







 文章探讨了数据库索引的概念,如何通过索引优化查询性能,包括未加索引和添加索引后的查询方式对比,以及MySQL中B+Tree索引结构的应用。实例展示了如何创建、查询和删除索引,并比喻索引像书的目录,加速数据查找。
文章探讨了数据库索引的概念,如何通过索引优化查询性能,包括未加索引和添加索引后的查询方式对比,以及MySQL中B+Tree索引结构的应用。实例展示了如何创建、查询和删除索引,并比喻索引像书的目录,加速数据查找。
简介:当要查询的数据库表中的数据量巨大时(数据量达到百万级),查询效果非常低,小编自己在测试查询数据表中六百万数据量某个数据时,用了大概14秒左右,当我为查询的数据表中的一个字段添加上索引,还是同一条查询语句,时间只用了2毫秒左右,可见索引在提升查询效率方面的恐怖能力。
一、什么是索引

如上图所示:索引是帮助数据库高效获取数据的数据结构。图中我们有一条数据库查询语句
select * from user where age = 45 。
方式一:在没有为数据库表中添加索引的情况下,查询 age=45 的这条数据,数据库的查询方式为逐行扫描 user 表中的每一条数据直到查询到age=45 的这条数据。(如果这个age字段没有添加关键字 unique ,那么数据库还会继续查询剩下的所有数据,看是否还有 age=45 的数据)。
方式二:再添加索引后,相当于为添加索引的字段增加了一个查找二叉树(做举例,索引底层是 B+Tree ),二叉树的每一个节点都关联着数据表中的相对应的数据行,当找到节点,就找到了数据。
二、索引的优缺点

