







引言:一篇写的很好的 ICLR 论文,既有模型的创新,也有数据集构建方法的详细介绍,还有评估指标构建的详细方案。
✅ NLP 研 2 选手的学习笔记
笔者简介:Wang Linyong,NPU,2023级,计算机技术
研究方向:文本生成、大语言模型
论文链接:https://arxiv.org/abs/2410.03051,2025 ICLR(CCF A) 长文
项目链接:https://github.com/rese1f/aurora
中文标题:《AuroaCap:效率高且性能好的视频详细字幕和一个新的基准》
基准排行榜(实时更新):https://rese1f.github.io/aurora-web/

⭐️ 重点备注: 本文中的 “字幕” 都是“Caption” 的意思。
文章目录
0 摘要
● 【一句话介绍本文所针对的任务】视频细节描述(Video detailed captioning)是一项关键任务,旨在生成全面、连贯的视频内容文本描述,有利于视频理解和生成。【简述文本的第一个创新点】本文提出 AuroraCap,一种基于大型多模态模型的视频描述器。遵循最简单的架构设计,不需要额外的参数进行时态建模。【简述第一个创新点的问题背景、关键技术及最终效果】为解决长视频序列造成的开销,实现了标记合并策略,减少了输入视觉标记的数量。令人惊讶的是,我们发现这种策略几乎没有导致性能损失。AuroraCap 在各种视频和图像描述基准上显示了卓越的性能,例如,在 Flickr30k 上获得了 88.9 的 CIDEr,超过了GPT-4V(55.3)和 Gemini-1.5 Pro(82.2)。【简述第二个创新点的问题背景】然而,现有的视频字幕基准测试仅包含由几十个单词组成的简单描述,限制了该领域的研究。【简述第二个创新点】本文开发了 VDC,一个视频细节的字幕基准,有一千多个细节注释的结构化字幕。【简述第三个创新点】此外,该文还提出了一种新的用 LLM 辅助的评价指标 VDCscore,该指标采用分而治之的策略,将较长的字幕评价转换为多个较短的问答对。【简述第二/三个创新点的最终效果】在人类 Elo 排名的帮助下,实验表明,该基准与人类对视频细节描述质量的判断更好地相关。
1 快速了解背景
1.1 任务描述
● 视频细节描述(Video detailed captioning) 任务即是生成全面和连贯的视频内容文本描述,不仅捕获主要动作和对象,还捕获复杂的细节、上下文细微差别和时间动态。如下图所示,红框的 4 张图片(可以理解为视频的 4 张关键帧)对应着红色的 “细节描述”。而蓝框的 4 张关键帧对应着蓝色的 “细节描述”。
● 翻译:
Teams are playing soccer.
球队正在踢足球。
A woman instructs and demonstrates how to remove the insides of a pumpkin.
一个女人指导并演示了如何移除南瓜的内部。

