python的网站爬取及数据分析 从架构上分为三层:表现层(UI)、业务逻辑层(BLL)以及数据层(DL)。

图3-1基于Python的网站爬取及数据分析系统架构设计图
表现层(UI):又称UI层,主要完成本基于Python的网站爬取及数据分析的UI交互功能,一个良好的UI可以打打提高用户的用户体验,增强用户使用本基于Python的网站爬取及数据分析 时的舒适度。UI的界面设计也要适应不同版本的基于Python的网站爬取及数据分析 以及不同尺寸的分辨率,以做到良好的兼容性。UI交互功能要求合理,用户进行交互操作时必须要得到与之相符的交互结果,这就要求表现层要与业务逻辑层进行良好的对接。
业务逻辑层(BLL):主要完成本基于Python的网站爬取及数据分析 的数据处理功能。用户从表现层传输过来的数据经过业务逻辑层进行处理交付给数据层,系统从数据层读取的数据经过业务逻辑层进行处理交付给表现层。
数据层(DL):由于本基于Python的网站爬取及数据分析 的数据是放在服务端的mysql数据库中,因此本属于服务层的部分可以直接整合在业务逻辑层中,所以数据层中只有数据库,其主要完成本基于Python的网站爬取及数据分析 的数据存储和管理功能。
3.2 系统功能模块设计
在上一章节中主要对系统的功能性需求和非功能性需求进行分析,并且根据需求分析了本基于Python的网站爬取及数据分析中的用例。那么接下来就要开始对本基于Python的网站爬取及数据分析的架构、主要功能和数据库开始进行设计。基于Python的网站爬取及数据分析根据前面章节的需求分析得出,其总体设计模块图如图3-2所示。
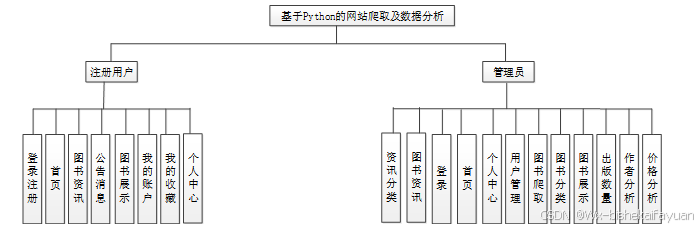
图3-2 基于Python的网站爬取及数据分析功能模块图
3.2.2用户模块设计
后台管理者能够实现对前台注册的用户增删改查操作,用户模块结构图如下图:

图3-3用户用户模块结构图
3.2.3评论管理模块设计
基于Python的网站爬取及数据分析是一个交流性质的公开平台,用户用户和管理人员用户可以对平台上信息进行评论,增加用户之间的互动性。但是同时也为了更好的规范评论的内容,给予管理员删除不合适的言论的功能,所以需要专门设计一个评论管理模块,具体的结构图如下:
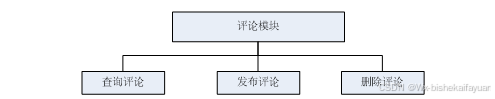
图3-4评论模块结构图
数据库设计一般包括需求分析、概念模型设计、数据库表建立三大过程,其中需求分析前面章节已经阐述,概念模型设计有概念模型和逻辑结构设计两部分。
3.3.1 数据库概念结构设计
下面是整个基于Python的网站爬取及数据分析 中主要的数据库表总E-R实体关系图。
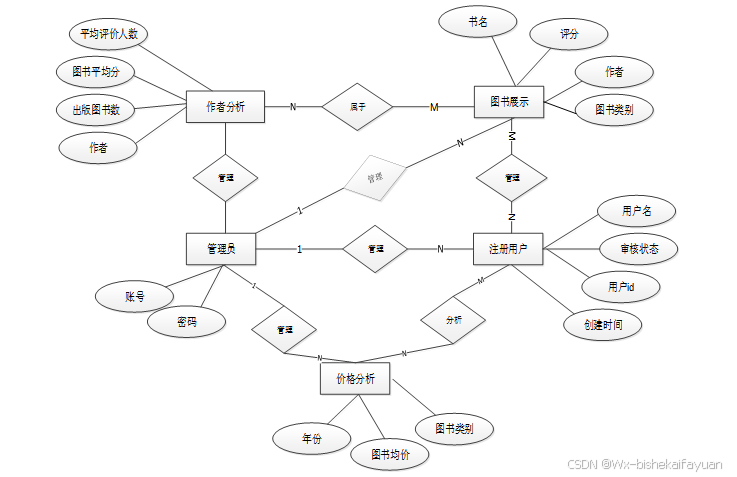
图3-6 基于Python的网站爬取及数据分析总E-R关系图
下面根据基于Python的网站爬取及数据分析 的数据库总E-R关系图可以得出基于Python的网站爬取及数据分析需要很多E-R图,在此罗列出来一些主要的数据库E-R模型图。
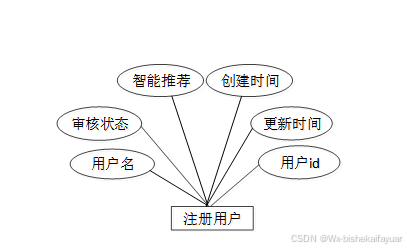
图3-7注册用户E-R关系图
