




 本文深入探讨C++11中的右值引用与移动语义,解释如何利用这些特性提高资源管理效率,同时介绍了lambda表达式的应用,展示其如何简化代码并提升编程体验。
本文深入探讨C++11中的右值引用与移动语义,解释如何利用这些特性提高资源管理效率,同时介绍了lambda表达式的应用,展示其如何简化代码并提升编程体验。
相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。这里介绍两个特性。
目录
右值引用
-
右值和左值
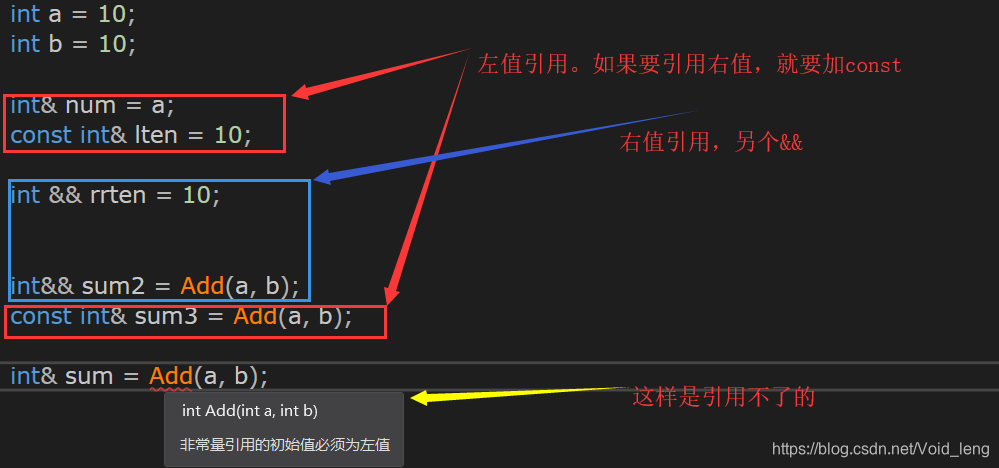
左值:赋值运算符两边都可以出现的值
右值:只能出现在赋值运算符的右边,如:常量,临时变量。
C++中的定义
可以取地址的叫左值
不是左值的就是右值
左值相当于变量,右值变量相当于常量。前面的定义太多,其实归结为一句话可以说,有名字的就是左值,没有名字的就是右值。(常量其实也可以看作是没有名字的)

