






前几天笔者为了刷问卷数量尝试了用selenium模拟登录并使用ip代理进行问卷填写,在使用的过程中遇到的主要问题是网页源代码中节点的选择——selenium使用click必须要定位到节点之后才能选取。由于css选择器的方式我不是太熟悉,尝试了一下之后觉得规则有点难记和麻烦,所以最后尝试了使用xpath进行选取。以下便是介绍一下关于xpath的内容并通过一个问卷的演示详细阐述。
首先要说的是,如果你之前不熟悉xpath,然后直接用python尝试定位肯定会有很多的错误浪费时间,所以最好的方式是下载一个xpath的软件,这个软件可以通过填写xpath规则实时演示结果。软件的地址在:
https://pan.baidu.com/s/1sCXx4pPrtzEB7CV6MOclIQ
提取码为:ugbi
该软件只能用在chrome浏览器上,下载完之后解压,会得到一个文件夹
![]()
接下来打开谷歌浏览器,选择最右边的选项,里面有一个更多工具,在更多工具中有一个扩展程序选项,点开。
![]()
如下图所示,注意,你得先打开开发者模式才能进行添加。然后选择加载已解压的扩展程序,选择之前压缩后的xpath文件即可。
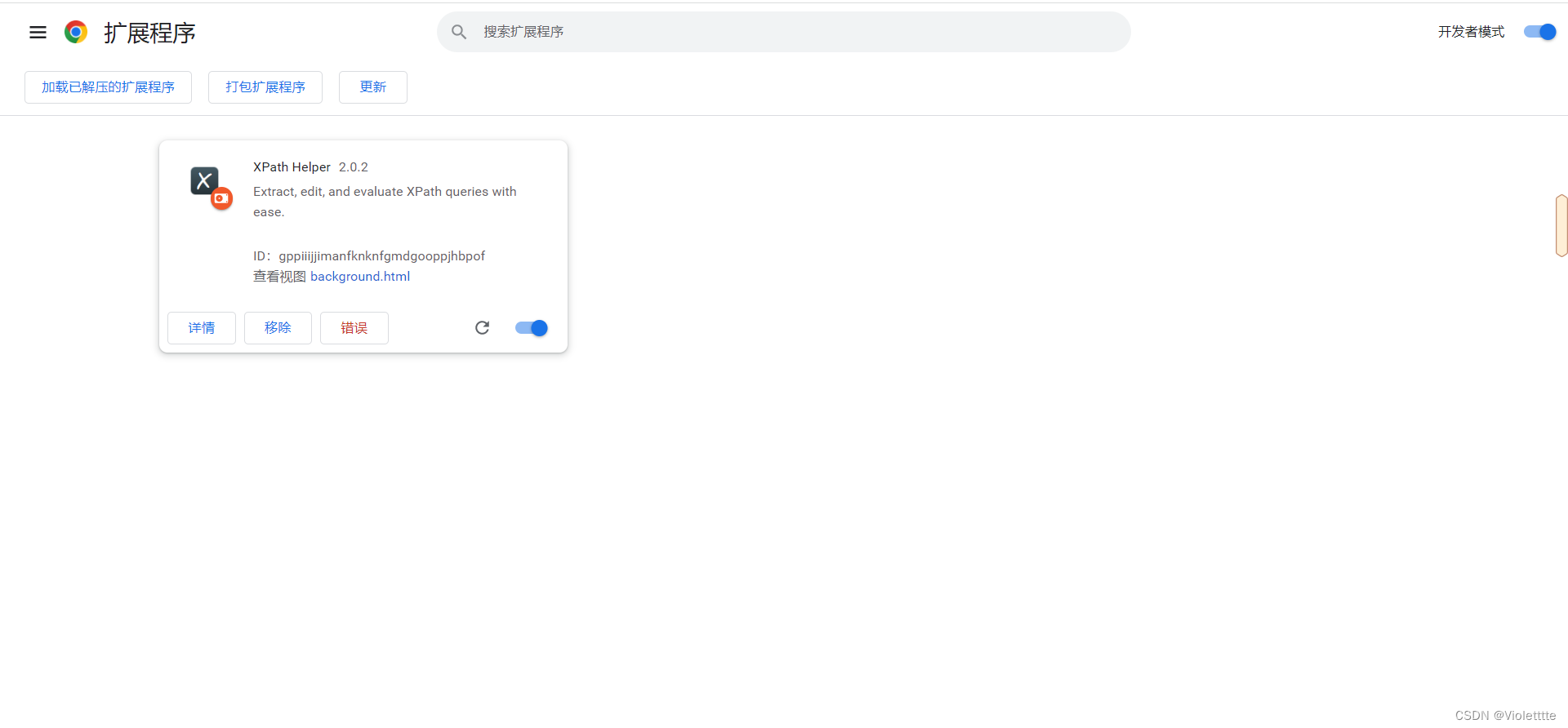
之后,你可以在浏览器的顶上选择即可。
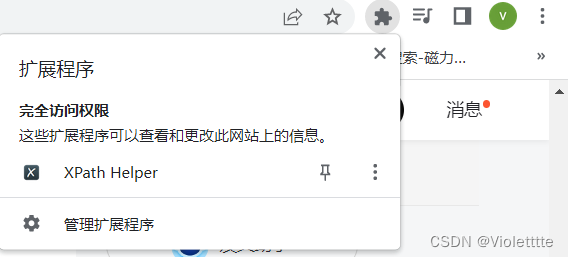