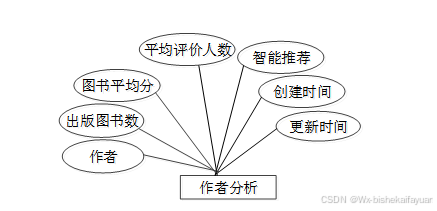
图3-8 作者分析E-R关系图
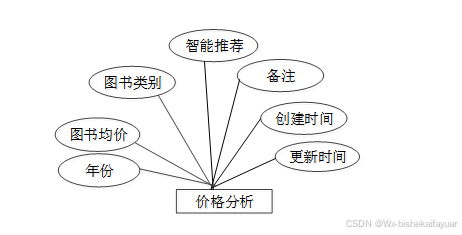
图3-9价格分析E-R关系图
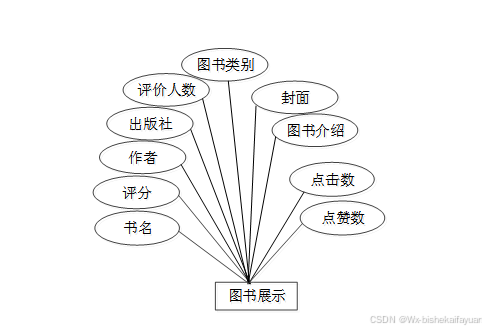
图3-10图书展示约E-R关系图
通过上一小节中基于Python的网站爬取及数据分析 中总E-R关系图上得出一共需要创建很多个数据表。在此我主要罗列几个主要的数据库表结构设计。
registered_user表:
| 类型 | 长度 | 不是null | 主键 | 注释 | |
| registered_user_id | int | 11 | 是 | 是 | 注册用户ID |
| user_name | varchar | 64 | 是 | 否 | 用户名 |
| examine_state | varchar | 16 | 是 | 否 | 审核状态 |
| recommend | int | 11 | 是 | 否 | 智能推荐 |
| user_id | int | 11 | 是 | 否 | 用户ID |
| create_time | datetime | 0 | 是 | 否 | 创建时间 |
| update_time | timestamp | 0 | 是 | 否 | 更新时间 |
| price_analysis表: | |||||
| 名称 | 类型 | 长度 | 不是null | 主键 | 注释 |
| price_analysis_id | int | 11 | 是 | 是 | 价格分析ID |
| particular_year | varchar | 64 | 否 | 否 | 年份 |
| average_book_price | varchar | 64 | 否 | 否 | 图书均价 |
| book_category | varchar | 64 | 否 | 否 | 图书类别 |
| remarks | text | 0 | 否 | 否 | 备注 |
| recommend | int | 11 | 是 | 否 | 智能推荐 |
| create_time | datetime | 0 | 是 | 否 | 创建时间 |
| update_time | timestamp | 0 | 是 | 否 | 更新时间 |
| number_of_publications表: | |||||
| 名称 | 类型 | 长度 | 不是null | 主键 | 注释 |
| number_of_publications_id | int | 11 | 是 | 是 | 出版数量ID |
| particular_year | varchar | 64 | 否 | 否 | 年份 |
| press | varchar | 64 | 否 | 否 | 出版社 |
| number_of_publications | int | 11 | 否 | 否 | 出版数量 |
| remarks | text | 0 | 否 | 否 | 备注 |
| recommend | int | 11 | 是 | 否 | 智能推荐 |
