



在探索linux的某些完全不相关的module时,笔者意识到了一些共性的内容,我不认为这是一种巧合,而是一种设计的哲学,比如本文讨论的分层架构。本文深入剖析了Linux系统的分层架构思想。以read调用读取1字节、面包供应链为例,拆解了从应用层到硬件层的层级逻辑。从「What」「Why」「How」三个维度,帮助读者以最快速度、最简易方式理解Linux的分层设计哲学。
一、What:分层架构是什么?
我们首先来看一个生活实例,假如说你现在想吃面包,你会怎么办?
第一种方式:很简单,找一家卖面包的店,购买即可,对吧。
第二种方式:自己种小麦、收割、磨成面粉、加工、送入烤箱得到成品,但没人会这样做
OK这就是分层和不分层的区别啊
那么如何精准描述Linux的分层架构呢:
Linux 分层架构设计是按功能拆分的多层结构,各层独立各司其职,层间通过固定接口交互,互不干涉,便于维护和扩展。
结合例子来理解一下Linux的分层架构:
先别问为啥要这样做,在第二节会讨论。回到我们获得面包的案例,正常人都会选择去面包房买面包,那么你就是分层架构里面的一层,其他层有:面包店、各种材料生产商、农民,etc.
你去买面包,那你就是其中的消费者层,消费者里不止你一个人,但你们很多人目的都一样:进店买东西,所以你们所有人可以归为一层,其他层同理。很像抽象出一个类对吧,可以这么理解。此时你作为消费者层的一个实例:
你不会和种小麦的农民产生任何交流,但你获得了农民生产的小麦制品。
你会和面包店产生交互,但你并不关心面包店的其他信息,你只要获取面包而已。
面包店上新了,消费者也是只需购买就ok了,不必关心面包店是不是换了原料供应商。
这就是:各层独立各司其职,层间通过固定接口交互,互不干涉,便于维护和扩展。
接下来我们来看一个Linux系统里的实例:
Linux 分层架构在文件 IO 场景中体现得最为直观,我们要通过库函数read读取磁盘中的1byte数据,大致都要经过:应用层→C 函数库→系统调用→VFS→PageCache→文件系统→通用块层→IO 调度层→硬件驱动→硬件。
现在你不必理解下图中这么多层分别干了什么,你只需要知道当你调用read时,并不是该函数直接去磁盘找了数据并交给你,而是经过了下图很多层的调用。
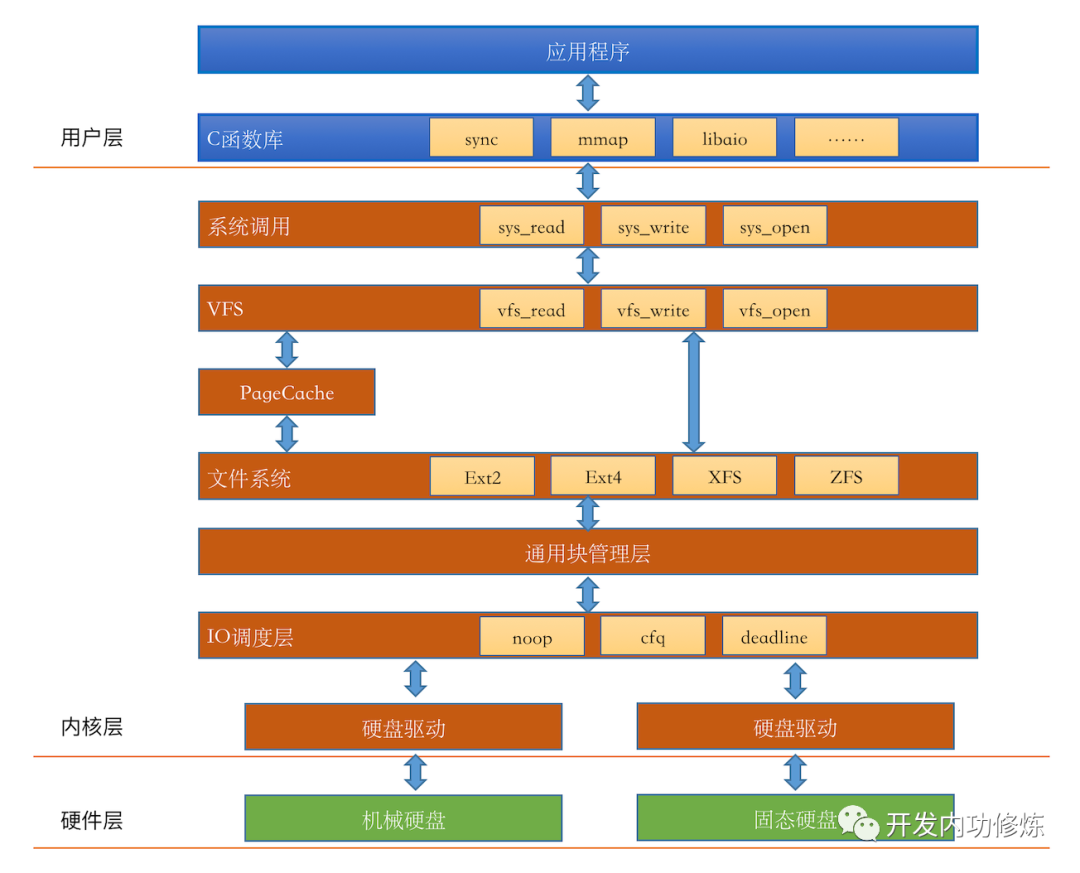
下图表格说明了当你调用read函数读取磁盘文件数据时linux里发生了什么:
| Linux IO 调用层 | 核心职责 |
| 1. 应用层(App) | 发起文件读取请求(如代码中read(f,&c,1)读 1 字节) |
| 2. C 函数库层 | 封装 IO 引擎(如read属于 sync 引擎),转发请求到系统调用 |
| 3. 系统调用层(Syscall) | 接收库层请求,转换为内核可识别指令(如sys_read) |
| 4. VFS | 抽象文件系统模型,调用vfs_read,屏蔽 Ext4/XFS 等具体实现差异 |
| 5. PageCache | 内存中的文件数据缓存,命中则直接返回数据,未命中则触发缺页中断 |
| 6. 文件系统层 | 实现 VFS 的具体操作,按 “块” 管理数据 |
| 7. 通用块层 | 抽象硬件差异,用bio结构描述 IO 请求,转发到 IO 调度层 |
| 8. IO 调度层 | 优化 IO 请求顺序 |
| 9. 硬件驱动层 | 适配具体硬件,将 IO 请求转为硬件指令 |