● 备注: 红框和篮筐的数据分别来自
MSR-VIT和VATEX两个数据集。”细节描述“ 比较简短,而作者提出的新数据集VDC就比较详细,后文将展开介绍。
1.2 研究意义
● 它已经成为计算机视觉和自然语言处理的一个关键研究领域,对机器人技术[32,148]、以自我为中心的感知[40,41]、具身智能[29,30,163-166]、视频编辑[13]和生成[7]等领域具有重要意义。
1.3 现存挑战
● 视频详细字幕面临的挑战包括训练和评估的详细字幕数据有限,以及缺乏良好的评估指标。
2 现有工作
● 在大型语言模型(LLMs)出现之前,以前的模型只能生成非常简短和粗略的视频 [130,139,144,147] 描述。尽管这些模型已经在 网络级规模 的视频-文本数据集上进行了训练(例如,HowTo100M [93]和 VideoCC3M [97]),但由于其规模较小和缺乏 LLMs 所拥有的世界知识,它们的能力仍然有限。最近,研究人员开始在预先训练的 LLMs(如LLaVA[82],DuultBlip[27],InternVL[23])上构建更强大的大型多模态模型(LMMs)。这些模型通常使用 中间组件(例如,Q-Froster[62]或MLP)来连接预先训练好的视觉变压器(ViT)[31]和LLM。
● 备注: 模型的创新主要就体现在 “中间组件” 上。
● 从 基于图像的LMMs 扩展到 基于视频的LMMs 是一个自然的过程,因为视频可以看作是帧序列(sequences of frames)。虽然大多数 LMMs 从加载图像模型的预训练权重开始,并与视频-文本数据进行进一步微调,但类似 LLaVA 的模型可以很容易地适应视频模型,而不需要任何额外参数,只需要高质量的视频-文本指令数据进行微调。
● 备注:
- “每秒帧数” 的单位可以用缩写 “FPS” 表示(Frames Per Second)。
30FPS: 表示1秒30帧(即30帧/秒)是目前最普遍的视频帧速率,可以提供良好的流畅度和动感,适合大多数的显示设备和网络环境。60FPS: 是目前最高的商用视频帧速率,可以提供极致的流畅度和动感,但也需要极高的硬件配置和网络带宽。另外,24FPS 是电影的帧数率。- “不需要任何额外参数” 指的是模型不需要再添加新的结构(也就不需要新的参数)。
3 现存问题一和已有解决方案
● 将视频作为一系列图像帧进行简单处理可能会导致巨大的计算开销,并可能导致长度问题的泛化[131]。为了解决这些问题,更具体地说,为了减少视觉标记(visual tokens)的数量,Video-LLaMA[72] 构建了一个自适应视频框架 Q-former, MovieChat[114] 使用了一个记忆库,LLaMA-VID[73] 简单地使用全局池化,而 FastV[16] 则根据 LLM 层中的注意力等级降低视觉标记(visual tokens)的数量。
4 本文的第一个创新点
● 动机: 为了减少视觉标记(visual tokens)的数量
● 本文提出 AuroraCap,采用一种简单而有效的方法,称为 Token Merging[10],被证明在图像和视频分类和编辑任务中是有效的[71]。使用二分软匹配算法(bipartite soft matching algorithm)在 transformer 层中逐步合并相似的标记,以减少视觉标记的数量。按照这种模式,实验表明,与 ViT 生成的原始 tokens 相比,只能使用 10% 到 20% 的视觉 tokens,且只在各种基准中性能略有下降。使用这种技术,更容易支持用于训练和推理的更高分辨率和更长的视频序列输入。效果图如下。从左到右,表示图像的标记数(tokens)分别为 490、154、18 和 6。
参考文献:
[10] Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. In The Eleventh International Conference on Learning Representations, 2022.
[71] Xirui Li, Chao Ma, Xiaokang Yang, and Ming-Hsuan Yang. Vidtome: Video token merging for zero-shot video editing. arXiv preprint arXiv:2312.10656, 2023.

● 核心公式:
- ViT 中变压器每一层合并tokens 的
r
r
r 指数按以下公式计算(
r
r
r 越大表示合并的力度越大):
r = ( 1 − ratio ) ⋅ ( W ⋅ H / P 2 ) / L r=(1-\text{ratio})\cdot(W\cdot H/P^2)/L r=(1−ratio)⋅(W⋅H/P2)/L
其中 W, H 是输入图像的宽度和高度,P 是 patch 大小,L 是 transformer 中的层数,ratio 是要保留的 tokens 的比例。合并均匀分布在 transformer 的所有层上。
- 一旦 tokens 被合并,它们实际上携带了多个输入 patch 的特征。因此,合并后的 tokens 在 softmax attention 中的影响较小,公式如下:
A = softmax ( Q K ⊤ d + log s ) \mathbf A = \text{softmax}(\frac{\mathbf Q \mathbf K^{⊤}}{\sqrt{\mathbf d}}+\text{log}\,\mathbf s) A=softmax(dQK⊤+logs)
其中 s \mathbf s s 是 tokens 合并后所表示的 patch 数量。在
AuroraCap中进行帧级 tokens 合并。
● 实现效果: 通过逐步结合在 transformer 中类似的 tokens,减少了通过 ViT 模型的 tokens 数量,最终提高了现有 ViT 模型的吞吐量。
● 算法步骤:
- 交替地将 tokens 划分为两个大小大致相等的集合 A A A 和 B B B。
- 对于集合 A A A 中的每个 token,根据 attention block 中的关键特征的余弦相似度,计算 token 与集合 B B B 中每个 token 的相似度。
- 使用二部软匹配(bipartite soft matching)算法,然后选出最相似的 r r r 对。
- 使用加权平均值合并这些 tokens,并记录大小。
- 将两个集合 A A A 和 B B B 重新连接在一起。
● 个人理解:

