




 本文详细介绍了如何使用PySpark进行RDD编程,包括交互式数据分析和编写独立应用程序解决数据去重与求平均值问题。通过实例展示了在Ubuntu16.04环境下,利用Spark 2.4.0和Python 3.4.3处理和分析大学计算机系的成绩数据,计算学生人数、课程数量、平均分等,并实现了文件合并与去重、计算所有学生平均成绩的功能。
本文详细介绍了如何使用PySpark进行RDD编程,包括交互式数据分析和编写独立应用程序解决数据去重与求平均值问题。通过实例展示了在Ubuntu16.04环境下,利用Spark 2.4.0和Python 3.4.3处理和分析大学计算机系的成绩数据,计算学生人数、课程数量、平均分等,并实现了文件合并与去重、计算所有学生平均成绩的功能。
RDD编程初级实践(Python版)
一、实践所需资料及平台要求
1.所需数据获取
链接:https://pan.baidu.com/s/14h9jEZDLxQJYBHaYxJ5aVQ
提取码:rdd1
2.实践所需平台
操作系统:Ubuntu16.04
Spark版本:2.4.0(参考教程)
Python版本:3.4.3(参考教程)
二、实践内容
1.pyspark交互式编程
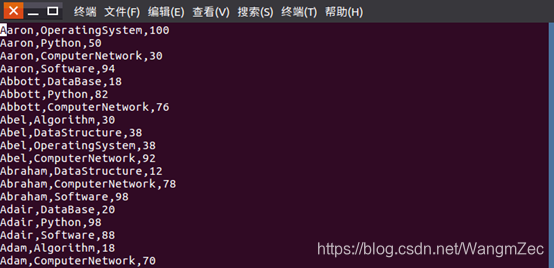
本编程提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
1)创建一个sparksqldata的文件,查询文件如图
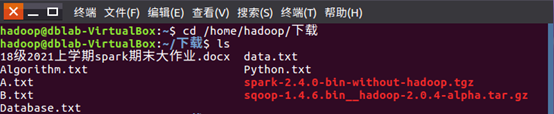
2)Cp拷贝的命令,将data.txt拷贝到目录sparkdata如图

3)启动pyspark,查看data.txt如图

4)加载数据集,获取每行数据的第1列;去重操作;取元素总个数
答案为265人。
(2)该系共开设了多少门课程;
获取每行数据的第2列;去重操作;取元素总个数

答案为8门。
(3)Tom同学的总成绩平均分是多少;
筛选Tom同学的成绩信息
res.foreach(print)
score = res.map(lambda x:int(x[2])) //提取Tom同学的每门成绩,并转换为int类型
num = res.count() //Tom同学选课门数
sum_sc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2592
2592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