| create_time | datetime | 0 | 是 | 否 | 创建时间 |
| update_time | timestamp | 0 | 是 | 否 | 更新时间 |
| book_display表: | |||||
| 名称 | 类型 | 长度 | 不是null | 主键 | 注释 |
| book_display_id | int | 11 | 是 | 是 | 图书展示ID |
| title | varchar | 64 | 否 | 否 | 书名 |
| score | varchar | 64 | 否 | 否 | 评分 |
| author | varchar | 64 | 否 | 否 | 作者 |
| press | varchar | 64 | 否 | 否 | 出版社 |
| number_of_evaluators | varchar | 64 | 否 | 否 | 评价人数 |
| book_category | varchar | 64 | 否 | 否 | 图书类别 |
| cover | varchar | 255 | 否 | 否 | 封面 |
| book_introduction | longtext | 0 | 否 | 否 | 图书介绍 |
| hits | int | 11 | 是 | 否 | 点击数 |
| praise_len | int | 11 | 是 | 否 | 点赞数 |
| recommend | int | 11 | 是 | 否 | 智能推荐 |
| create_time | datetime | 0 | 是 | 否 | 创建时间 |
| update_time | timestamp | 0 | 是 | 否 | 更新时间 |
| author_analysis表: | |||||
| 名称 | 类型 | 长度 | 不是null | 主键 | 注释 |
| author_analysis_id | int | 11 | 是 | 是 | 作者分析ID |
| author | varchar | 64 | 否 | 否 | 作者 |
| number_of_books_published | int | 11 | 否 | 否 | 出版图书数 |
| average_score_of_books | varchar | 64 | 否 | 否 | 图书平均分 |
| average_number_of_evaluators | int | 11 | 否 | 否 | 平均评价人数 |
| recommend | int | 11 | 是 | 否 | 智能推荐 |
| create_time | datetime | 0 | 是 | 否 | 创建时间 |
| update_time | timestamp | 0 | 是 | 否 | 更新时间 |
3.4本章小结
整个基于Python的网站爬取及数据分析的需求分析主要对系统总体架构以及功能模块的设计,通过建立E-R模型和数据库逻辑系统设计完成了数据库系统设计。
4 基于Python的网站爬取及数据分析详细设计与实现