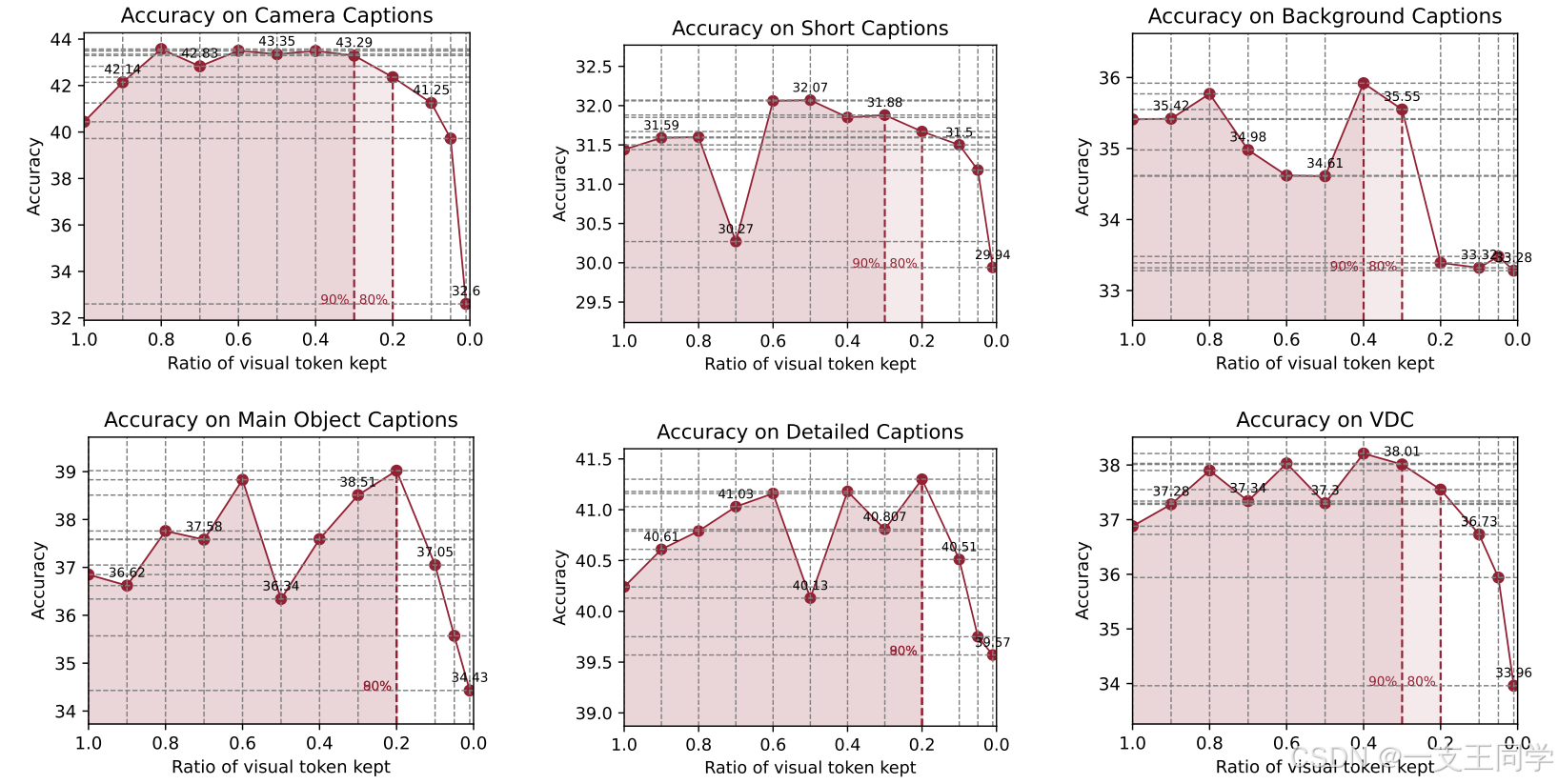
● 实验结果: 即使只有 0.2 的 visual tokens 保持率,大多数模型也保持了令人满意的性能(>80%)。由于 AuroraCap 专注于空间视觉tokens 的合并,所以时间特征为 tokens 的合并引入了额外的复杂性,导致最佳性能可能出现在中间。
5 现存问题二和已有解决方案
● 本文给出了几个广泛使用的基准的结果,如表 1 所示,但发现现有的视频理解基准要么是基于问题-答案的[11,14,36,114,134,137,140],不能证明详细的描述能力,要么提供的描述太短,只有几个单词[11,140]。一些大规模数据集专注于特定领域,如以自我为中心的[41]或包含低质量的视频和注释[5]。