打开xpath扩展程序后,会出现如下的界面,其中QUERY便是你要填写的xpath规则,RESULTS是显示的结果,这个结果显示出来的直接效果是文字,如果一个节点下没有文字,在RESULTS这里会什么都不显示,但是RESULTS后面的括号内是会有数字的(表示究竟有没有符合规则的节点)

接下来主要是介绍xpath的规则,其实非常非常简单。
一般来说,规则基本都是以双斜杠 // 开头,紧接着跟你要找的节点。这里大家可以先开启f12控制台,在Elements中查看网页源代码, xpath规则中的 // 或者 /后首先跟着的都是一个标签最开头的元素,以下面的代码为例:

在上面的代码中,div、svg、script都是第一个元素。(学过html和css的肯定很清楚,这点我就不多说了)。
那么指定了第一个元素,如何找到某个特定的元素呢?在css中相当于属性的说法,那么就需要通过这串代码——[@属性名="属性值"],以我自己创建的一个问卷为例,该问卷的地址为

我们以第一题为例,如果我要定位到整个标题的框架(即涵盖了标题,涵盖了答案的整个框架)改该怎么做?我们先看网页源代码,然后在控制台中找到这个框架。
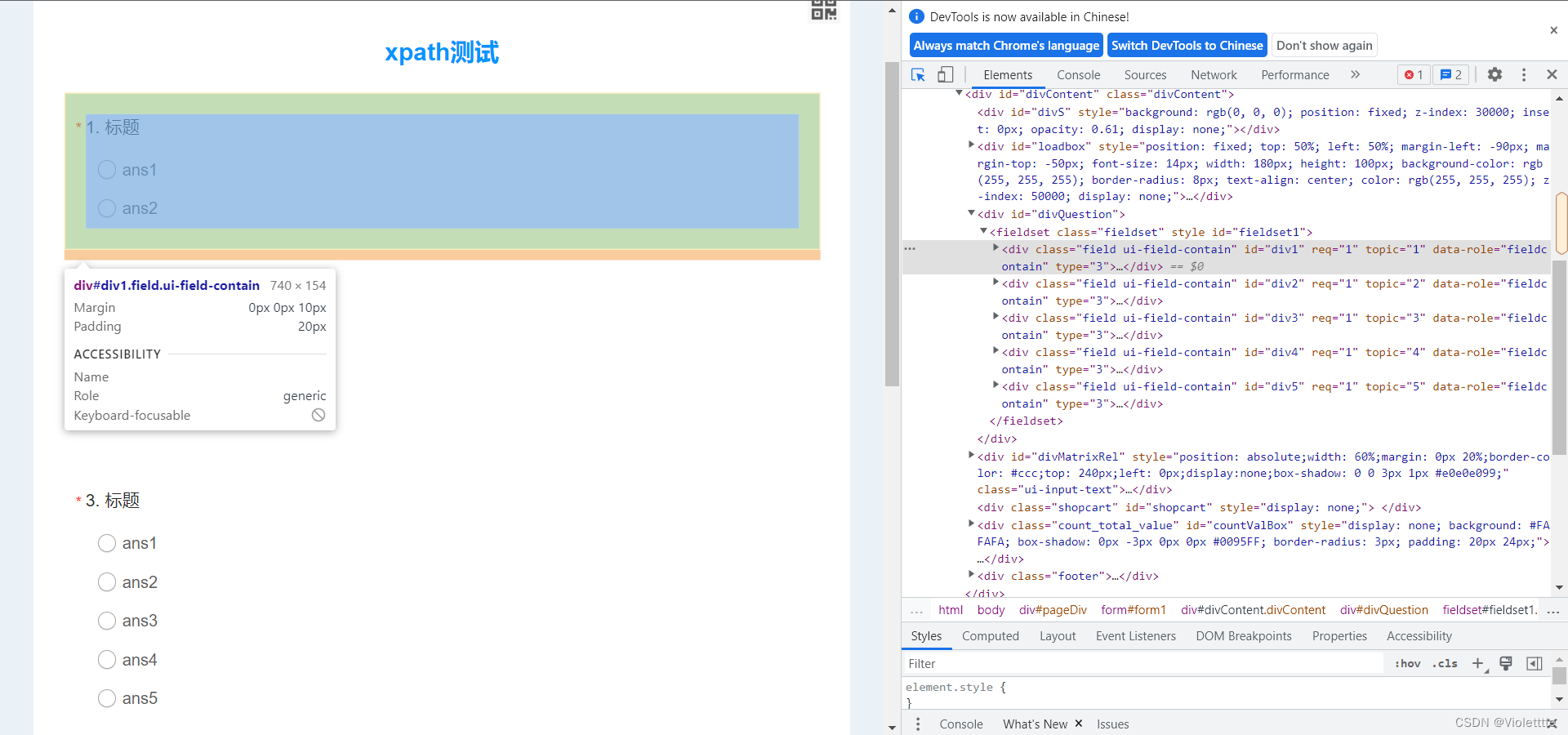
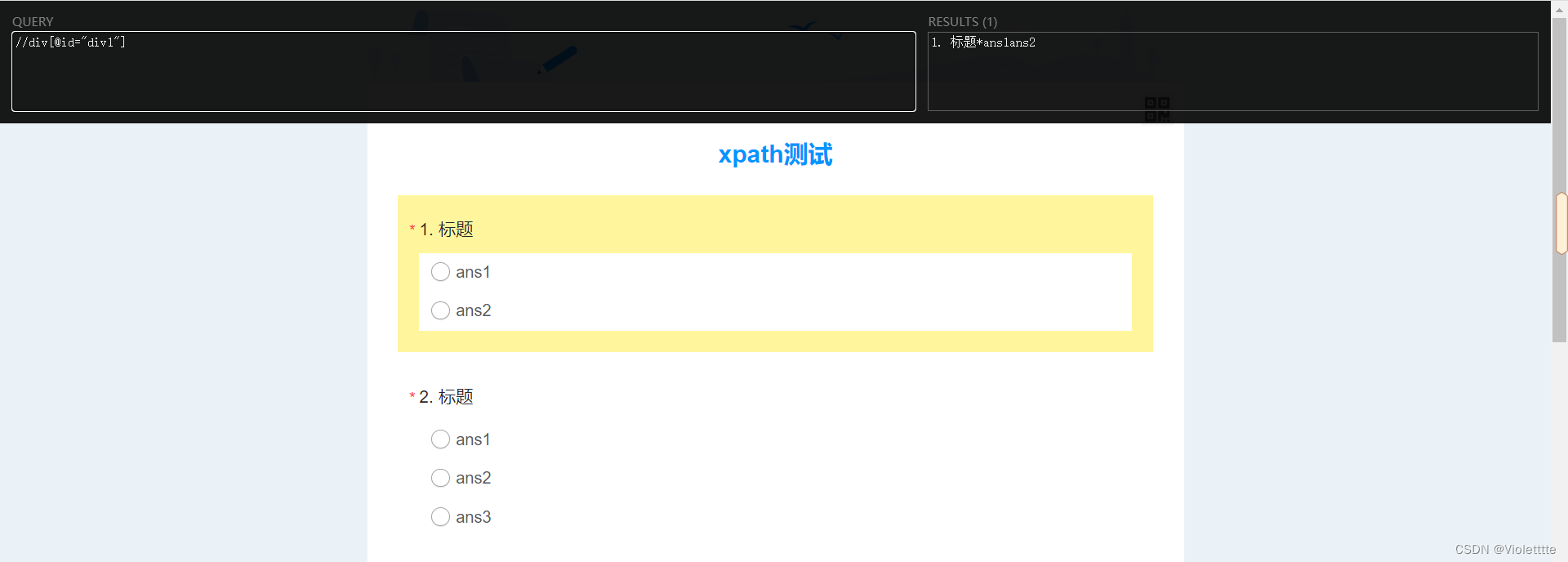
观察网页源代码可以发现,每一道题的开始元素都是div,他们具有相同的class标签和属性值"field