







 本文介绍了高并发的概念,包括响应时间、吞吐量、QPS等关键指标。讨论了提升系统并发能力的垂直扩展和水平扩展策略,强调水平扩展在互联网分布式架构中的重要性。还讲解了正向代理和反向代理的区别,并列举了搭建高并发Web环境所需的技术,如nginx、tomcat集群、redis和mysql集群等。
本文介绍了高并发的概念,包括响应时间、吞吐量、QPS等关键指标。讨论了提升系统并发能力的垂直扩展和水平扩展策略,强调水平扩展在互联网分布式架构中的重要性。还讲解了正向代理和反向代理的区别,并列举了搭建高并发Web环境所需的技术,如nginx、tomcat集群、redis和mysql集群等。
一、什么是高并发?
1.高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
2.高并发与高可用
高并发指在单位时间内的并发请求数非常高,因此对网站的吞吐能力和处理能力比较高。例如12306,淘宝等。
高可用也是分布式系统架构设计中必须考虑的因素之一,旨在减少系统不能提供服务的时间,而保持其服务的高度可用性。其对网站的稳定性要求比较高,比如不允许停止服务,某台机器出问题后不影响网站的正常访问等。
二、如何提升系统的并发能力?
互联网分布式架构设计,提高系统并发能力的方式,主要从两个方面出发:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:通过提升单机处理能力来提高系统并发能力。垂直扩展方式主要有以下两种:
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间。
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的,即通过提升单台机器的性能来解决高并发的问题已不适用当前暴涨的网络访问,所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,下面以常见的互联网分布式架构(如下图所示)为例,介绍互联网公司架构各层常见的水平扩展实践。
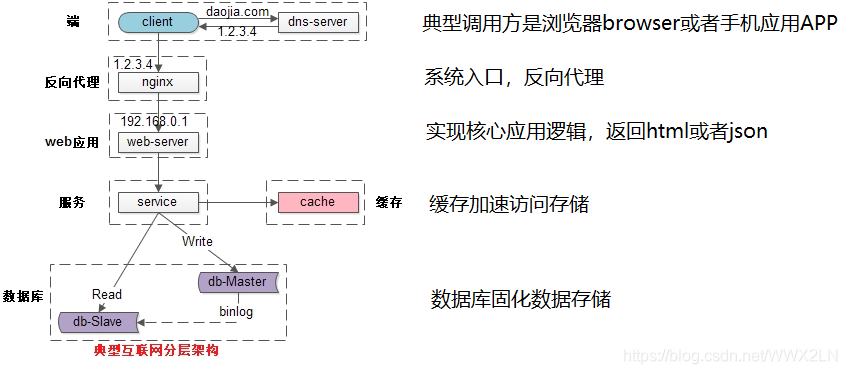
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
三、正向代理与反向代理的区别
正向代理:是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
我们常说的代理也就是正向代理,正向代理的过程,它隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求,科学上网工具 Shadowsocks 扮演的就是典型的正向代理角色。
反向代理:反向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理 的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容 原本就是它自己的一样。
客户不知道真正提供服务的人是谁。反向代理隐藏了真实的服务端,当我们访问 www.baidu.com 的时候,就像拨打 10086 一样,背后可能有成千上万台服务器为我们服务,但具体是哪一台,你不知道,也不需要知道,你只需要知道反向代理服务器是谁就好了,www.baidu.com 就是我们的反向代理服务器,反向代理服务器会帮我们把请求转发到提供真实计算的服务器那里去。Nginx 就是性能非常好的反向代理服务器,它可以用来做负载均衡。(Nginx是一个高性能的反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器)
四、搭建一个高并发得到Web环境都需要什么?
(1)ngix + tomcat 集群 + redis集群 提高网络吞吐量
单个tomcat的网络吞吐量有限,如果很多个tomcat进行集群,就可以提供一个较高的网络吞吐量。 此外,如果网站有较多的计算,也可以采用此种方案来提升网站的计算能力。
(2)mysql 集群 提高数据库并发访问能力
用户的数据最终都是存储在数据库的,数据库的数据都是存储在磁盘上。当有较多的磁盘访问时,磁盘io就会被占满,从而造成网站体验变差。而mysql集群正解决了此问题。
(3)hadoop 分布式计算和分布式存储
前两种方案都只适合对事务要求较高、数据库的增删改(CUD)操作频繁的场景。如果数据库对事务要求不高,负载都集中在查询上(例如百度、淘宝),则可以考虑使用hadoop来进行数据的计算和存储。
真实的环境中,面临的问题通常都是复杂的,因此经常是几种方案混合使用。
参考文章:
https://blog.youkuaiyun.com/DreamWeaver_zhou/article/details/78587580
https://blog.youkuaiyun.com/sxyandapp/article/details/52104961

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