6 本文的第二个创新点
● 我们构建了 VDC(Video Detailed Captions,视频详细字幕)基准,它包含超过 1000个高质量的视频字幕对,涵盖了广泛的类别,由此产生的字幕包含了丰富的世界知识、对象属性、摄像机运动,以及重要的、详细和精确的事件时间描述。我们利用 GPT-4o 作为我们的 recaption 助手(即提取字幕的助手),采用分层提示设计(来提取字幕)。
● 为了从视频中保留尽可能多的信息并保持时间一致性,本文实现了一种稠密帧提取策略(dense-frame extraction strategy)。使用密集的帧作为输入,尽管对整个视频进行了描述,但也从不同方面生成了高质量的字幕,包括客观事实、背景、摄像机角度和运动。采用人工质检的方式来保证视频字幕的质量。虽然现有的视频字幕数据集[19,51,61]提供了结构化的字幕,但 VDC 是第一个专注于详细视频字幕的基准,比其他基准提供了更长的和更详细的字幕,如表 1 和下图所示(每一张图片的视频字幕描述都很详细)。

● 【简述一下其他相关数据集的工作】为了保证基准测试的可靠性,保持高视频质量、均衡的数据分布和内容复杂度至关重要。Panda-70M[20] 提供了一个高分辨率、开放域的YouTube视频数据集,包括野生动物、烹饪、体育、新闻、电视节目、游戏和3D渲染的各种一分钟剪辑,非常适合研究复杂的现实世界场景。此外,用户上传的平台如 Mixkit[95]、Pixabay[101] 和 Pexels[100] 提供了大量具有美学吸引力的视频,以最小的过渡和更简单的事件提供了风景和视觉上令人愉快的人类活动。Ego4D[40] 通过关注以自我为中心的人类活动和自动驾驶场景来补充视频源,确保对真实世界场景的全面覆盖。
● 【本文的数据集工作——数据源与采集】为了缓解这些候选视频之间的内容同质性(注意,作者提到了“候选”两字。也就是说,作者的数据集来自于以上数据集),并保持最终数据集的多样性,受 ShareGPT4Video [19]的启发,我们在各种视频源上建立了 VDC。请注意,在 VDC 构建中使用的视频不包括在 AuroraCap 的训练数据中。为了保证数据分布的均衡,我们将 Panda-70M [20], Ego4D [40], Mixkit [95], Pixabay [101], Pexels[100]进行了等比例的视频分配,如表 5 所示。我们首先将视频分割为片段,并应用密集帧提取。
参考文献:
[19] Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions. arXiv preprint arXiv:2406.04325, 2024.