| 10. 硬件层(磁盘) | 按 “扇区” 读取数据,返回给上层 |
看完之后,可能有读者想说:怎么TM这么麻烦,我直接让read函数从硬盘里掏出来1Byte给我看不就完了?
确实啊!对于任何一个实例来说,直接去做实现的话,流程确实会简化很多。但是系统中有这样千千万万个实例啊,如果每个实例我们都直接这样实现的话,那就不叫一个操作系统了,就会和菜市场一样混乱无序,这显然不是大家想要的。
本节我们找到了分层架构的核心特点:
对于每一层,我们分对上层和对下层两方面来看
与其下层的联系:依赖下一层的API,但不关心下一层的实现细节。
与其上层的联系:给上层提供API。
二、Why:为什么要搞分层?
好的,下面请你回答问题
你买一块面包,关注什么,不关注什么?
你肯定关注:价格,品相,味道
你不太关注:原材料产地,做法,服务员的工资,etc.
那么原材料产地,做法,服务员的工资这些到底有没有人关注呢
肯定有的,但不是你啊!比如烘焙师关注面包做法,服务员关注自己的工资等等
那谁和你关注的要素一样呢?
答案当然是和你一样的消费者呗,所以你们消费者可以归为一类,因为你们关心同样的东西,你们的目的也是一样的。
我不知道我是否说清楚了......
问题答案如果让我来总结的话,就八个大字:
解耦、复用、拓展、可控
这也是要设计一个好的操作系统,必须要考虑的问题。
这四个词汇分别什么意思呢?
解耦:职责隔离,仅靠标准接口交互,改动独立无牵连;
复用:核心能力抽为公共服务,多场景直接调用不重复开发;
拓展:新增功能无需改动原有架构,灵活兼容适配;
可控:权限校验、风险拦截、问题可追溯,流程与风险均在掌控。
三、How:分层的优缺点
如果还用我们之前的例子,那就是你无需自己种小麦、收割、磨成面粉、加工、送入烤箱得到成品,只用通过从面包店购买,就可以达到和复杂方法一样的效果:获得了面包。
1. 分层的核心优点:
| 优点 | IO 场景实例 |
| 性能优化(缓存) | PageCache 命中时,读 1 字节无需磁盘 IO,直接从内存返回 |
| 兼容性(屏蔽差异) | 应用读 1 字节,不用关心磁盘是机械盘还是 SSD盘 |
| 效率(批量处理) | 磁盘按扇区(512 字节)读,文件系统按块(4KB)存,PageCache 按页(4KB)缓存,一次 IO 能供多次读 1 字节的请求 |
| 安全(权限控制) | 应用要读 1 字节,必须经过 VFS 权限校验,不能直接访问磁盘 |
2. 分层的缺点:
| 缺点 | IO 场景实例(参考链接博客) | Linux 的优化手段 |
| 性能开销(额外 IO) | 读 1 字节却最少要读 4KB(PageCache 页大小),造成 冗余 IO | 1. 预读取策略:提前读更多数据,供后续请求使用; 2. 零拷贝技术,减少数据在层间拷贝的开销 |
| 调试复杂(问题定位难) | 读 1 字节失败,可能是 PageCache 未命中、VFS 权限错、磁盘驱动故障 | 1. 日志工具:dmesg 看内核日志,strace 跟踪系统调用; 2. 性能工具:perf 分析 IO 耗时 |
| 架构冗余(流程长) | 读 1 字节要经过好多层,流程比 直接读磁盘复杂得多 | 1. 动态模块:不用的层不加载; 2. 精简路径:高频请求跳过底层 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