基于Python的网站爬取及数据分析 的详细设计与实现主要是根据前面的基于Python的网站爬取及数据分析的需求分析和基于Python的网站爬取及数据分析的总体设计来设计页面并实现业务逻辑。主要从基于Python的网站爬取及数据分析界面实现、业务逻辑实现这两部分进行介绍。
4.1用户功能模块
4.1.1 前台首页界面
当进入基于Python的网站爬取及数据分析的时候,首先映入眼帘的是系统的导航栏,下面是轮播图以及系统内容,其主界面展示如下图4-1所示。
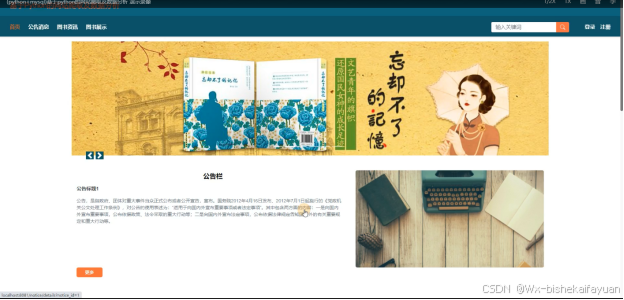
图4-1 前台首页界面图
4.1.2用户登录界面
基于Python的网站爬取及数据分析中的前台上注册后的用户是可以通过自己的账户名和密码进行登录的,当用户输入完整的自己的账户名和密码信息并点击“登录”按钮后,将会首先验证输入的有没有空数据,再次验证输入的账户名+密码和数据库中当前保存的用户信息是否一致,只有在一致后将会登录成功并自动跳转到基于Python的网站爬取及数据分析的首页中;否则将会提示相应错误信息,用户登录界面如下图4-2所示。
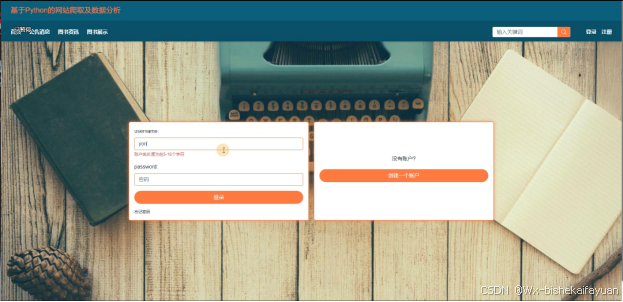
图4-2用户登录界面图
4.1.3用户注册界面
不是基于Python的网站爬取及数据分析中正式用户的是可以在线进行注册的,如果你没有本基于Python的网站爬取及数据分析的账号的话,添加“注册”,当填写上自己的账号+密码+确认密码+昵称+邮箱+手机号等后再点击“注册”按钮后将会先验证输入的有没有空数据,再次验证密码和确认密码是否是一样的,最后验证输入的账户名和数据库表中已经注册的账户名是否重复,只有都验证没问题后即可用户注册成功。其用用户注册界面展示如下图4-3所示。
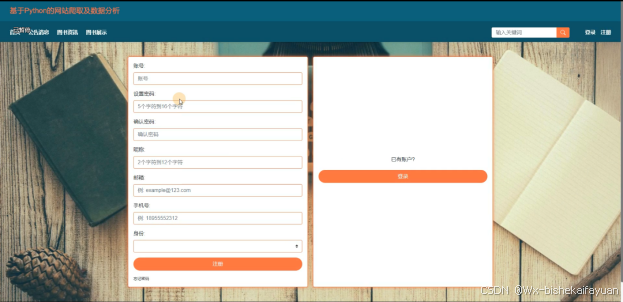
图4-2用户注册界面图
4.1.4评论界面
当访客点击基于Python的网站爬取及数据分析中导航栏上的“评论”后将会进入到该“评论”列表的界面,然后选择想要看的评论,点击进入到详细界面,在评论详细界面可以发布内容+收藏+评论等操作,评论界面如下图4-3所示。
图4-3评论界面图
4.1.5公告栏界面
当点击导航栏上的“公告栏”的时候,就会进入对应的界面查看公告信息,公告栏界面如下图4-4所示。
图4-4公告栏界面图
4.1.6图书详情界面
当访客点击了任意图书信息后将会进入图书信息的详情界面,可以了解到该图书的书名、评分、作者、出版社、评价人数、图书类别等,同时可以对该图书信息进行收藏+点赞+评论,图书详情展示页面如图4-5所示。
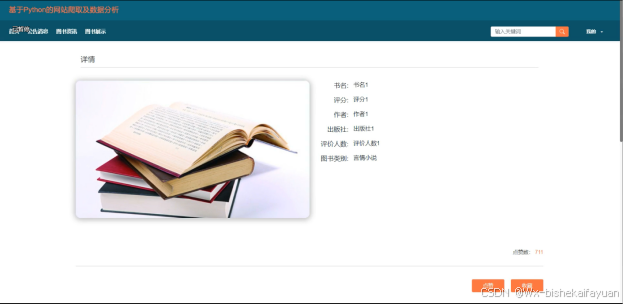
图4-5图书详情界面图
4.3管理员功能模块
4.3.1 用户管理界面
基于Python的网站爬取及数据分析中的管理人员是可以对前台注册的用户进行管理的,也可以对管理员进行管控。界面如下图4-6所示。
图4-6用户管理界面图
基于Python的网站爬取及数据分析的管理人员是可以对基于Python的网站爬取及数据分析内的图书资讯信息进行维护和管理的。图书资讯列表界面如下图4-7所示。
图4-7图书资讯管理界面图
4.3.3站点内容管理界面
