









1.调用self._get_anchor_wh()函数得到anchor_wh: (tensor) anchor wh, sized [#fm, #anchors_per_cell, 2].
每个特征图上的9种不同anchor boxes的宽、高
以下操作对于某个特定尺度的特征图:
2.根据特征图尺寸和出入图像尺寸计算放大倍数grid_size
3.在特征图的每个像素点上,以特征图像素数为单位,计算该尺度特征图上网格中心点的坐标(+0.5),并对于每个坐标点,重复9次
然后对于每个中心点位置坐标,横纵坐标值都要乘以从特征图到输入图像的放大倍数 xy=sized [fm_h,fm_w,9,2]
4.对应于原图中的像素度量,在一个尺度的特征图上,关于anchor boxes的宽和高,只会得到9*2个数值,将这9*2个宽和高对应到
特征图上每个cell的中心点像素坐标xy就可以在特征图中的每个位置得到9*4个坐标值
xy-wh/2 sized[fm_h,fm_w,9,2] xy+wh/2 sized[fm_h,fm_w,9,2]
在最后一个维度上进行concatenate box sized[fm_h,fm_w,9,4] xmin_ymin_xmax_ymax
boxes.append(box.view(-1,4)) boxes.append([fm_h*fm_w*9,4])
在所有尺度的特征图上得到default boxes/anchor boxes的坐标值后,得到boxes列表中包含7个元素,每个元素是[fm_h[i]*fm_w[i]*9,4]的tensor
boxes 是 a sequence of tensor,作为torch.cat的输入参数,在第0个维度上进行concatenate
boxes:output tensor (fm_h[0]*fm_w[0]*9+fm_h[1]*fm_w[1]*9+fm_h[2]*fm_w[2]*9+fm_h[3]*fm_w[3]*9+fm_h[4]*fm_w[4]*9+
fm_h[5]*fm_w[5]*9+fm_h[6]*fm_w[6]*9,4)
一、训练
假设是SSD300模型
SSD300对于6种不同尺度的特征图上分别产生不同面积anchor area的anchor boxes
38*38,19*19,10*10,5*5,3*3,1*1
其中boxes中有7个数是对应到每张特征图上的[anchor_min,anchor_max]最短边和最长边的长度
当前尺度特征图上的最长边等于下一尺度特征图上的最短边,第一张特征图预测小物体,故而边长短
aspect ratios中有6个元素,每个元素对应于每个尺度特征图上的宽高比
比如,对于第一个尺度上的特征图,aspect ratio=(2,)对应4个不同的包围框
[anchor_min,anchor_min],[anchor_min/sqrt(2),anchor_min*sqrt(2)]
[anchor_min*sqrt(2),anchor_min/sqrt(2)],[sqrt(anchor_min*anchor_max),sqrt(anchor_min*anchor_max)]
对于每个尺度上的特征图,会产生两个aspect ratio=1:1的anchor boxes,会有4-1=3或者6-1=5个相同anchor_area面积的anchor boxes
其中这些面积为 pow(anchor_min,2)
对于每个尺度特征图上的anchor area计算,公式如下:
SSD300在程序实现中,第一个尺度的特征图的anchor area面积是单独计算的
在之后的第二个尺度的特征图一直到第6个尺度的特征图上,遵循论文中的公式
设定最小尺度 smin=0.2,最大尺度 smax=0.9 特征图数量 m=5
k=1 s1=0.2+0.7*0=0.2 anchor_area=pow(anchor_min,2)=pow(s1*300,2)=pow(60,2)=60*60
k=2 s2=0.2+0.7*1/4=0.375 anchor_min=s2*300=112.5 向下取整 111
k=3 s3=0.2+0.7*2/4=0.55 anchor_min=s3*300=165
k=4 s4=0.2+0.7*3/4=0.725 anchor_min=s4*300=217.5
k=5 s5=0.2+0.7*4/4=0.9 anchor_min=s5*300=270
steps = (8, 16, 32, 64, 100, 300)
aspect_ratios = ((2,), (2,3), (2,3), (2,3), (2,), (2,))
对于input image:300*300,将输入图像经过一系列的卷积层提取特征后,将得到6个不同尺度的特征图
比如对于38*38的特征图,首先根据step(特征图相对于原始输入图像的缩小倍数)先对于特征图中的每个像素点计算出一个中心点坐标:
在input image尺度上的像素点位置坐标=(在特征图尺度上的像素点位置坐标+0.5)*steps[0],这样对于特征图中的每个像素值都将会得到2个中心点坐标(input image尺度上) cx、cy, sized(38,38,2),由于在特征图中的每个像素点处都会产生6个不同的anchor boxes,但是这6个anchor boxes的中心点坐标相同,故对坐标tensor进行expand操作,得到 cx,cy sized(38,38,6,2),这只是得到了anchor boxes的中心点位置坐标,还要根据宽高来得到anchor boxes的宽高
在同一个尺度的特征图上,anchor boxes的宽和高的大小只有6种(或者4种),只是将这些长宽在整个特征图上的所有像素点处进行了一次遍历(准确来说,是在特征图所有像素点中心点位置坐标对应到input image尺度上的坐标进行遍历),得到sized (38,38,6,4)
在每个尺度的特征图上进行遍历后,对于SSD300,会得到8732个anchor boxes,
38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732
anchor_boxes sized (8732,4)这些坐标都是对应到input image像素坐标的尺度上
计算每个anchor boxes与input image 的ground truth的IOU值
得到iou矩阵 sized(8732,#obj),假设当前input image中有2个ground truth包围框
会得到8732*2的IOU矩阵,然后根据所计算得到的IOU值分类出positive examples和negative examples
比如阈值大于0.5的记为正样本,否则即为负样本(或者使用困难样本挖掘)
当然,对于8732个anchor boxes进行正负样本的二分类是完全基于anchor boxes与ground truth boxes之间的IOU值确定的
这一过程要保证每个正样本的anchor boxes只能对应于一个ground truth包围框,一个anchor boxes不能同时回归两个ground
truth boxes
从而对于每个anchor boxes ,有一个localization target和classification target
比如,
1.当前anchor boxes是那个类别为车的正样本,
(1)则它的localization target就是那个车的ground truth包围框对应到input image 尺度上的(cx,cy,w,h),当然由于CNN filters 输出值有限,故而对target coordinate进行编码,
(ground_truth_boxes-anchor)/anchor作为在特征图上应用3*3卷积核的输出目标,
(2)它的classification target是21维的one-hot向量,对于VOC数据集而言是21类,eg.[0,1,0,0,0,0,……0]
网络模型对于这个anchor boxes的训练目标就是让它的坐标值与target coordinates无限接近,让它的classification vector与true label无限接近
2.当前anchor boxes是类别为背景的负样本
(1)负样本没有localization target,在初始的anchor boxes坐标的基础上,无论之后的训练过程中,对filter滤波器参数更新的过程中,这个anchor boxes的坐标可能发生变化,但是不管它怎么变。
(2)负样本的classification target是[1,0,0,0,……],分类类别的ground truth是background
在训练的过程中,对于正负样本都要通过CNN filter计算每个anchor boxes的分类向量和回归坐标,再根据每个anchor boxes计算得到的localization 和classification结果计算损失函数
对于正样本,计算loss=localization loss+classification loss
对于负样本,计算loss=classification loss
再根据loss函数更新CNN参数
训练过程中并不需要NMS。训练的意义在于,根据ground truth知道了哪些anchor boxes是正样本,哪些anchor boxes是负样本,(跟ground truth框的IOU值较大的是正样本,这些正样本必然与ground truth距离很近,用这些正样本的anchor boxes回归ground truth boxes更容易)
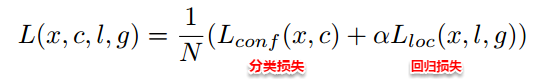


