







https://zhuanlan.zhihu.com/p/41825737 这篇知乎讲的很好。
cornerNet:ECCV 2018 oral
论文链接:https://arxiv.org/abs/1808.01244
代码链接:https://github.com/princeton-vl/CornerNet 是基于pytorch写的代码,之前老板也提到过,现在很多开源的paper代码都是在pytorch框架下实现的,pytorch的趋势很强呀。
深度学习中通常使用的防止过拟合的方法:https://www.cnblogs.com/unclelin/p/6384608.html
数据增强就是通过增大数据量的方式防止过拟合,cornernet中使用的数据增强策略包括:随机水平翻转,随机尺度变换,随机裁剪和随机色彩抖动(包括调整图像的明暗程度,饱和度和对比度),最后对输入图像使用了PCA。(作者应用的PCA策略来自于2012年的AlexNet,应用于分类任务中)
一、传统object detector
CornerNet将物体检测问题建模成检测图像中的关键点问题,作者所定义的图像中的关键点就是ground truth boxes的top-left点和bottom-right点,阅读论文中可以感受到,作者所使用的关键点检测和hourglass网络都来源于人体姿态估计(human pose estimation)。也就是说,作者将检测出图像中一个个包围框的问题转换成检测出一对对左上角点和右下角点的问题(必须成对出现,一对top-left点和bottom-right点确定了一个bounding boxes),只检测关键点,从而就可以避免设计anchor(因为设计anchor需要引入很多超参数,比如anchor的尺寸,面积等等),这种思路与以往所有的object detector物体检测器都不一样,因为之前按的object detector,现在state of the art中的物体检测方法,无论是one stage还是two stage,都非常依赖于对于anchor的设计(anchor可以理解为一系列的candidate boxes/default boxes),one stage method的密集检测其性能严重依赖于基于先验知识对于anchor的设计,而two stage method中的RPN也需要设计anchor,但是使用这种关键点的检测办法则完全避开了对于anchor的设计。而且corner同样属于one stage detector。
基于anchor的物体检测器会遇到的问题:首先必须在输入图像上产生大量数量的anchor boxes,才能保证最后的检测性能,这是因为检测框架中,将与ground truth boxes的overlap大于一定阈值的anchor boxes才会被认为是当前ground truth boxes的正样本,负责回归出ground truth boxes,也就是说,在RPN阶段(two stage detector)或者SSD阶段(one stage detector),必须产生足够多数量的anchor boxes以保证每个ground truth boxes都有一些anchor boxes与之对应,不然网络预测出那个anchor boxes的位置就会变得非常困难。这就意味着anchor boxes的总数量必须非常多,而往往与ground truth boxes的overlap大于某个阈值的正样本的数量是很少的,只占据所有anchor boxes数量的极小一个部分,则就会导致训练过程中严重的正负样本不平衡,解决这个不平衡的方法目前常用的有focal loss和OHEM(据说在物体检测中focal loss的效果不如OHEM好,而在语义分割中focal loss效果还是很不错的,这是我做实验的感悟)。