● 【本文的数据集工作——构建方案】另外,我们还开发了一个结构化的详细字幕构建管道(pipeline),以从各种角度生成额外的详细描述,与之前的基准相比,大大扩展了长度并增强了丰富性。我们遵循(Follow)了 [51] 的工作,VDC 中的结构化字幕不仅包括简短而详细的字幕,还包括三个额外的类别:(1)主体字幕,全面分析了主体的动作、属性、交互和跨帧运动,包括姿态、表情和速度的变化;(2)背景说明,提供背景的详细描述,如物体、地点、天气、时间、动态要素;(3)相机说明,详细说明相机(camera)的工作状态,包括镜头类型、角度、动作、过渡和特效。
参考文献:
[51] Xuan Ju, Yiming Gao, Zhaoyang Zhang, Ziyang Yuan, Xintao Wang, Ailing Zeng, Yu Xiong, Qiang Xu, and Ying Shan. Miradata: A large-scale video dataset with long durations and structured captions. arXiv preprint arXiv:2407.06358, 2024.
● 【本文的数据集工作——构建技术】为了生成详细、细粒度和准确的字幕,我们利用 GPT-4o 来生成视频描述(主要通过利用密集的视频帧来获得字幕)。我们观察到,在一轮对话(conversation)中生成所有的字幕通常会出现幻觉。为解决这个问题,本文设计了一种分层提示策略,在两轮对话中有效地获得准确的结构化字幕和详细字幕:(1)结构化字幕生成和 (2)详细字幕集成。在第一轮中,提示(prompt)简要介绍了结构化字幕之间的区别,并将密集的视频帧作为输入,生成简短字幕、主要对象字幕、背景字幕、摄像机字幕和详细字幕。在第二轮中,生成的字幕作为参考。第二轮提示(prompt)指导 GPT-4o 在初始说明的基础上增强详细说明,在不引入新的实体或关系的情况下确保一致性,并产生生动、吸引人和信息丰富的描述。结构化详细字幕的整个提示模板可以在 附录S11 中找到。最后,我们进行了人工审查,以纠正幻觉和补充遗漏的视觉元素。
● 附录S11:
遵循 [51] 的工作,我们利用 LLM 来生成结构化的详细字幕。给定一个输入视频,LLM 返回5个详细的字幕,包括摄像机字幕、简短字幕、背景字幕、主要对象字幕和由我们设计的提示模板指导下的整个视频的详细字幕。
如下图所示,SYSTEM是系统指令。第一个User对应的段落 是提供给 GPT-4o 的输入,第一个GPT-4o对应的段落 是 GPT-4o 的输出,是 “结构化字幕”。第二个User对应的段落 是提供给 GPT-4o 的第二次输入(会把之前 GPT-4o 生成的的“结构化字幕”加进来),第二个GPT-4o对应的段落 是GPT-4o的第二次输出,是 “详细字幕”。
⭐️⭐️完整的提示模板如下:

● 【实验结果】基于这种分层提示策略,VDC 可以捕捉视频的丰富的各种细节,减少幻觉。图 1 中的可视化表示展示了 VDC 的视频持续时间分布。超过 87% 的视频持续时间从 10K 到 12K 帧(对应的就是 10s 到 60s),而 1% 的视频持续时间超过 60 秒。只有 13% 的视频持续时间少于 10秒。如表 1 所示(在上文中),VDC 中详细描述的平均长度明显长于以前的基准测试。图 2 显示了在 VDC 中出现的结构化字幕的长度分布,详细的字幕平均超过 500 个字。

7 现存问题三和已有解决方案
● 评估视频字幕不仅需要评估字幕的质量,还需要灵活地评估视频与字幕的对齐程度。BLEU[99]、CIDEr[127] 和 ROUGE-L[76] 等指标主要是为简短的字幕设计的,并且严重依赖于基于单词级别的频率对齐。而鉴于大型语言模型(LLM)的高级语义理解能力,VideoChatGPT[64]提出使用 LLM 作为评估助手,直接判断整个预测字幕的正确性并进行评分。然而,如表 6 所示,我们的实验表明,在处理详细的字幕时, LLM 的直接应用很难准确区分各种预测字幕的准确性,不能有效评估详细描述的精度,并且表现出分配不成比例的低分数的趋势。也就是说,各个指标的分差太大了,比如 VDD、CIDEr、Mettor 等。
原文: the direct application of LLM struggles to accurately distinguish the correctness of various predicted captions, fails to effectively evaluate the precision of detailed descriptions, and exhibits a tendency to assign disproportionately lower scores.