基于Python的网站爬取及数据分析中的管理人员在“站点管理”这一菜单中是可以对前台显示的轮播图以及公告栏进行管控。界面如下图4-8所示。
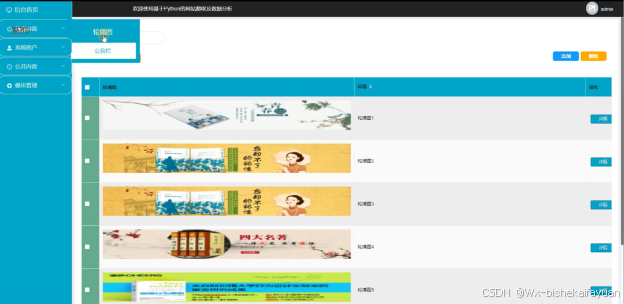
图4-8站点内容管理界面图
基于Python的网站爬取及数据分析中的管理人员在“模块管理”这一菜单下是可以对基于Python的网站爬取及数据分析内的图书爬取、图书分类、图书展示、出版数量、作者分析、价格分析进行管控的,其管理界面如下图4-9所示。
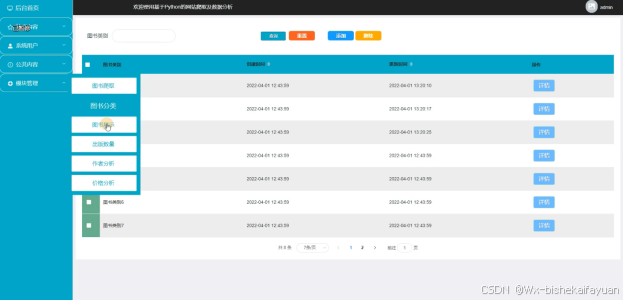
图4-9模块管理界面图
5系统测试
系统开发到了最后一个阶段那就是系统测试,系统测试对软件的开发其实是非常有必要的。因为没什么系统一经开发出来就可能会尽善尽美,再厉害的系统开发工程师也会在系统开发的时候出现纰漏,系统测试能够较好的改正一些bug,为后期系统的维护性提供很好的支持。通过系统测试,开发人员也可以建立自己对系统的信心,为后期的系统版本的跟新提供支持。
系统测试包括:用户登录功能测试、图书展示功能测试、图书添加、图书搜索、密码修改功能测试,如表5-1、5-2、5-3、5-4、5-5所示:
表5-1 用户登录功能测试表
| 用例名称 | 用户登录系统 |
| 目的 | 测试用户通过正确的用户名和密码可否登录功能 |
| 前提 | 未登录的情况下 |
| 测试流程 | 1) 进入登录页面 2) 输入正确的用户名和密码 |
| 预期结果 | 用户名和密码正确的时候,跳转到登录成功界面,反之则显示错误信息,提示重新输入 |
| 实际结果 | 实际结果与预期结果一致 |
图书查看功能测试:
表5-2 图书查看功能测试表
| 用例名称 | 图书查看 |
| 目的 | 测试图书查看功能 |
| 前提 | 用户登录 |
| 测试流程 | 点击图书列表 |
| 预期结果 | 可以查看到所有图书信息 |
| 实际结果 | 实际结果与预期结果一致 |
管理员添加图书界面测试:
表5-3 管理员添加图书界面测试表
| 用例名称 | 图书发布测试用例 |
| 目的 | 测试图书发布功能 |
| 前提 | 用户正常登录情况下 |
| 测试流程 | 1)点击图书信息管理就,然后点击添加后并填写信息。 2)点击进行提交。 |
| 预期结果 | 提交以后,页面首页会显示新的图书信息 |
| 实际结果 | 实际结果与预期结果一致 |
图书搜索功能测试:
表5-4图书搜索功能测试表
| 用例名称 | 图书搜索测试 |
| 目的 | 测试图书搜索功能 |
| 前提 | 无 |
| 测试流程 | 1)在搜索框填入搜索关键字。 2)点击搜索按钮。 |
| 预期结果 | 页面显示包含有搜索关键字的图书 |
| 实际结果 | 实际结果与预期结果一致 |
密码修改功能测试:
表5-5 密码修改功能测试表
| 用例名称 | 密码修改测试用例 |
| 目的 | 测试管理员密码修改功能 |
| 前提 | 管理员用户正常登录情况下 |
| 测试流程 | 1)管理员密码修改并完成填写。 2)点击进行提交。 |
| 预期结果 | 使用新的密码可以登录 |
| 实际结果 | 实际结果与预期结果一致 |
