




 本文解析了MySQL中更新语句的执行流程,包括引擎查找数据、执行器处理、Redo及Binlog日志的两阶段提交机制等内容,确保了数据的一致性。
本文解析了MySQL中更新语句的执行流程,包括引擎查找数据、执行器处理、Redo及Binlog日志的两阶段提交机制等内容,确保了数据的一致性。
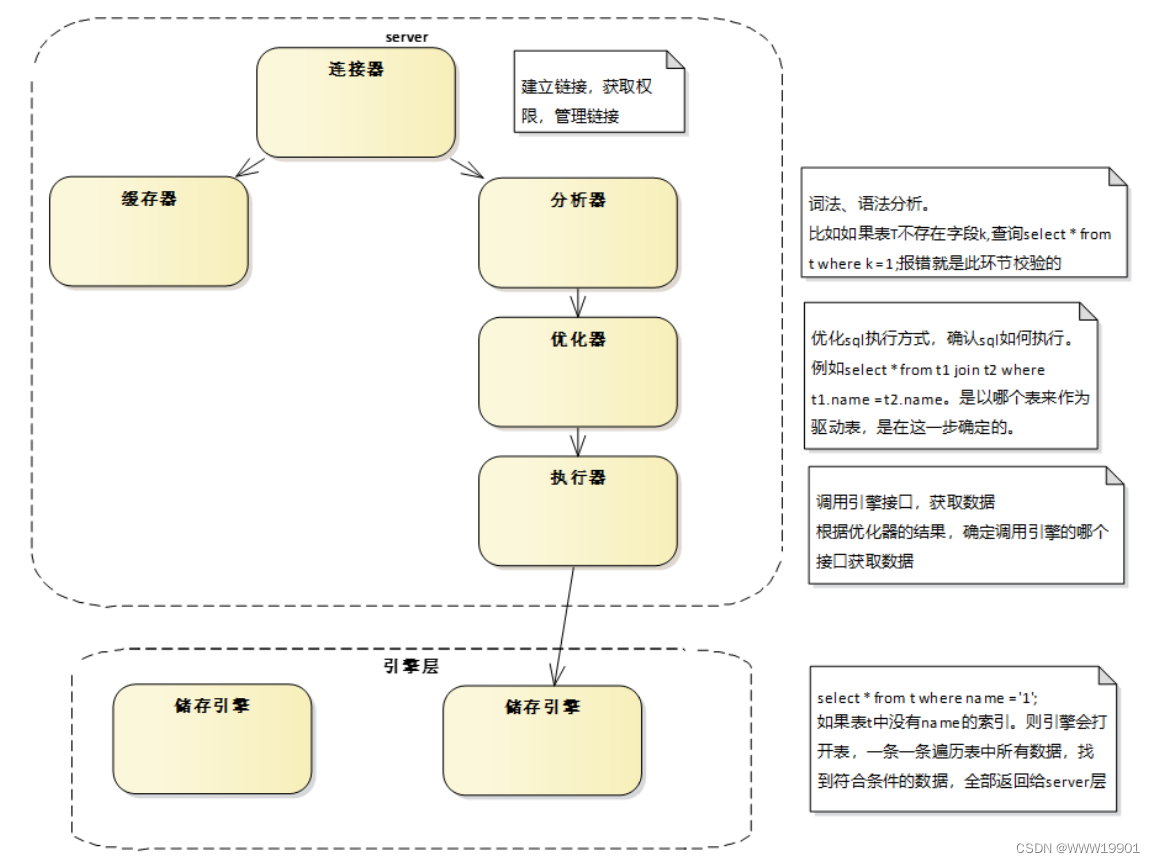
上图展示了一条sql,进入到Mysql后需要经过哪些处理器处理,并最终获得数据的流程。
缓存器可以不考虑,在8.0之后的版本中已移除。主要看右边流程。
关于表权限的事情需要注意,表权限是在sql执行器调用引擎,打开表的时候进行校验的,如果当前用户没有表权限,则会报权限异常。
以上主要是查询语句的处理。在更新语句处理,其他流程几乎相同,主要涉及到binlog和redo log的二段提交确保数据一致。
binlog是server层的日志,redo log是innodb引擎层的日志方案。
redo log是4个指定大小的文件,文件写完会重头开始写。如下图。