ui-field-contain",显然,直接通过[@class="field ui-field-contain"]是无法选择第一题的,(但是可以选择到所有题。),观察发现,不同题的区别在于id属性和topic属性,这里我们只需要选择其中的一个,例如我选择id属性,那么我要定位到第一题的整个框架,只需要在QUERY中输入//div[@id="div1"],观察结果如下
看来我们已经实现了定位到第一题的整个框架,那么现在,我们要选择ans1和ans2的整个框架,又该怎么做?同样通过f12观察源代码
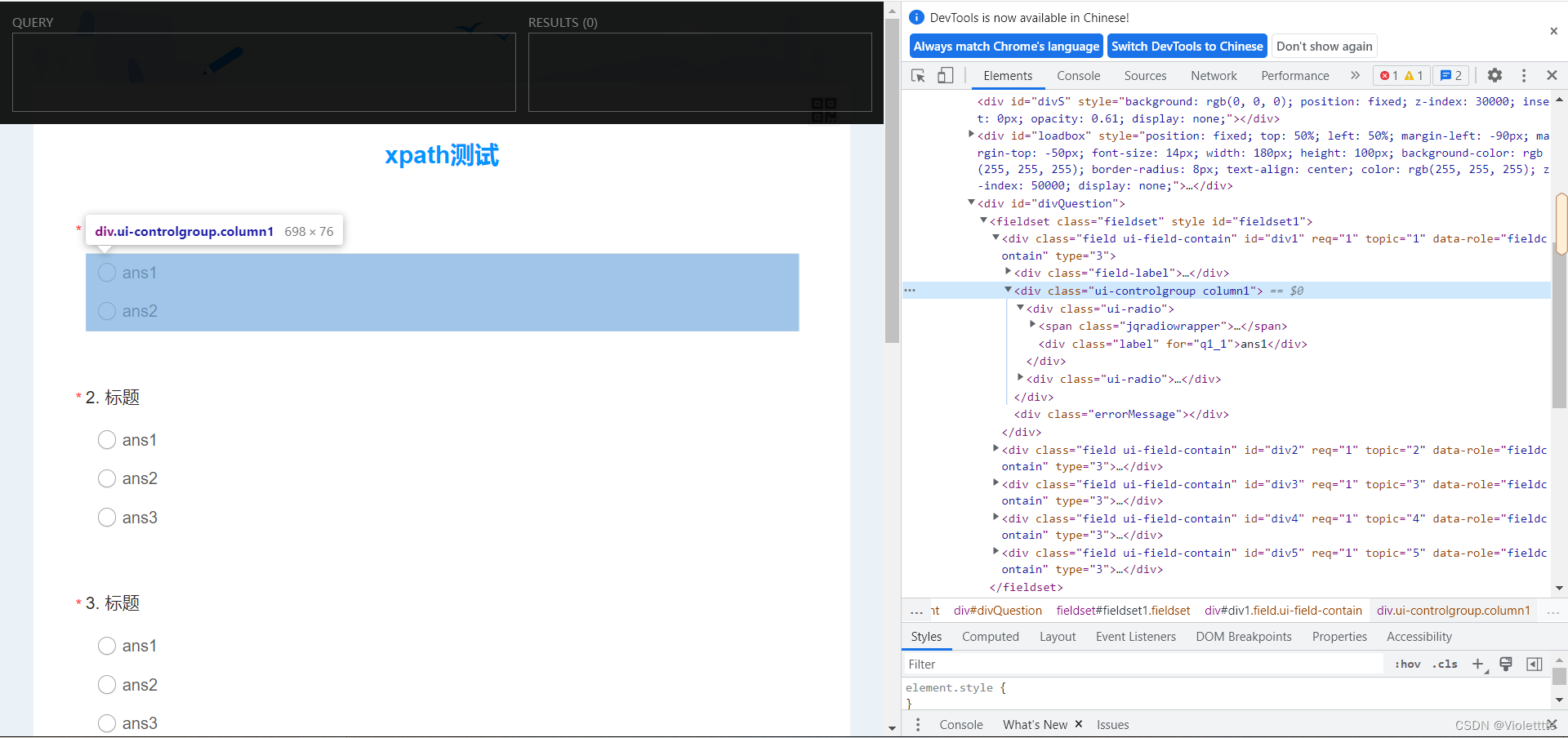
