



 本文详细介绍了如何在PyCharm中通过torch库生成CIFAR10数据集的日志文件,并使用TensorBoard进行数据可视化,以及如何在Anaconda环境中启动TensorBoard查看日志。
本文详细介绍了如何在PyCharm中通过torch库生成CIFAR10数据集的日志文件,并使用TensorBoard进行数据可视化,以及如何在Anaconda环境中启动TensorBoard查看日志。
1. 准备工作
安装tensorboard库,在Anaconda中执行以下代码:
conda install tensorboardX
conda install tensorboard
2. Tensorboard的使用
Tensorboard的使用可以分为两方面:
- 在pycharm或者jupyter中生成需要可视化的数据的日志文件(log)
- 在Anaconda中将日志文件中的数据可视化到网页
2.1 在pycharm中生成需要可视化的数据的日志文件(log)
#导入数据集的包
import torchvision.datasets
#导入dataloader的包
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#创建测试数据集
test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor())
#创建一个dataloader,设置批大小为64,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次
test_dataloader = DataLoader(dataset=test_dataset,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
writer = SummaryWriter("log")
#loader中对象
step = 0
for data in test_dataloader:
imgs,targets = data
writer.add_images("loader",imgs,step)
step+=1
writer.close()
2.2 在Anaconda中将日志文件中的数据可视化到网页
tensorboard --logdir="E:\untitled\log"
上面代码中“logdir=”之后的地址为在pycharm中生成的日志文件的地址,比如2.1节代码示例中的日志地址,即log文件的地址,为:
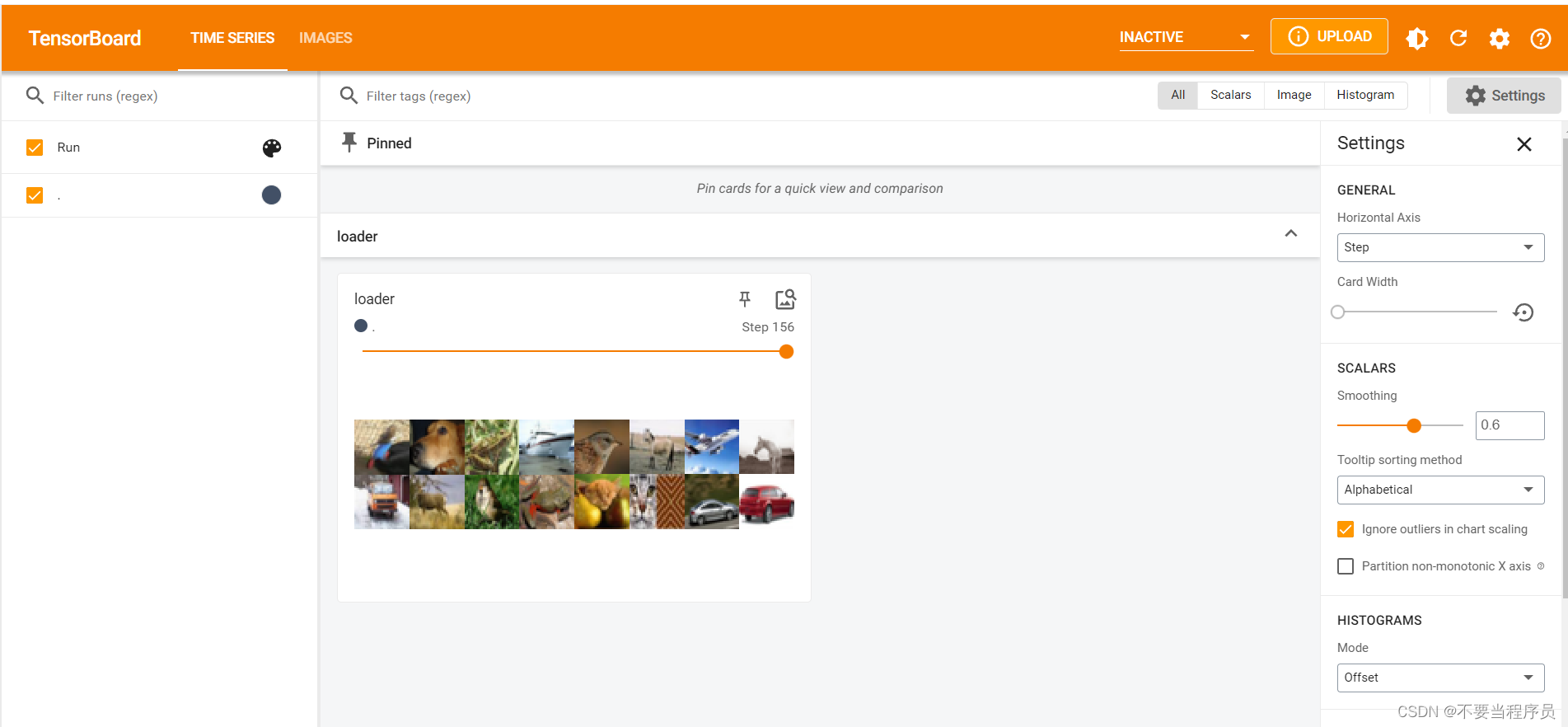
然后打开Anaconda给出的网页 http://localhost:6006/,如下图所示:

然后就能看到:


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









