






JavaScript动态渲染的页面不止Ajax一种,有的是通过JavaScript的一些函数算法生成。此外,类似淘宝网、QQ音乐的页面,Ajax渲染接口含有很多的加密参数,难以直接找出它们的规律。
为了解决这类问题,我们可以采用模拟浏览器的方式实现数据获取。我们不需要在管内部JavaScript如何生成数据,或者Ajax有什么参数了。只需要获取到网站的Elements的HTML代码,然后从这个代码字符串中获取需要的数据,就可以解决这类问题。
通过模拟浏览器运行的方式来实现有多种技术方式,如Selenium、PhantomJS、Splash、Ghost等,我们这次介绍如何使用selenium来实现模拟浏览器的方式实现数据获取。
安装
首先,和其它所有Python库一样,Selenium需要安装,方法也很简单, 使用pip安装。
pip install selenium # Windows电脑安装selenium
pip3 install selenium # Mac电脑安装seleniumSelenium的脚本可以控制所有常见浏览器的操作,在使用之前,需要安装浏览器的驱动。
使用
1.创建对象
以下是浏览器的设置方式:把Chrome浏览器设置为引擎,然后赋值给变量driver。driver是实例化的浏览器。
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器2.访问页面
Selenium可以用get()方法访问页面,就像在浏览器的URL窗口中输入URL,然后按[enter]的效果一样。
driver.get('www.baidu.com') #访问百度首页
driver.close() #关闭网页3.解析与提取数据
在我们创建好实例化浏览器[driver]之后,driver就已经自动完成数据的解析了,我们只需将数据提取出来即可。Selenium提取数据的方式有多种,具体方法如下图所示:
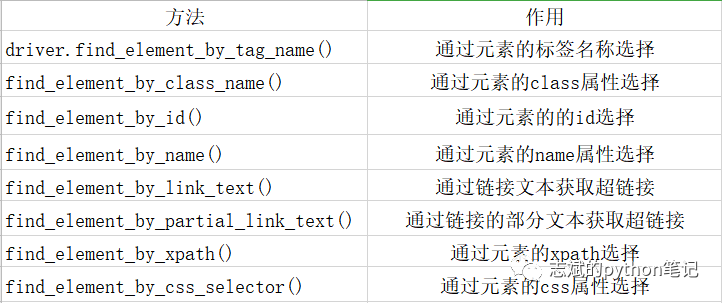
4.节点交互
Selenium可以驱动浏览器来执行一些操作,即可以让浏览器模拟执行一些动作。例如,输入文字时用send_keys()方法,清空文字时用clear()方法,单击按钮时用的click()方法。
key = driver.find_element_by_id('key')
#找到输入框
key.send_keys(keyword)
#输入关键字
time.sleep(random.randint(1,3))
sousuo = driver.find_element_by_tag_name('button')
#找到搜索按钮
sousuo.click()
#点击搜索按钮5.延时等待
在Selenium中,get()方法会在网页框架加载完成后结束执行,此时如果获取page_source,则可能并不是浏览器完全加载成的页面,如果默写页面有额外的Ajax请求,那么在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定的时间,确保节点加载完毕。
这里我们介绍两种等待的方式。
(1)强制等待
之前文章中的代码使用的time.sleep就是强制等待。程序必须等到时间到达后才能继续执行。代码如下:
time.sleep()(2)隐式等待
隐式等待就是设置了一个等待时间范围,这个等待时间的范围是不固定的,最长的等待也不能超过最大值。
当使用隐式等待执行测试时,如果Selenium没有在DOM中找到节点,将继续等待,超出设定的时间后,则抛出找不到节点的异常。换言之,当查找节点而节点并没有立即出现时,隐式等待将等待一段时间再查找DOM,默认时间为0,代码如下:
dirver.implicitly_wait()这里采用implicitly_wait()方法来设置等待时间,这种方法要比time.sleep更智能一些。
implicitly_wait()默认设置等待时间为0,同时隐式等待是对driver起作用,所以只要设置一次即可,不需要到处设置。
6.前进和后退
平常使用浏览器都有前进和后退的功能,Selenium也可以实现这个操作,它使用back()方法后退,使用forward()方法前进,类似于JavaScript操作浏览器的前进和后退功能,代码如下:
driver.back() #后退
driver.forward() #前进7.操作cookie
使用Selenium可以方便地对Cookies进行操作,如获取、添加、删除Cookies,代码如下:
#获取cookies信息
cookies = driver.get_cookies()
#添加cookie
driver.add_cookie()
#删除cookie
driver.delete_cookie()
driver.delete_all_cookies()
实操运用
通过上面的讲解,我们现在基本对Selenium的常规用法有了大概了解。使用Selenium处理JavaScript不再是难事,那么下面让我们通过爬取京东商品案例来巩固一下上面的知识。
1.分析网站
我们按F12打开开发者模式,然后对我们想要的数据进行定位,找到它的属性,这里我们是寻找的每个平板的单价。
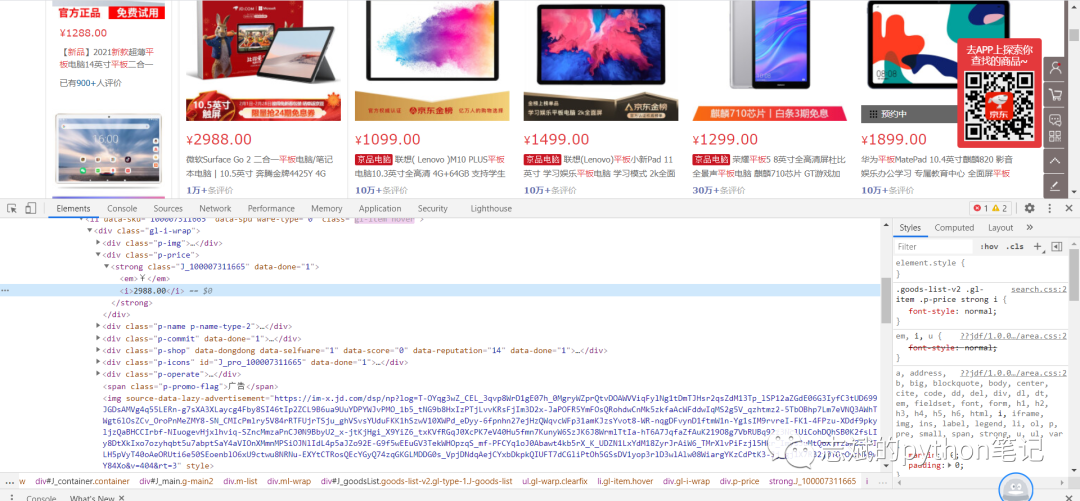
2.提取数据
当我们已经定位到想要提取数据的特定属性时,就可以用上文的提取数据方式对该数据进行提取,代码如下:
jiages = driver.find_elements_by_class_name('p-price')[:60] #提取商品价格
shangpingmingchengs = driver.find_elements_by_class_name('p-name.p-name-type-2') #提取商品名称
dianpumingchengs = driver.find_elements_by_class_name('curr-shop.hd-shopname') #提取店铺名称
fanye = driver.find_element_by_class_name('pn-next')
fanye.click() #进行翻页3.数据存储
看这篇文章就够了→Python爬虫:一文教会你完成数据存储
总结
1. 本文详细介绍了Selenium的使用方法,内容较多,请读者仔细阅读。
2. 京东的商品数据一次只展示30个,读者需要向下滑动来获取另外30个数据。
更多Python学习资料请戳👇



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