我们可以发现,这个框架其实是整个第一题框架下的第二个子标签,第一个子标签是class属性值为"field-label"的,这个标签的结果实际上就是标题的名字。所以,要实现定位到第二个div子标签有什么办法?
首先还要补充下,关于Xpath的规则,默认都是//开头,以前面的代码为例,//div[@id="div1"]会定位到符合id属性值等于div1的div标签,这个div标签相当于一个父标签,如果想要定位到这个父标签的子标签,则只能使用单斜杠。
例如,在上面的代码基础上添加/div,即整个代码为//div[@id="div1"]/div,那么显示的结果便如下
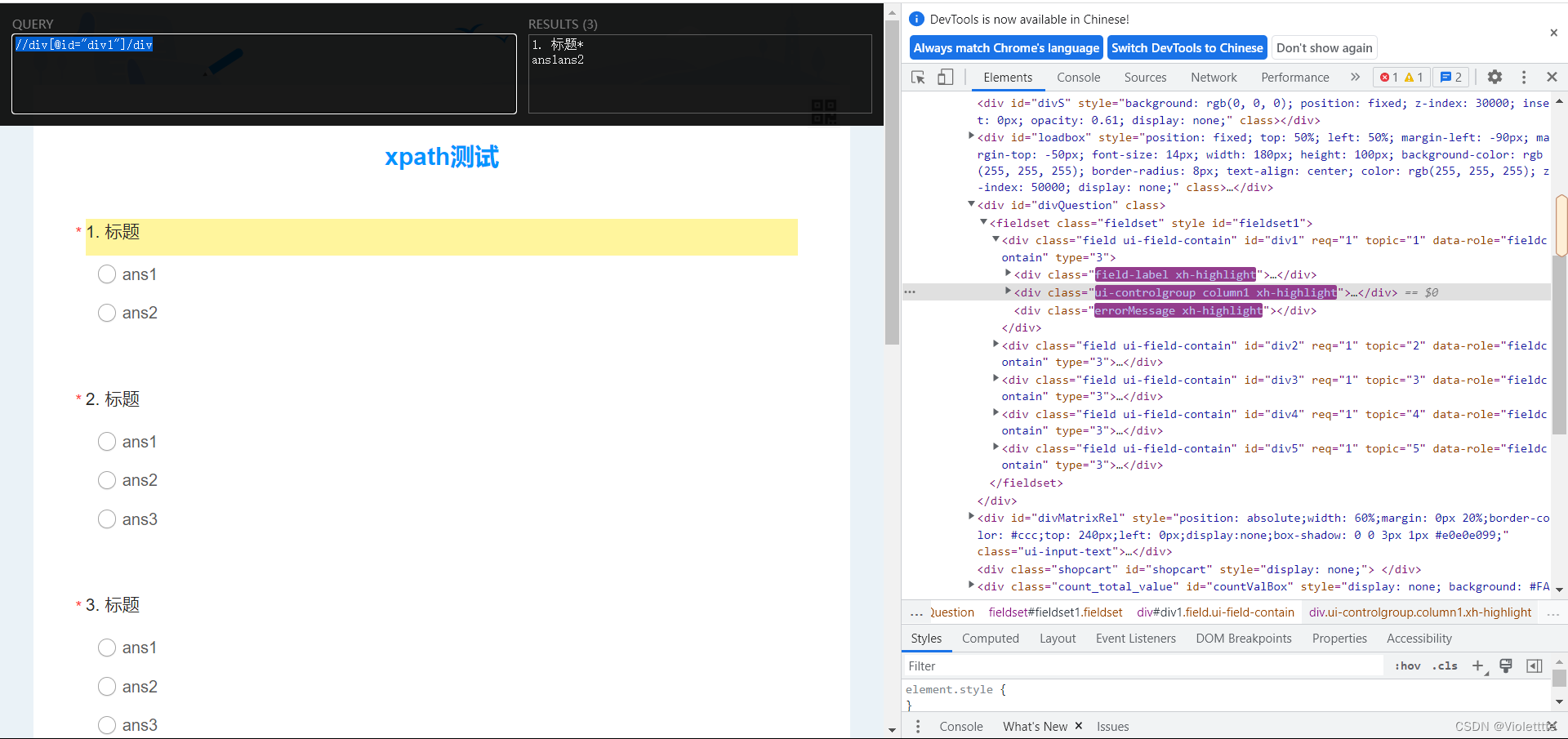
