






前言
前不久国内发布的deepseek模型由于耗费较少、且性能相较于openAI更为优秀,深刻影响了国外的AI市场价格趋势。国内外一些常用的AI模型比如Qwen系列、ChatGPT大多需要付费才能体验完整功能,价格是按照使用的token数量计价收费,每1000篇文章左右消耗的token数量是在500万左右,如果公司项目对文章需求量大,这也是一笔不小的开支,其次deepseek官网经常被攻击,有时也会出现访问网站失败的情形。本篇文章主要是使用ollama框架在自己电脑中部署开源的deepseek语言聊天模型,如果需要使用RAG(数据检索增强)也可以使用ollama在电脑中部署向量转换模型。
一、下载ollama模型框架
1、1、 浏览器搜索ollama,点击download;

2、等下载结束后直接点击安装(默认安装在c盘);
3、安装结束后,可以修改模型的存放地址(这个也是默认存放在c盘);
修改步骤(win10为例):目标盘新建文件夹并修改名称(尽量别用中文命名)->我的电脑->属性->高级系统数值->环境变量->新建变量->变量名为OLLAMA_MODELS->变量值为新建文件夹的路径,修改变量如下所示;



4、至此ollama框架下载完毕。
二、下载deepseek-R1模型
1、在下载要使用的模型版本前,需要确认电脑的RAM配置与显卡,这个也是在我的电脑->属性中查看,本地部署deepseek模型,不仅需要RAM支持,也需要显卡GPU,否则会影响AI模型的推理速度;
2、打开ollama网页,选择左上角models;
3、选择第一个deepseek模型,至于第三个Embedding模型是向量模型,作用是将数据转化为向量数据,用于RAG数据增强检索的。如果公司需要搭建Ai私有数据库,可以使用向量模型转化数据后存入向量数据库,如ElasticSearch、Redis等支持向量数据的中间件,这里目前暂时用不到;
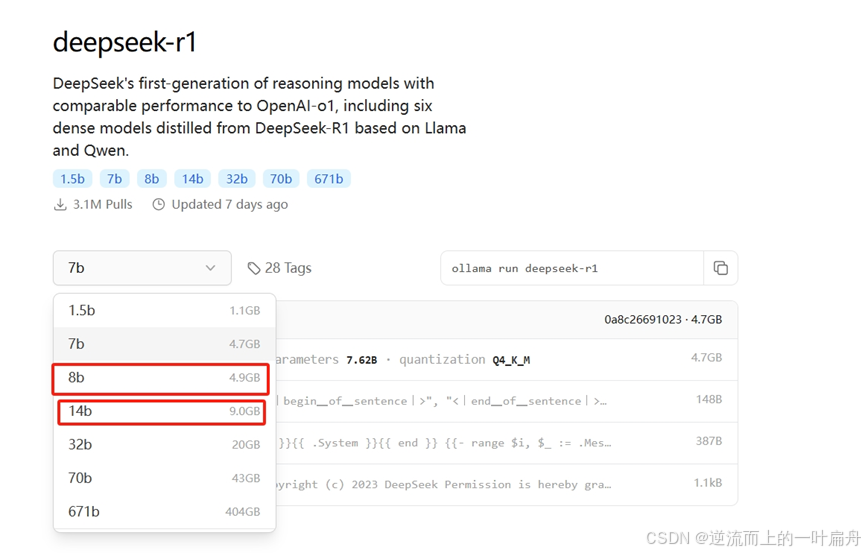
 4、deepseek模型有多个版本,请根据自己电脑的RAM容量已经显卡的现存选择合适的版本,我的电脑RAM是16G运行14b(9G)的模型后,内存就占用了70%左右。如果是8G独显,是可以无压力运行14b及以下模型的。如果电脑没有显卡或者只是集成显卡,RAM足够的情况下也是可以运行的,只是推理速度要慢的多。(这里补充一点,如果需要使用向量模型转化数据,经过验证,有独立显卡会比只有集成显卡的服务器转化速度要快6倍以上)。
4、deepseek模型有多个版本,请根据自己电脑的RAM容量已经显卡的现存选择合适的版本,我的电脑RAM是16G运行14b(9G)的模型后,内存就占用了70%左右。如果是8G独显,是可以无压力运行14b及以下模型的。如果电脑没有显卡或者只是集成显卡,RAM足够的情况下也是可以运行的,只是推理速度要慢的多。(这里补充一点,如果需要使用向量模型转化数据,经过验证,有独立显卡会比只有集成显卡的服务器转化速度要快6倍以上)。
三、运行deepseek模型
1、windows+R键输入cmd进入终端
2、输入start ollama 启动ollama
3、输入命令ollama run deepseek-r1:14b(以14b版本模型为例),等待安装下载完成。
4、可以输入命令ollama ls 查看已经安装的模型(以我已经安装的模型为例)

5、后续再次使用模型,可以直接输入命令ollama run xxx(xxx为模型名称)。
6、待模型启动完成后,就可以愉快的输入信息与模型对话了。

总结
在自己电脑上部署deepseek模型还是很容易的,使用ollama框架不仅可以部署deepseek模型,也可以部署其他AI模型,如llama、Qwen、Qwen2等,按照上面的步骤操作,很容易就能在电脑上部署专属于自己的Ai模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