二、cornerNet网络结构
1.网络结构概述
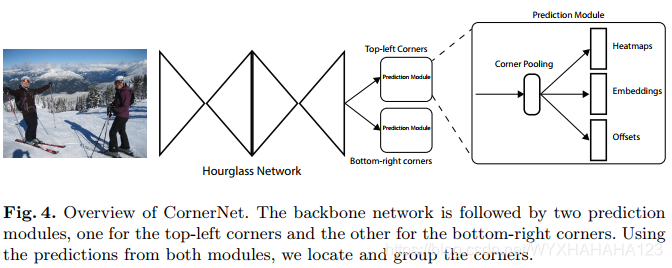
CornerNet对于每个前景类别(注意只有前景类别,没有背景类别)预测出两个heatmap,分别为top-left heatmap和bottom-right heatmap,对于一张输入图像,左上角点和右下角点的heat map shape都是 [height,width,num_classes],同时网络也会预测出两组embedding vector,也就是说对于左上角点和右下角点特征图上的每个位置,都会有一个N维的embedding向量,比如对于某个类别预测出来一系列的左上角点和右下角点,则它们之间如何确定一一对应关系以输出一个bounding boxes?这个时候就需要依赖于对应位置的一对embedding vector,看看哪一对embedding vector距离最近,则就将它们配对网络模型还会预测出一个offset,即位置偏移量的预测,用于对角点生成的bounding boxes进行位置微调。也就是说,cornernet网络最终的输出包含3个部分:heatmap,embedding和offset,最后再接上一个简单的后处理算法就可以得到bounding boxes。
cornerNet所使用的backbone是沙漏网络,将其提取到的特征图送入两个分支——左上角分支预测网络和右下角分支预测网络,每个角点网络都会有一个prediction module,在每个预测模块中,通过对特征图进行corner pooling,之后分别预测角点的heatmap,embeddings和offsets。这里只会使用最后一个尺度的特征图进行预测,并不会像SSD那样在多个不同尺度的特征图上预测。
2.检测——对角点
(1)heatmap loss,分母为所有gt boxes数,(在feature map所有点上使用,不只在ground truth点处使用)
对于左上角点和右下角点进行corner pooling之后的特征图,分别预测出heatmap,embeddings和offsets。以左上角点为例,heatmap shape为 h*w*C,C为前景类别数,每个通道上的ground truth是一个binary mask,表明当前位置上是否有左上角点。显然,这种情况下在每个类别的特征图上同样会有大量的像素点是负样本,但是即使把左上角点或者右下角点预测在正确角点的一定范围内,同样可以产生非常接近ground truth boxes的包围框,故而ground truth中并不是简单的0/1编码,而是对于在ground truth点周围的一定半径范围内,会产生以正确角点为中心的二维高斯分布,距离正确角点越近 ,则ground truth label越大,否则越小(但并不会完全等于0)

(2)offset loss,分母为所有gt boxes数,只在ground truth点处使用
首先明确offset的ground truth值是什么?这是因为为了减少计算复杂度,预测出的heatmap的特征图分辨率大多数情况下是小于输入图像的分辨率(相当于对输入图像进行下采样),而为原本的ground truth boxes便焦点编码到heatmap上的位置必须是整数点(通常是原始分辨率上的gt boxes坐标除以下采样倍数,再向下取整),故而编码后的位置坐标再映射回原来的输入图像,会不够准确,这时就会引入偏移量,故offset的ground truth 编码也是与heat map具有相同分辨率和相同通道数的,
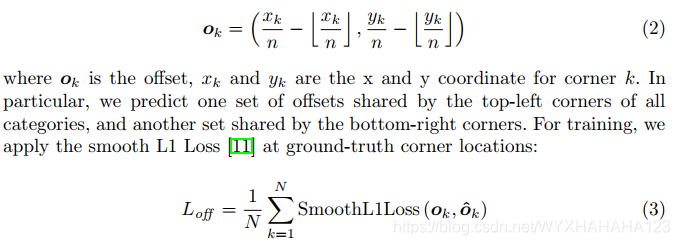
3.角点聚组(group corners)
pull loss 和push loss,都只在ground truth点处使用
pull loss:让属于同一个ground truth boxes的两个角点处的embedding vector距离越近越好(方差越小越好),pull loss最小值为0
push loss:计算出所有ground truth boxes对应两个角点处的embedding vector,并求出每个gt boxes的平均向量 e_k,k=1,2,...N
让不属于同一个gt boxes的e_k间距越大越好。push loss最小值为0

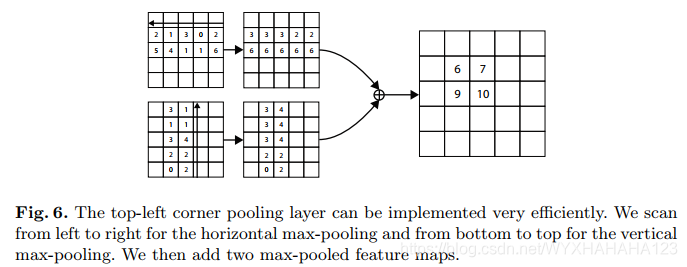
4.corner pooling
5.沙漏网络(hourglass network)

















 5939
5939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