观察可以发现,整个框架下有3个div子标签,这三个标签都被选择到了。那么我们要选择三个标签中的第二个该怎么做?
有两种方法,第一种模仿前面的,通过[@属性名="属性值"]来解决,如图
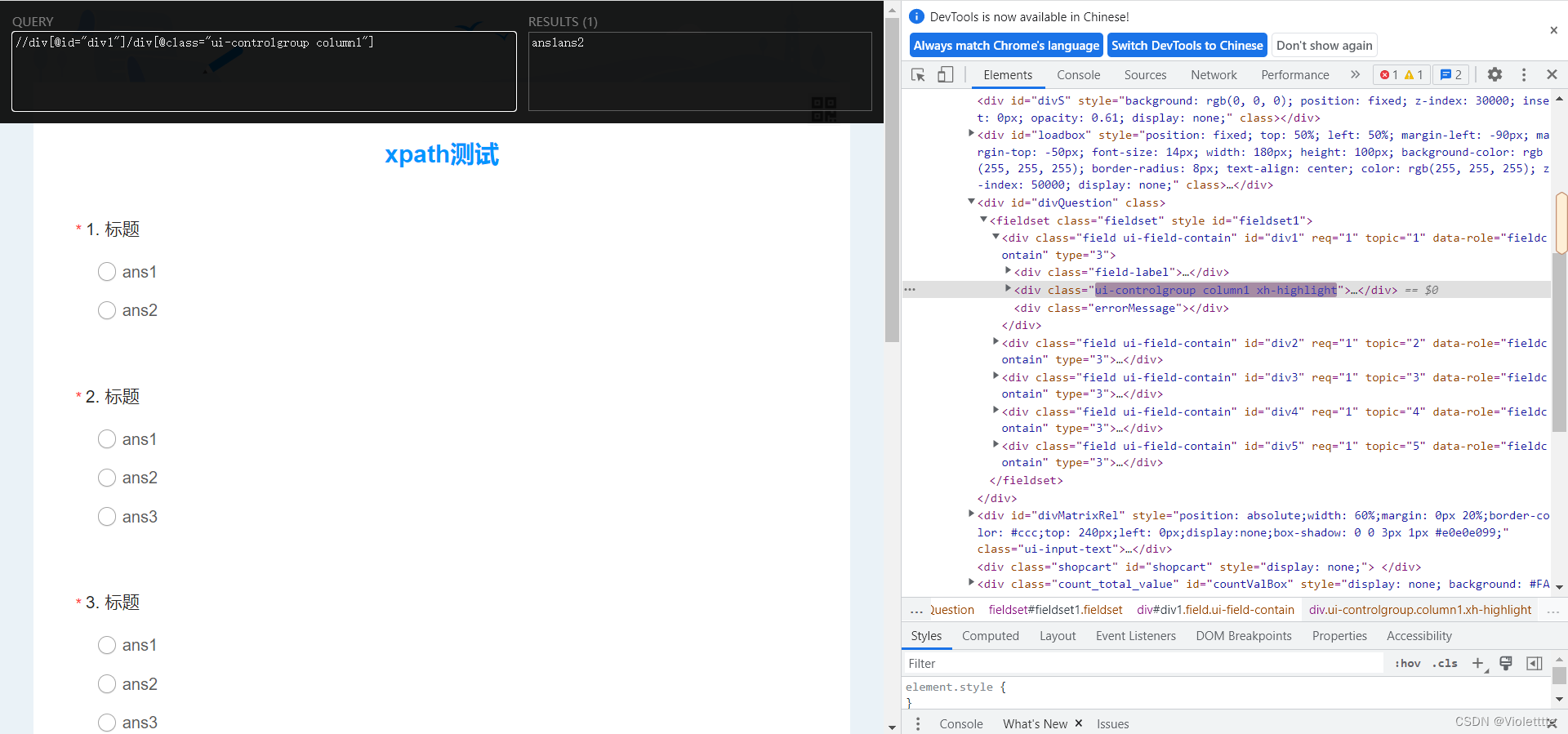 第二种方法,Xpath规则可以像python中的选择元素那样,直接通过括号来选择 [],但是,这里和python中的规则不完全一样,如果你要选择第一个子标签,你直接[1]就可以,不可以写[0],结果如下图。
第二种方法,Xpath规则可以像python中的选择元素那样,直接通过括号来选择 [],但是,这里和python中的规则不完全一样,如果你要选择第一个子标签,你直接[1]就可以,不可以写[0],结果如下图。