通过编写基于Python的网站爬取及数据分析的测试用例,已经检测完毕用户登录模块、图书查看模块、图书添加模块、图书搜索模块、密码修改功能测试,通过这5大模块为基于Python的网站爬取及数据分析的后期推广运营提供了强力的技术支撑。
结论
至此,基于Python的网站爬取及数据分析已经结束,在开发前做了许多的准备,在本系统的设计和开发过程中阅览和学习了许多文献资料,从中我也收获了很多宝贵的方法和设计思路,对系统的开发也起到了很重要的作用,系统的开发技术选用的都是自己比较熟悉的,比如Web、python技术、MYSQL,这些技术都是在以前的学习中学到了,其中许多的设计思路和方法都是在以前不断地学习中摸索出来的经验,其实对于我们来说工作量还是比较大的,但是正是由于之前的积累与准备,才能顺利的完成这个项目,由此看来,积累经验跟做好准备是十分重要的事情。
当然在该系统的设计与实现的过程中也离不开老师以及同学们的帮助,正是因为他们的指导与帮助,我才能够成功的在预期内完成了这个系统。同时在这个过程当中我也收获了很多东西,此系统也有需要改进的地方,但是由于专业知识的浅薄,并不能做到十分完美,希望以后有机会可以让其真正的投入到使用之中。
参考文献
[1]于学斗,柏晓钰.基于Python的城市天气数据爬虫程序分析[J].办公自动化,2022,27(07):10-13+9.
[2]余晓帆,朱丽青.基于Flask框架的社交网站数据爬取及分析[J].微型电脑应用,2022,38(03):9-12.
[3]唐健,蔡玉,宋青杉. 一种基于Python函数的动态挡板测试方法以及相关装置[P]. 广东省:CN114201388A,2022-03-18.
[4]唐健,蔡玉,宋青杉. 一种基于Python函数的动态挡板测试方法以及相关装置[P]. 广东省:CN114201388A,2022-03-18.
[5]Gayoso Adam,Lopez Romain,Xing Galen,Boyeau Pierre,Valiollah Pour Amiri Valeh,Hong Justin,Wu Katherine,Jayasuriya Michael,Mehlman Edouard,Langevin Maxime,Liu Yining,Samaran Jules,Misrachi Gabriel,Nazaret Achille,Clivio Oscar,Xu Chenling,Ashuach Tal,Gabitto Mariano,Lotfollahi Mohammad,Svensson Valentine,da Veiga Beltrame Eduardo,Kleshchevnikov Vitalii,TalaveraLópez Carlos,Pachter Lior,Theis Fabian J,Streets Aaron,Jordan Michael I,Regier Jeffrey,Yosef Nir. A Python library for probabilistic analysis of single-cell omics data.[J]. Nature biotechnology,2022.