8 本文的第三个创新点
● 为应对这些挑战,本文提出 VDCscore,一种新的描述评估指标(即一种新的量化指标),通过评估简短的视觉问答对,利用大型语言模型(LLMs)的可靠性【作者在前面说别人直接应用 LLMs 作为评估不太行,拿这里他也用了,那他是不是“直接应用”呢?后文揭晓】。首先使用 LLMs 将 标准描述分解为一组简洁的 问题-答案对,然后从预测的描述中生成相应的回答。最后,使用 LLMs 来评估每个回答的准确性,以提供一个总体得分。
● VDCscore 的核心思想是将长细节字幕分解为多个短问答对,平均 每对的评价分数 作为最终结果。VDCscore 的设计包括:(1)标准问题-答案对的抽取,(2)回复的答案的生成和(3)答案的匹配。
- 如图
3所示,我们首先使用GPT-4o*从详细的标准字幕中生成 “问题-答案对”。为确保生成的 “问题-答案对” 能从原始字幕中捕获尽可能多的信息而促进 LLMs 的准确评估,我们限制了生成的 “问题-答案对” 的数量,并施加了具体的指导方针:问题必须是开放式的,答案应该简洁,并与问题直接相关。为了进行公平的比较,并减轻因为同一字幕生成不同 “问题-答案对” 而产生的潜在变化,我们为VDC中的所有字幕预先生成了一组标准化的 “问题-答案对”(即 “①和②”)。 VDCscore随后通过利用标准的 “问题-答案对” 来分析预测的字幕。即给GPT-4o提供详细的预测字幕(即“generated caption”),并仅根据这些字幕生成答案。为减轻 标准答案和 预测答案 之间的长度差异所引起的偏差,还施加了约束(在提示模板中体现),确保回答仅限于简洁的句子或短语。因此,对于每一对标准字幕和预测字幕,我们得到一组 <问题,正确答案,预测答案> 三元组。遵循 Video-ChatGPT[64] 的工作,我们要求GPT-4o为每个三元组输出两个分数:一个是答案的正确性(correctness),另一个是答案的质量(quality)。将正确性得分和质量得分分别求平均,得到最终的准确率和得分。另外,在实验过程中,当我们使用两个相同的字幕作为输入时,VDCscore返回了100%的准确率,表明了该方案的可行性(feasibility)和可靠性(reliability)。
(图3左边的 “GT caption” 就是 “ground-truth caption”,即标准的字幕。“①和②” 就是通过 GPT-4o* 从“GT caption” 中提取的一个 “问题-答案对”(其中,“①” 是问题,“②” 是正确答案)。再接着将 “①”和“generated caption” 提供给 GPT-4o* 来生成 “④”,即预测答案 )
GPT-4o*:gpt-4o-2024-08-06, the latest GPT-4o version in September, 2024.
参考文献:
[64] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023.

● 所使用的提示模板和其他示例在附录 S12 和 附录 S18 中提供。
● 附录S12:
如下图所示,SYSTEM是系统指令,用于约束 GPT-4o 的行为模型。第一个User对应的段落 是提供给 GPT-4o 的输入,第一个GPT-4o对应的段落 是 GPT-4o 的输出,是 “20个“问题-答案对””。第二个User对应的 是 人工质检。
● 附录S18:
如下图所示,SYSTEM是系统指令,用于约束 GPT-4o 的行为模型。第一个User对应的段落 是提供给 GPT-4o 的输入,第一个GPT-4o对应的段落 是 GPT-4o 的输出,是 “预测的准确性和得分””**。