三、索引的结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们常说的索引,如果没有特别的指明,都是默认的B+Tree结构组织的索引。
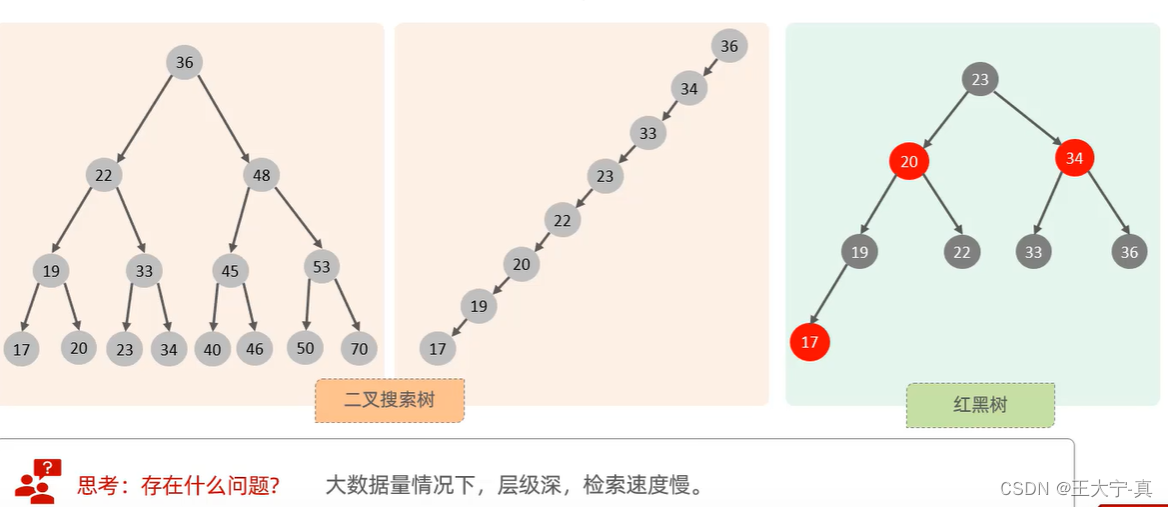
由上图中所示可知,如果索引使用二叉搜索树或者红黑树,当面临大量数据时查询速度也很慢,所以MySQL使用的索引非此二者之中。
MySQL数据库的索引结构使用的是 B+Tree 结构,入下图所示。
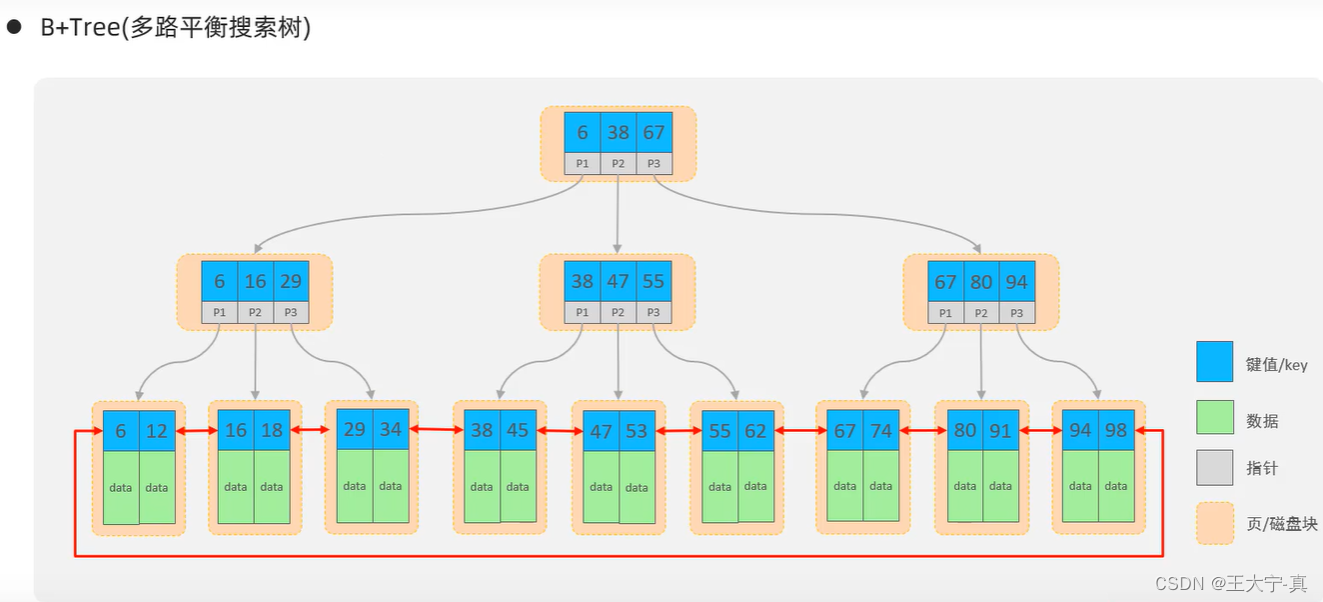
特点如下:
1. 每一个节点,可以存储多个key(有n个key,就有n个指针)。
2. 所有的数据都存储在叶子结点中,非叶子节点仅用于索引数据。
3. 叶子结点形成了一颗双向链表,便于数据的排序以及区间范围查询。
四、索引的操作语法
示例:初始代码和数据小编这边给出来了。
-- 员工管理(带约束)
create table tb_emp (
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
INSERT INTO tb_emp
(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',1,'2007-02-01',1,now(),now()),
(12,'hebiweng','123456','鹤笔翁',1,'12.jpg',1,'2008-08-18',1,now(),now()),
(13,'fangdongbai','123456','方东白',1,'13.jpg',2,'2012-11-01',2,now(),now()),
(14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2010-01-01',2,now(),now()),
(17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
下面演示索引的使用。
-- 创建: 为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询: 查询tb_emp 表的索引信息
show index from tb_emp;
-- 删除: 删除 tb_emp 表中 name 字段的索引
drop index idx_emp_name on tb_emp;结论:如果把数据表中的所有数据比作一本书,那么索引相当于这本书的目录,我们根据目录去查找内容一定比根据内容去找内容快很多的。
最后也请大家给个点赞、留言和关注,你的支持就是我最大的动力了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









