






 本文介绍了计算框架、并行计算框架和分布式计算的概念,重点解析了Hadoop为何比传统方案快,主要归因于分布式存储和MapReduce思想。MapReduce通过‘分而治之’的方式,将大任务拆解为多个小任务并行处理,最后进行结果汇总,适合大规模离线数据处理。
本文介绍了计算框架、并行计算框架和分布式计算的概念,重点解析了Hadoop为何比传统方案快,主要归因于分布式存储和MapReduce思想。MapReduce通过‘分而治之’的方式,将大任务拆解为多个小任务并行处理,最后进行结果汇总,适合大规模离线数据处理。
MapReduse(分布式计算框架)
什么是计算框架?
是指实现某项任务或某项工作从开始到结束的计算过程或流的结构。用于去解决或者处理某个复杂的计算问题。
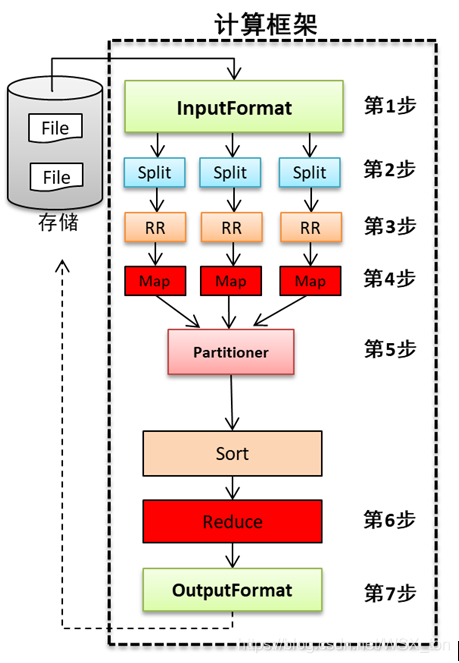
什么是并行计算框架?
是指为更快的计算某项任务或某项工作,将计算程序分发到多台服务器上,使每个服务器计算总任务的一部分,多台服务器同时计算的框架。
即:一个大任务拆分为多个小任务,每个小任务同时执行。
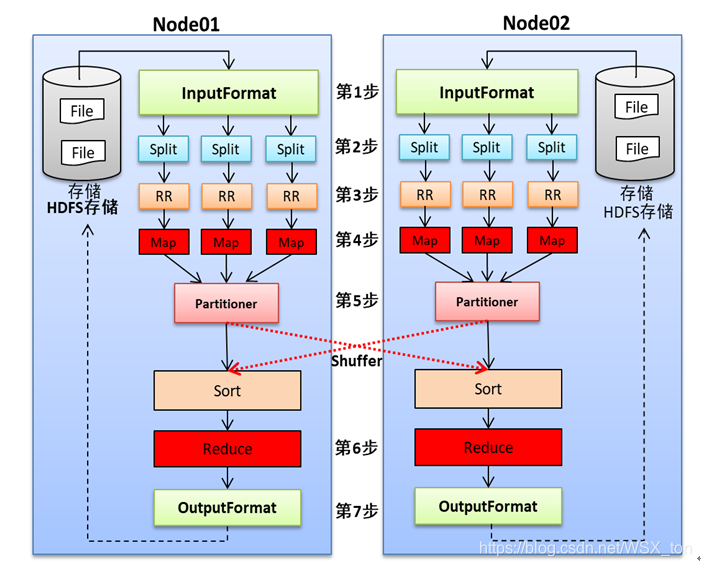
什么是分布式计算?
分布式计算:是一种计算方法,是将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
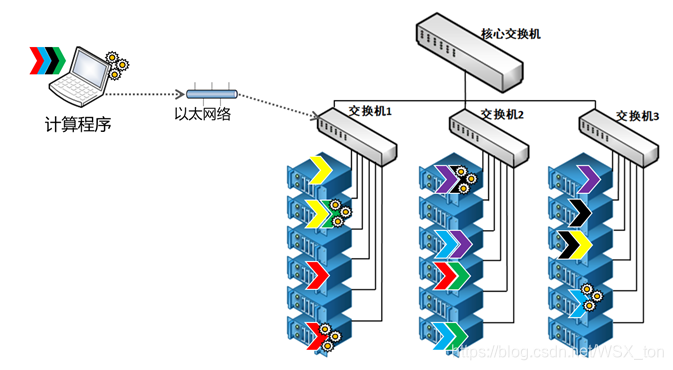
Hadoop为什么比传统计算方案快
- 核心原因一:使用分布式存储
- 核心原因二:使用分布式并行计算框架
理解MapReduce思想
需求:有一个五层的图书馆,需要获取图书馆中一共有多少本书。
只有一个人时,是能一本一本的数!工作量巨大,耗时较长。
分配五个人由你支配。此时你怎么支配?
五个人,每个人数一层的书量,最终将五个人的量汇总求和,就是图书馆中最终书的数量。
MapReduce的思想核心是 “分而治之,先分后合” 。即将一个大的、复杂的工作或任务,拆分成多个小的任务,并行处理,最终进行合并 。 适用于大量复杂的、时效性不高的任务处理场景(大规模离线数据处理场景) 。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
MapReduce由两部分组成,分别是Map 和Reduce两部分.
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。例如前面例子中的分配每个人数一层楼。
Reduce负责“合”,即对map阶段的结果进行全局汇总。例如前面例子中将五个人的结果汇总。
这两个阶段合起来正是MapReduce思想的体现。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