● 【实验结果】我们还使用 Elo ranking 进行了一项人类研究(使用 AuroraCap 模型)。如图 5 所示,VDCscore 与 “VDD 和 ROUGE指标” 相比,与人类评价结果的相关性更好。

● 附录 S15:
使用 Elo raking 系统来评估和排序 AuroraCap 和各种模型的方法步骤:
- 对于所有参与 ELO ranking 的模型,我们收集每个视频的输出字幕。
- 如上图所示,我们开发了一个前端工具,为同一视频随机选择由两个不同模型生成的字幕。在没有透露模型 IDs 的情况下,人类评估者随后选择了他们发现的更好的字幕。
- 我们记录对比结果,并根据下表中的参数计算 ELO 值。
- 在图
5中,我们计算了不同指标和人工 ELO 值之间的皮尔逊相关性,最终表明我们提出的 VDC 指标最接近人工评估。


9 其他重要实验结果
● 【AuroraCap 在 image captioning 上的性能】下表是在 Zero-shot 设置下,AuroraCap 与基于 LLMs 的 SoTA 方法在 图像字幕基准 上的比较,除了 k-shot,其中 k 被标记为上标。GPT-4V CIDEr 的结果来自[119],我们所知道的唯一参考,但看起来奇怪的低。∗ 标记了经过微调的结果。粗体中的分数表示在 Zero-shot 设置下的最佳表现。

● 【AuroraCap 在 video captioning 上的性能】下表是 AuroraCap 与 SoTA 方法在现有视频字幕基准上的比较。AuroraCap 大大优于最近的其他方法。

● 【AuroraCap 在 video question answering 上的性能】下表是 AuroraCap 与 SoTA 方法在 Zero-shot 设置下视频问答和分类基准上的比较。对于所有列出的模型,预训练的 LLMs 大小为 7B。

● 【AuroraCap 在 作者自己构建的数据集VDC 上的性能(用的也是作者自己构建的指标VDCScore)】下表是 AuroraCap 与基于 LLM 的基线方法在 zero-shot 结构化字幕设置下 VDCscore 上的比较。我们考虑了详细字幕、简短字幕、背景字幕、主要物体字幕和摄像机字幕的 VDCscore。

● 【AuroraCap 在 VDC 上的性能(用的指标是VDCScore)】下图是在 VDC数据集 上输入不同数量 visual tokens 的各种模型的比较。对于 Gemini-1.5-Pro,我们只报告性能。AuroraCap 取得了比所有其他模型更好的VDCscore。

● 【AuroraCap 在 VDC 上的性能(用的指标是VDD!!)】下图是在 zero-shot 结构化字幕设置下,AuroraCap 与基于 LLM 的基线方法在VDD[81]上的比较。我们也是考虑了详细字幕、简短字幕、背景字幕、主要物体字幕和摄像机字幕的VDD[81]。

● 最终说明了个啥: 以上实验充分说明了 AuroraCap 的有效性,不管是在别人的数据集上,还是自己构建的数据集上,也不管是别人的评价指标(ps:但好像在 VDD指标 上的效果要稍微弱一点),还是自己的评价指标。
10 总结
● 本文首先介绍了 AuroraCap,一种基于大型多模态模型的高效视频细节描述器。通过利用 tokens 合并策略,在不影响性能的情况下显著降低了计算开销。本文还提出了 VDC,一个新的视频详细描述基准,旨在评估视频内容的全面和连贯的文本描述。为了更好地评估,本文提出 VDCscore,一种新的基于分而治之策略的 LLMs 辅助评价指标。对各种视频和图像描述基准的广泛评估表明,AuroraCap 取得了有竞争力的结果,甚至在某些任务中超过了最先进的模型。还进行了彻底的消融研究,以验证 tokens 合并和模型其他方面的有效性。我们发现,当前模型在性能和输入 tokens 规模之间的权衡方面表现不佳。此外,在相机处理和详细的字幕制作方面仍有改进的空间。
11 参考文献
169 篇
⭐️ ⭐️ 写于2025年3月11日 21:16 教研室工位


















 8914
8914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











