



 本文分享了使用PyCharm和BeautifulSoup进行豆瓣图书信息爬取的实践过程,包括库导入、网页请求、数据解析及文件写入等关键步骤。
本文分享了使用PyCharm和BeautifulSoup进行豆瓣图书信息爬取的实践过程,包括库导入、网页请求、数据解析及文件写入等关键步骤。
pycharm+BeautifulSoup爬取豆瓣获取图书信息
最近接触了爬虫,但是只是一点皮毛,所以做了一个豆瓣小说爬取图书信息的小练习,技术小辣鸡记录一下自己的学习记录。
具体思路
- 导入相应的库:
import requests
from bs4 import BeautifulSoup
- 设置要爬取的网页和User-Agent
base_url='https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4'
douban_headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
} 注:设置 User-Agent 绕过检测,不然可能爬到的是乱码
- 将获取的内容写入文件中
def writr_to_file(Book_Name,Book_Rating_num,Book_href,Book_Pub,Book_brief):
file=open('Book.txt','a',encoding='utf-8')
file.write("Book_Name: "+Book_Name+"\nBook_Rating_num: "+Book_Rating_num+"\nBook_href: "+Book_href+"\n"+"Book_Pub: "+Book_Pub+"\n"+"Book_brief: "+Book_brief+"\n\n")
- 获取爬到的网页
def get_page_html(url):
response=requests.get(url,headers=douban_headers)
if response.status_code==200:
return response.text
else:
return None
- 解析爬取到的网页
def parse_html(html):
soup = BeautifulSoup(html, 'lxml') //使用lxml解析方式
Book_Name=soup.select('.info h2 a') //使用BeautifulSoup 的CSS选择器获取节点信息
Book_href=soup.select(".info h2 a[href^='http']")
Book_Pub=soup.select('.info .pub ')
Book_Rating_num = soup.select('.info .clearfix .rating_nums')
Book_brief=soup.select('.info p')
for i,k,t,j,p in zip(Book_Name,Book_Rating_num,Book_href,Book_Pub,Book_brief):
print(i['title'],str.strip(k.string),t.attrs['href'],str.strip(j.string),str.strip(p.string)) //因为爬取的是一个页面的数据内容,一个节点有多个属性,所以使用i['title'] ;因为标签之间有多个换行符,所以使用strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
writr_to_file(i['title'],str.strip(k.string),t.attrs['href'],str.strip(j.string),str.strip(p.string)) //调用函数 ,将内容写入文件中
- 调用
if __name__ =='__main__':
html=get_page_html(base_url)
parse_html(html)
- 运行结果
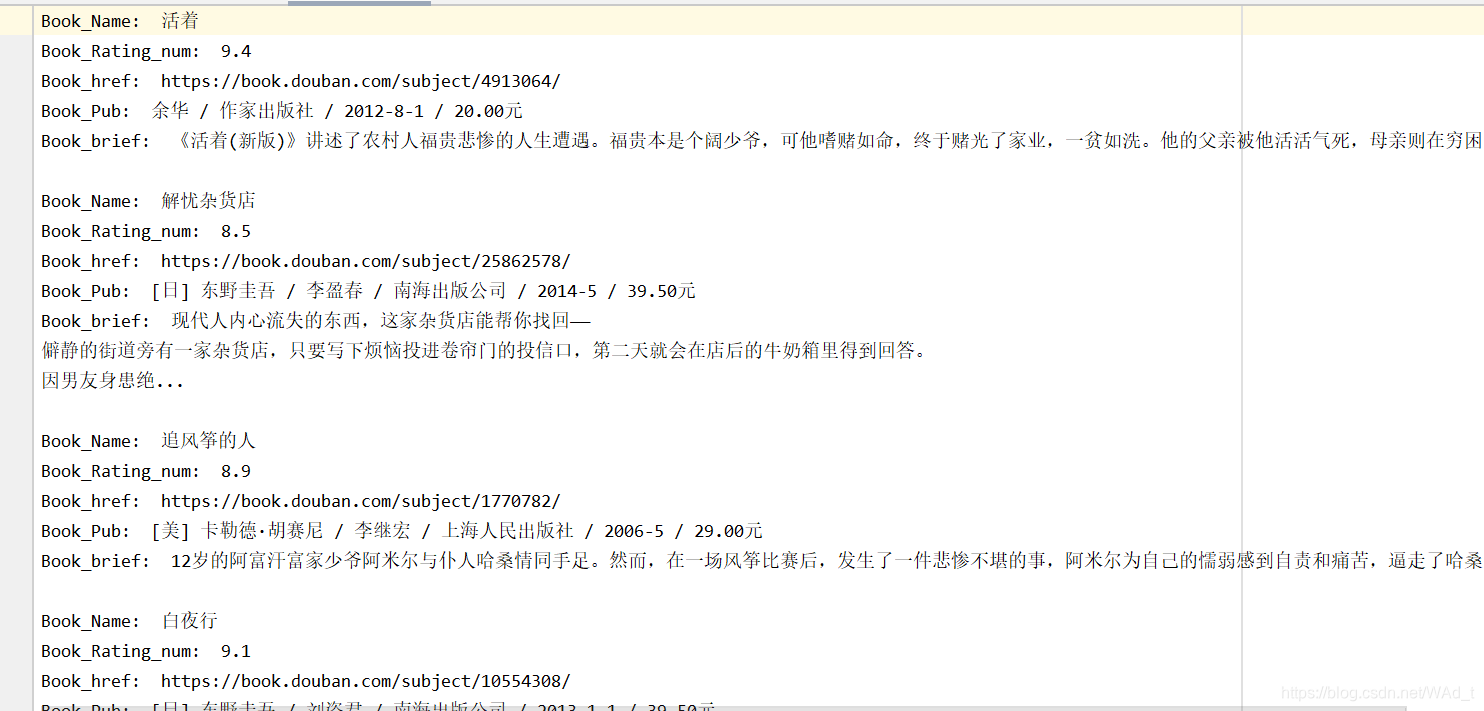
如果想要知道更多的节点内容获取方式可以查看:css选择器参考文档

















 3881
3881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