binlog和redo log的区别如下:
1、binlog是mysql 的 server层日志,所有引擎都可以使用,但是redo log是innodb的日志,只有它可以使用。
2、redo log是复用指定的4个文件,写完后重头开始写,而binlog日志文件写满后就再创建一个文件。
3、redo log是物理日志,记录了一个数据做了什么样的修改,而binlog是逻辑日志,记录sql的原始逻辑。
继续上文,来了解一下一个更新语句的流程: update t set c = c+ 1 where id = 1;(id是主键索引)
1、引擎根据id查找该行数据,id是主键索引,所以直接根据树搜索找到该数据,如果数据所在数据页已经在内存中,则直接获取数据返回;否则去磁盘找到对应的数据页到内存中,再返回数据到执行器。
2、执行器拿到数据,对c值做赋值 c+1操作,得到新的一行数据,调用引擎接口,写入数据到引擎。
3、引擎将数据更新到内存中,然后写入redo log日志,此时redo log日志状态为prepare;然后告知执行器更新完成,随时可以提交。
4、执行器接受到引擎更新成功,生成Binlog日志,并写入磁盘中,告知引擎。
5、引擎将redo log状态改为commit .完成数据更新。
流程图如下:
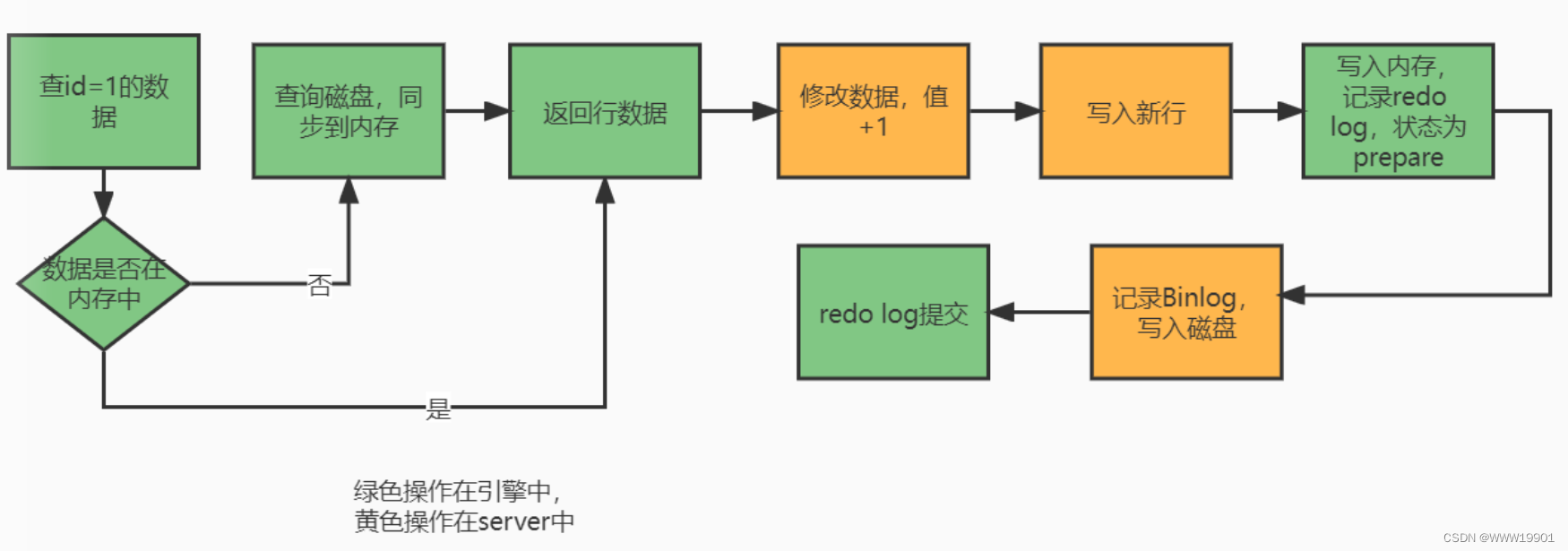
其中将redo log分为prepare和commit2个状态提交,就是所谓的 两阶段提交。
为什么要用两阶段提交?
以 update t set c = c + 1 where id = 1;来说明。
1、如果先写redo log,后写binlog。如果redo log写完,binlog没写系统宕机。此时使用redo log做数据恢复,c 已经+1,但是如果用Binlog恢复数据,c并没有 +1,会导致数据不一致。
2、如果先写binlog ,后写redo log。 同理,如果redo log未写,binlog已写,此时恢复数据时,发现redolog没有记录,此事务无效,不做c+1操作,但是binlog中记录了此操作,如果用Binlog恢复数据,也会导致数据不一致。
在做扩容的时候,如果使用全量 + Binlog来做备库数据同步,也会导致数据不一致问题。
补充:
innodb_flush_log_at_trx_commit = 1 ;表示每次redo log都同步到磁盘中。
sync_binlog = 1 ;表示每次binlog同步到磁盘。
双1设置保证redo log 和binlog 数据不会丢,数据一致。

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









