









一、实现例子
李航《统计学方法》第二版p40 例2.1
正例:x1=(3,3), x2=(4,3),
负例:x3=(1,1)
二、代码
1、代码一:代用类似随机梯度下降法,但是总感觉这个代码没有一个退出的判断条件,只是说训练了多少次就退出。
import numpy as np
import matplotlib.pyplot as plt
p_x = np.array([[3,3], [4,3], [1,1]])
y = np.array([1,1,-1])
index = [0, 1, 2]
plt.figure()
# 画出这些点
for i in range(len(p_x)):
if y[i] == 1:
'''
‘o’代表每个数据点用小圆圈表示,且数据点之前不用线连接,看起来很像散点图
'ro'代表小圆圈是红色的
'-'就是最普通的线型,数据点之间用实线连接。
'''
plt.plot(p_x[i][0], p_x[i][1], 'ro')
else:
plt.plot(p_x[i][0], p_x[i][1], 'bo')
# 初始化参数w,b
# 随机初始化参数
w = np.random.rand(2)
print(w)
b = np.random.rand(1)[0]
print(b)
delta = 0.01
# 执行感知机原始形式的算法
# 定义训练50次结束
for i in range(50):
# 获取随机下标
k = np.random.choice(index)
y_predict = np.sign(np.dot(w, p_x[k]) + b)
print("train data:x:({}, {}) y:{} ==>y_predict:{}".format(p_x[k][0],p_x[k][1],y[k],y_predict))
# 如果分类错误(误分类点),更新权重
if y[k] != y_predict:
w = w + delta * y[k] * p_x[k]
b = b + delta * y[k]
print("update weight and bias:")
print(w[0], w[1], b)
print("stop training :")
print(w[0], w[1], b)
# x 取0,10之间的数值,然后求出对应的y的值,得到最后的直线
line_x = [0, 10]
line_y = [0, 0]
for i in range(len(line_x)):
line_y[i] = (-w[0] * line_x[i] - b) / w[1]
plt.plot(line_x, line_y)
plt.savefig("Perceptron1.png")
2、代码二:这个代码也是定义训练的次数,但是会判断如果没有一个点是错误分类的话就退出。没有随机选取样本,每次都是循环整个样本,当样本点很多的时候这个算法就会很慢。
import numpy as np
import matplotlib.pyplot as plt
p_x = np.array([[3, 3], [4, 3], [1, 1]])
y = np.array([1, 1, -1])
plt.figure()
for i in range(len(p_x)):
if y[i] == 1:
plt.plot(p_x[i][0], p_x[i][1], 'ro')
else:
plt.plot(p_x[i][0], p_x[i][1], 'bo')
# 初始化参数w,b
# 随机初始化参数
w = np.random.rand(2)
print(w)
b = np.random.rand(1)[0]
print(b)
delta = 0.1
for i in range(100):
choice = -1
for j in range(len(p_x)):
if y[j] != np.sign(np.dot(w, p_x[j]) + b):
choice = j
break
if choice == -1:
break
w = w + delta * y[choice]*p_x[choice]
b = b + delta * y[choice]
line_x = [0, 10]
line_y = [0, 0]
for i in range(len(line_x)):
line_y[i] = (-w[0] * line_x[i]- b)/w[1]
plt.plot(line_x, line_y)
plt.savefig("picture.png")
三、训练结果
stop training :
0.025979958719965418 0.07198673084968427 -0.09954039539041126
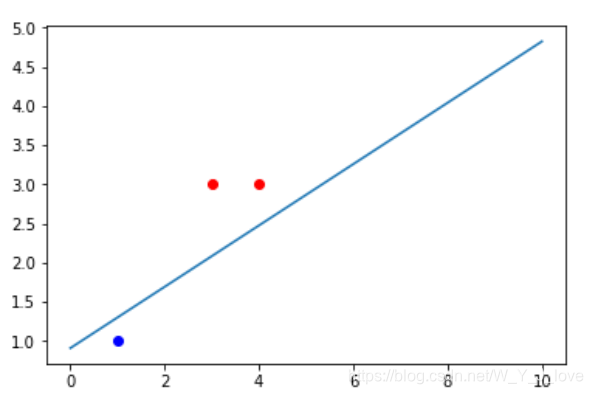
四、测试
由于感知机只要找到一个超平面能够把训练数据分开就可以了,并不是要找到最优的超平面,所以对于该算法采用不同的初始参数或选取不同的误分类点(代码一随机选取),都会产生不同的分类超平面。
在测试的过程中也会产生偏差。
test_data = [2, 4]
test_y = 1
test_predict = np.sign(np.dot(w, test_data) + b)
print("test data:x:({}, {}) y:{} ==>y_predict:{}".format(test_data[0],test_data[1],test_y,test_predict))
测试结果
test data: x:(2, 4) y:1 ==>y_predict:1.0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