-
左值引用与右值引用
左值引用:引用左值,一个&,但是也可以引用右值,const+一个&。
右值引用,只能引用右值,两个&,起标记作用。
-
为何引用
这是C++11的新语法,为什么会有这个右值引用?下面用一个例子,来说明。
简单实现一个String的例子。
class String
{
public:
String(const char* str = "")
{
if (str == nullptr)
str = "";
size_ = strlen(str);
str_ = new char[size_ + 1];
strcpy(str_, str);
cout << "String(const char* str = \"\")" << endl;
}
String(const String& s)
: str_(new char[strlen(s.str_) + 1])
{
size_ = strlen(s.str_);
strcpy(str_, s.str_);
cout << "String(const String& s)" << endl;
}
private:
char* str_;
size_t size_;
};
现在我们用这样一个测试用例。
String StringTest()
{
String strtmp("hello");
return strtmp;
}
void Test()
{
String str1(StringTest());
}
//这样可以看见析构函数的调用
其实这里应该是调用了两次拷贝构造,首先在StringTest()中创建一个String的对象,然后返回时,因为strtmp是局部变量,不能直接返回,所以产生了拷贝构造出临时对象,然后临时对象拷贝构造一个str1。但是编译器帮助优化了,编译器一看是要用这个返回的对象拷贝构造,就直接不创建临时对象了,所以这里看不出来两次拷贝构造。
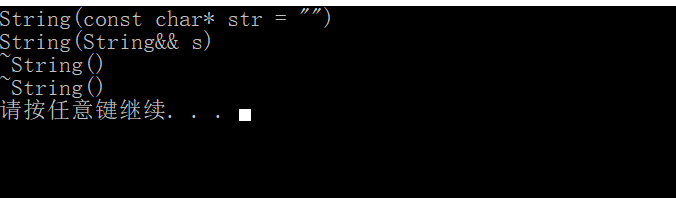
但是通过上面的过程,可以看见一些不必要的操作,一共拷贝构造了两次,而且临时对象又只会用一次。所以可不可以不销毁临时变量,直接用临时变量的资源,可以!右值引用!
用右值引用来使用一下。
String(String&& s)
{
swap(str_, s.str_);
size_ = s.size_;
cout << "String(String&& s)" << endl;
}
前面说右值其实就是没有名字的,它只能使用一次,所以右值引用就是给它一个名字,延长了它的生命周期,就这样理解。
-
移动语义
C++11一个新的语法——移动语义。
将一个对象中资源移动到另一个对象中的方式,称之为移动语义。
但是要使用移动语义必须要使用右值引用。
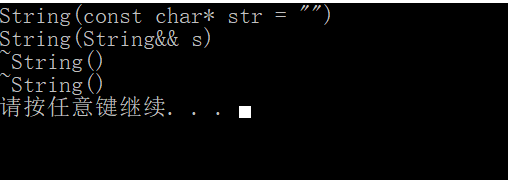
std::move()函数位于 头文件中,这个函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,通过右值引用使用该值,实现移动语义。(注意不要对还要用的左值使用移动语义,因为移动之后,其资源已经不存在了)
String(String&& s)
{
char* tmp = str_;
str_ = move(s.str_);
s.str_ = tmp;
size_ = s.size_;
cout << "String(String&& s)" << endl;
}
把一个数据改成右值,资源移动。浅拷贝
左值引用可以引用右值,为什么还要引用右值?
左值和右值引用都是为了减少拷贝的,左值引用:可以修改左值的内容,但是引用右值不能,不能修改右值,是一个const
右值引用是资源的移动。
lambda表达式
-
sort函数
先举一个sort的例子吧。
struct Person
{
int age_;
Person(int age = 10)
:age_(age)
{}
};
struct Comp
{
bool operator()(const Person& p1, const Person& p2)
{
return p1.age_ > p2.age_;
}
};
void Print(const vector<Person>& v)
{
int i = 1;
for (const auto& t : v)
{
cout << "第 " << i << "大的" << t.age_ << endl;
++i;
}
}
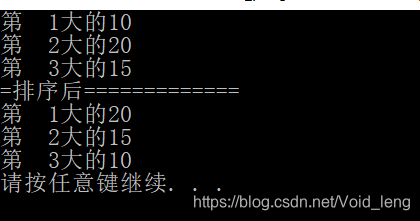
void Test2()
{
Person p1(10);
Person p2(20);
Person p3(15);
vector<Person> vp = { p1, p2, p3 };//C++11的新语法,初始化列表
Print(vp);
cout << "=排序后=============" << endl;
sort(vp.begin(), vp.end(), Comp());
Print(vp);
}
其实用一个sort,却要写一个仿函数,有点浪费时间,于是lambda表达式出手了。
-
概念
lambda表达式其实相当于匿名的函数,可在函数内部定义。
下面在改sort函数。
sort(vp.begin(), vp.end(), [](const Person& p1, const Person& p2)
{
return p1.age_ > p2.age_;
});
-
组成部分
捕获列表 [ ] :lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
参数列表():与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起 。省略
返回值->返回值类型:用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分 可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
函数体{}:在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
父域:父作用域,就是其在某个函数内部调用之前的作用域都是其父域。
如:[c](const int a, const int b)->int{return a + b + c}
[=]值传递父域的对象全部捕捉,[&]传引用
(parameters):参数列表。
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修 饰符时,参数列表不可省略(即使参数为空)。
-
与仿函数对比
- 比仿函数书写方便
- 但是只能用一次,相对于仿函数,仿函数写一次可以多个地方调用,而lambda表达式调用一次写一次。
lambda表达式底层是一个仿函数

















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









