




 文章详细介绍了基于Anchor的目标检测方法,包括AnchorBase的设计思想,如锚点、步长和长宽比的选择,以及其优缺点。接着讨论了AnchorFree方法,如基于角点、中心点和全卷积的方法,如CornerNet和FCOS,强调了它们如何避免Anchor带来的问题。最后,文章提到了MaskR-CNN的分割方法及其改进的RoIAlign技术,用于更精确的像素级预测。
文章详细介绍了基于Anchor的目标检测方法,包括AnchorBase的设计思想,如锚点、步长和长宽比的选择,以及其优缺点。接着讨论了AnchorFree方法,如基于角点、中心点和全卷积的方法,如CornerNet和FCOS,强调了它们如何避免Anchor带来的问题。最后,文章提到了MaskR-CNN的分割方法及其改进的RoIAlign技术,用于更精确的像素级预测。
目录
1. anchor base
什么是anchor-based的目标检测方法呢?如果要让你定一个规则去一个图片上框一个物体,你会怎么做呢?最简单,最暴力的方法,当然就是”定步长搜索法“啦,不知道定步长搜索法是什么,没关系!先让我们轻松一下,假设你的图片中有一只猫,你需要把它从图片中框出来

对于这个问题,一个最简单的思考方式是。你以16个像素为步长,把图片划分成为许多的16×16的许多的小格子(至于为什么是16,我们后面再说)。想象不出来吗?那小时候的拼图你玩过吗?大概就是那种感觉。运气好的话,你家的猫应该大部分的身体恰好出现在某一个16×16的小框里。没错这样我们就至少有一个框可以把你的猫"框"住了。

所以,你设计好的第1个定步长搜索物体的算法应该是下面这个样子:
在图片中以一定的步长画许多个具有固定高度和宽度的框,这里我们先设置为矩形。接下来就希望你的小猫刚好躲在其中的一个框内,如上图。这样你就能把你的猫从图片中框出来了。这时候,对你而言,只需要做两件事:
step1 按照网格的生成规律,计算所有生成框的四个点的坐标
step2 对每个框,判断其中是否包含”猫",将包含猫的框的坐标返回,这时候你就得到了最终的结果
像上面那么扫一圈,好像是能够有个框和这个目标挨着个边,但是问题来了,如果你的物体老大老大了(比如你家的猫猫在图中的”占比“太大了),小框框不住咋办?

牛逼的同学这时候就要站起来了,"老师,小的框搞不定,那就换大的“ , 嗯,好像最先进的科学家也没有比你这哥们聪明多少的样子,于是乎,我们就用个大点的框扫一圈,用一个小一点的框扫一圈...
什么意思呢?意思就是,在上一轮的“网格生成“过程中,每个网格都会有一个自己的中心,每个小格子都可以抽象成为在自己的中心生成了一个指定大小为16个像素的矩形框,在这里,我们把这些中心称之为”锚点“,把每个锚点处的框称之为”锚框“。

现在,对于每一个锚点,为了检测小猫,你需要在每一个锚点生成一个小框,而为了检测大猫,你可以在每个锚点的位置设置一个尺度更大的框,试图用来框住尺寸比较大的物体:

这时候你的目标检测算法应该会设计成如下这个样子。
在图片中以一定的步长选取一定的锚点。以每个中心点为框的中心画多个具有固定高度和宽度的框,接下来就希望你的小猫刚好躲在其中某个尺度的一个框内,这样你就能把你的猫从图片中框出来了。
这里值得注意的有三点:
1. 相比于上一次设计的算法,现在我们要求等距生成的内容不再是框本身,而是锚点,我们依旧要求锚点是以16为步长,但是现在我们不要求框是”一个挨着一个的“,我们只要求在每个锚点处生成固定尺寸的框
2. 框的高度和宽度,与你设定的生成框的中心的步长并不需要一致。其实最好是怎么符合物体在图片中的分布怎么来?(大名鼎鼎的yolo就是这么设计的)
3. 始终注意,我们的任务是找出图中的物体,框的设计规则始终只是我们自己的一种”设计“
然后牛逼的学生总是有很多问题,”老师,你说这个猫,他横着趟和竖着趟,我用同样尺度的框合适么?“ ,事实上是这样的情况在现实生活中是普遍存在的,你不可能指望用正方形的框框住所有的物体,于是先进的科学家们说,同学们注意了哈,我要开始变形了!于是乎,著名的anchor-based方法就这么诞生了.
简单的来说,他们的处理方法是,对于每一个固定高度乘宽度的正方形的框,在保持面积不变的情况下,我可以把框的高度和宽度设置成不同的比例(毕竟你家的猫和照相机距离不变的时候,只会躺着,或者站着,总的面积是不变的嘛,不会面积忽然变大或者变小....),示意如下图:

这里,我们仍然考虑以16为步长生成锚点,此时,假设图中黄色的锚点处原本会生成一个黄色框示意的锚框,原本是无法框住物体的,但是,如果我们不仅生成这个面积的正方形锚框,还同时在这个锚点处生成一个面积和它一致,但是长宽比为2:1的框,则有可能将猫给框起来了
说句题外话,这里为了展示只画了几个锚框,实际上锚点以16位步长是非常密集的,下图是真实的样子)

在这样的基础之上,最终就得到了如下的anchor base的Anchor的生成方法。
在图片中以一定的步长选取锚点。以每个中心点为框的中心设计多个具有固定高度和宽度的框,并对于每一个面积的框,衍生出三种不同长宽比的新的框,(以下还是胡说八道)接下来就希望你的小猫刚好躲在其中某个尺度的某一个长宽比的一个框内,这样你就能把你的猫从图片中框出来了。
网上对这个过程解释最详细的一张图是这样的:
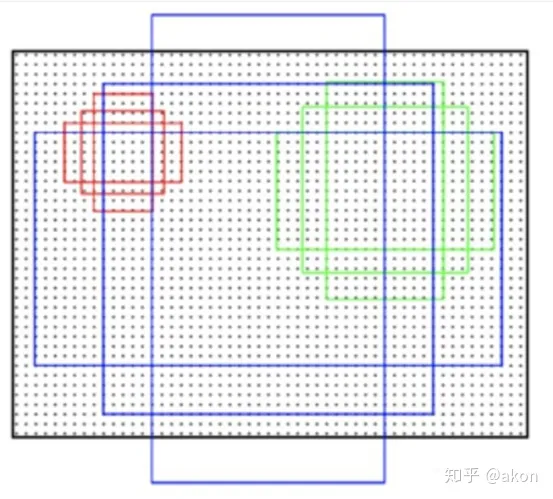
本质而言,其实这张图具有非常的误导性,仔细解释一下应该是这么理解的:
step1 背景是一张图片,在图片中密集的黑色点点就是按照定步长确定的”锚点“
step2 在每个锚点处,都会生成三种尺寸的正方形的框(红色、绿色、蓝色中的正方形框)
step3 对每个正方形框,会生成两种扩展尺度的框(每种颜色的另外两个长方形)
step4 所以, 在每个锚点处都会生成9个anchor
所以大概是这么个样子
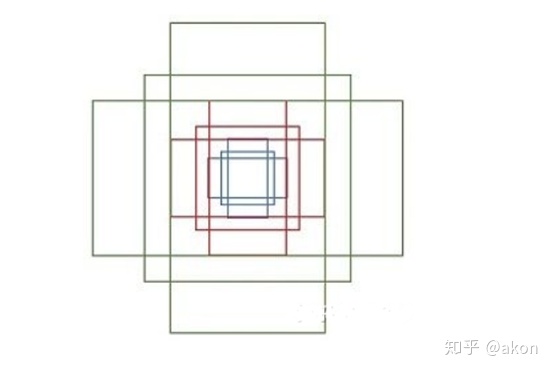
Anchor的生成过程和深度学习没有任何的关系,他的本质只是你设定好一些规则,并依据这些规则,在图像中生成不同尺寸,不同长宽比的框,并希望这些框能够最终覆盖你的物体。
Anchor base的缺点
1. 检测表现效果对于锚框的尺寸、长宽比、数目非常敏感,因此锚框相关的超参数需要仔细的调节。
2. 锚框的尺寸和长宽比是固定的,因此,检测器在处理形变较大的候选对象时比较困难,尤其是对于小目标。预先定义的锚框还限制了检测器的泛化能力,因为,它们需要针对不同对象大小或长宽比进行设计。
3. 为了提高召回率,需要在图像上放置密集的锚框。而这些锚框大多数属于负样本,这样造成了正负样本之间的不均衡。
4. 大量的锚框增加了在计算交并比时计算量和内存占用。
2. anchor free
基于anchor free的目标检测总共有三种方法
(1)基于角点的anchor free目标检测
(2)基于中心点的anchor free目标检测算法
(3)基于全卷积的anchor free目标检测
(1)基于角点的anchor free目标检测
基于角点的目标检测方法通过组合从特征图中学习到的角点对, 来预测边框. 这种方法不需要设计锚框, 减少了对锚框的各种计算, 从而成为生成高质量边框的更有效的方法. 基于角点的anchor free目标检测模型主要有CornerNet和CornerNet的优化CornerNet-Lite.
CornerNet网络的整体思路是,首先通过Hourglass Network网络进行特征提取,紧接着将网络得到的特征输入到两个模块:Top-left Corner pooling和Bottom-right Corner p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8836
8836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