二、测试
对于输入图像,同样会产生6个不同尺度的特征图,其实,由于训练图像和测试图像的分辨率相同,训练图像上的那8732个anchor boxes的4个坐标值和测试图像中的8732*4个坐标值是一样的,只是测试过程中没有ground truth,网络会对者8732个框都预测出classification vector和localization tensor,再对于每一个anchor boxes,它的21维classification vector找到最大值,作为当前anchor boxes 的分类类别和confidence,去除那些分类类别为背景的anchor boxes,再设置confidence阈值将那些置信度低的bounding boxes去掉,得到所有具有confidence(大于一定阈值)的属于某个类别的bounding boxes,然后再遍历所有的类别,对于每个类别,使用 NMS,
NMS流程如下:假设有k个判定为当前类别的bounding boxes,先对k个bboxes的confidence进行从大到小的排序,之后,从第一个bbox开始,比较其confidence与剩下的所有k-1个bboxes之间的IOU,如果IOU大于一个较大的阈值,则认为这两个bboxes框出的是同一个物体,丢弃掉后面那些confidence 较低的物体;之后更新对于当前类别的bounding boxes的tensor(去除之前被丢弃掉的bbox和第一个bbox),更新confidence列表,之后对于剩下的bbox tensor中的第一个bbox进行相同的操作。
Note:整个SSD训练的过程实际上是先给出固定数量、尺寸、位置的anchor boxes,再根据ground truth boxes对anchor boxes区分出正负样本,再让anchor boxes无限逼近target localization和target classification,是希望anchor boxes做预测的。
而整个过程中,比更没有对于anchor boxes位置的迭代调整,而是网络的每次训练中,anchor boxes的位置坐标都是固定的,只是由于filter参数发生更新,对于anchor boxes产生的预测值输出也不同,从而一次次更加接近于ground truth。
训练过程不需要NMS,测试过程需要NMS

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