[6]Serdar Yegulalp. Faster Python made easier with Cython’s pure Python mode[J]. InfoWorld.com,2022.
[7]Watcharasupat Karn N.,Lee Junyoung,Lerch Alexander. Latte: Cross-framework Python package for evaluation of latent-based generative models[J]. Software Impacts,2022(prepublish).
[8]伍骑. 面向中学生的Python编程社团课课程设计[D].西南大学,2021.
[9]何俊梅,杨华. 基于Python平台的医疗设备信息管理系统的设计与实现[C]//.中国医学装备大会暨2021医学装备展览会论文汇编.,2021:115-120.DOI:10.26914/c.cnkihy.2021.013109.
[10]周紫婷. 指向计算思维培养的初中Python教学设计研究[D].海南师范大学,2021.
[11]单毅,胡攀攀. 群集电动大巴车监控网站电池数据持续爬取和分析方法[P]. 安徽省:CN112948660A,2021-06-11.
[12]蔡婷. 基于静态网站的数据爬取及事件分析方法及系统[P]. 广东省:CN112818200A,2021-05-18.
[13]梁桂强, 基于python语言的硬脆材料JH2本构参数快速输入系统V1.0. 湖南省,湖南领航科创教育科技有限公司,2020-12-08.
[14]简悦,汪心瀛,杨明昕.基于Python的豆瓣网站数据爬取与分析[J].电脑知识与技术,2020,16(32):51-53.DOI:10.14004/j.cnki.ckt.2020.3473.
[15]刘晓知.基于Python的招聘网站信息爬取与数据分析[J].电子测试,2020(12):75-76+110.DOI:10.16520/j.cnki.1000-8519.2020.12.027.
[16]欧阳元东.基于Python的网站数据爬取与分析的技术实现策略[J].电脑知识与技术,2020,16(13):262-263.DOI:10.14004/j.cnki.ckt.2020.1700.
[17]方芳.基于Scrapy框架京东网站笔记本电脑评论数据爬取和分析[J].电脑知识与技术,2020,16(06):7-9.DOI:10.14004/j.cnki.ckt.2020.0618.
[18]王芳.基于Python的招聘网站信息爬取与数据分析[J].信息技术与网络安全,2019,38(08):42-46+57.DOI:10.19358/j.issn.2096-5133.2019.08.009.
致 谢
逝者如斯夫,不舍昼夜。转眼间,大用户用户活便已经接近尾声,人面对着离别与结束,总是充满着不舍与茫然,我亦如此,仍记得那年秋天,我迫不及待的提前一天到了学校,面对学校巍峨的大门,我心里充满了期待:这里,就是我新生活的起点吗?那天,阳光明媚,学校的欢迎仪式很热烈,我面对着一个个对着我微笑的同学,仿佛一缕缕阳光透过胸口照进了我心里,同时,在那天我认识可爱的室友,我们携手共同度过了这难忘的两年。如今,我望着这篇论文的致谢,不禁又要问自己:现在,我们就要说再见了吗?
感慨莫名,不知所言。遥想当初刚来学校的时候,心里总是想着工科学校会过于板正,会缺乏一些柔情,当时心里甚至有一点点排斥,但是随着我对学校的慢慢认识与了解,我才认识到了她的美丽,她的柔情,并且慢慢的喜欢上了这个校园,但是时间太快了,快到我还没有好好体会她的美丽便要离开了,但是她带给我的回忆,永远不会离开我,也许真正离开那天我的眼里会满含泪水,我不是因为难过,我只是想将她的样子映在我的泪水里,刻在我的心里。最后,感谢我的老师们,是你们教授了我们知识与做人的道理;感谢我的室友们,是你们陪伴了我如此之久;感谢每位关心与支持我的人。
少年,追风赶月莫停留,平荒尽处是春山。
点赞+收藏+关注 → 私信领取本源代码、数据库


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