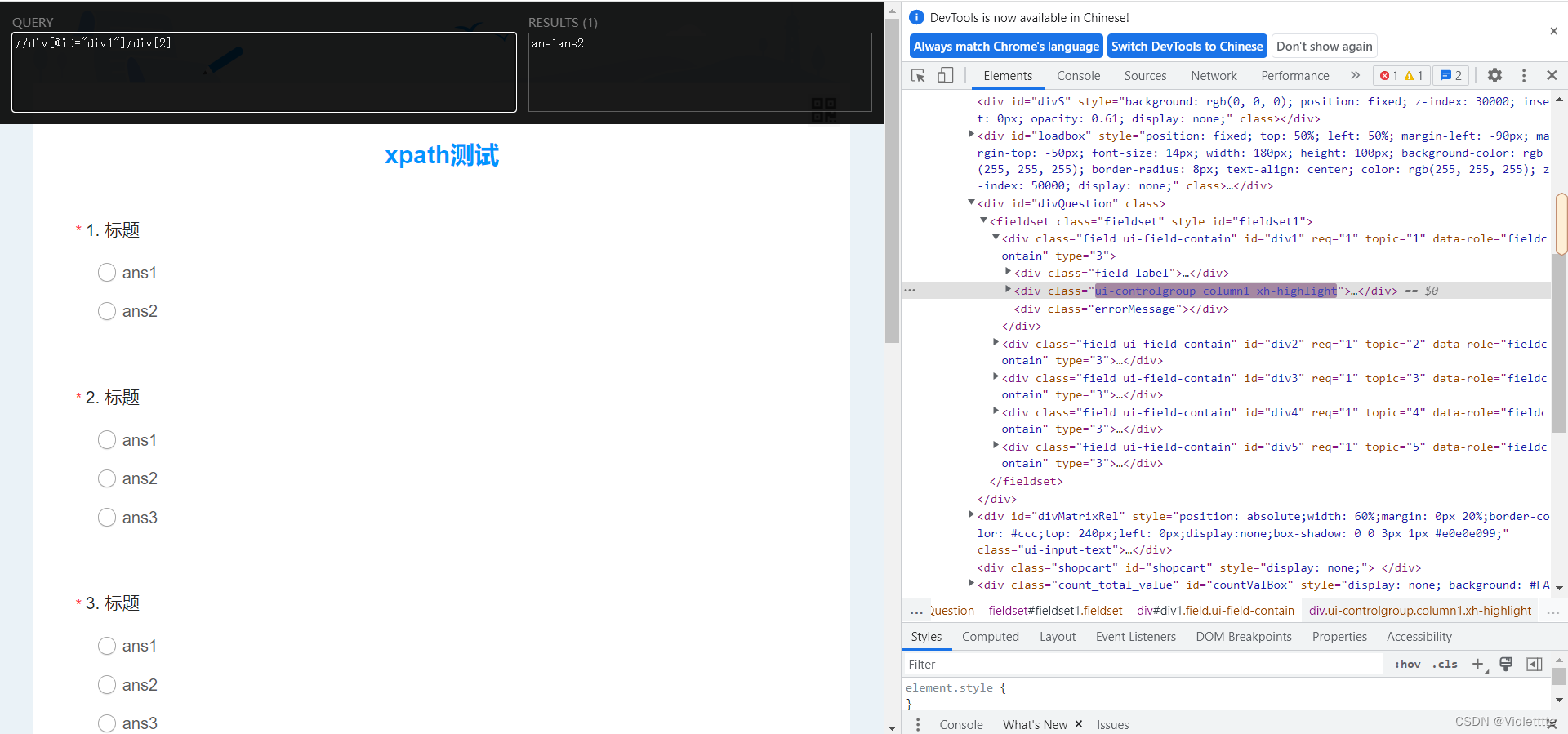
到了这,如果我要选择第一题的ans1节点,该怎么写你可能大概清楚了,可以自己通过插件尝试。
那么除了通过上述的逐层向下寻找的方式,即找到大框架,然后不断找子节点的方式,还有其他方式吗?
当然是有的,即直接查看第一题ans1的属性,如下图:

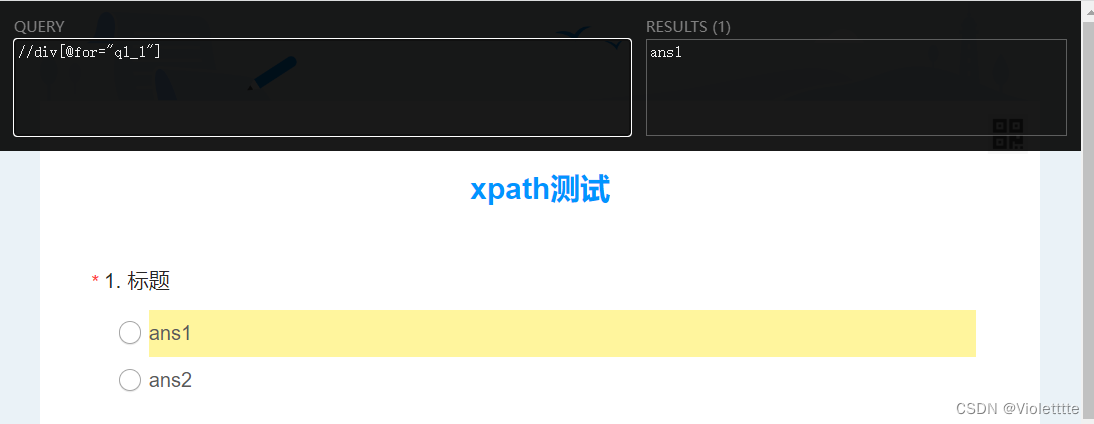
其实你可以发现,在这个问卷中,每一题的答案都有一个for属性,属性值的形式是qx_y,其中x是第几题,y是第几个选项,所以另一种方法是直接//div[@for="q1_1"] ,如下图,我们成功定位了
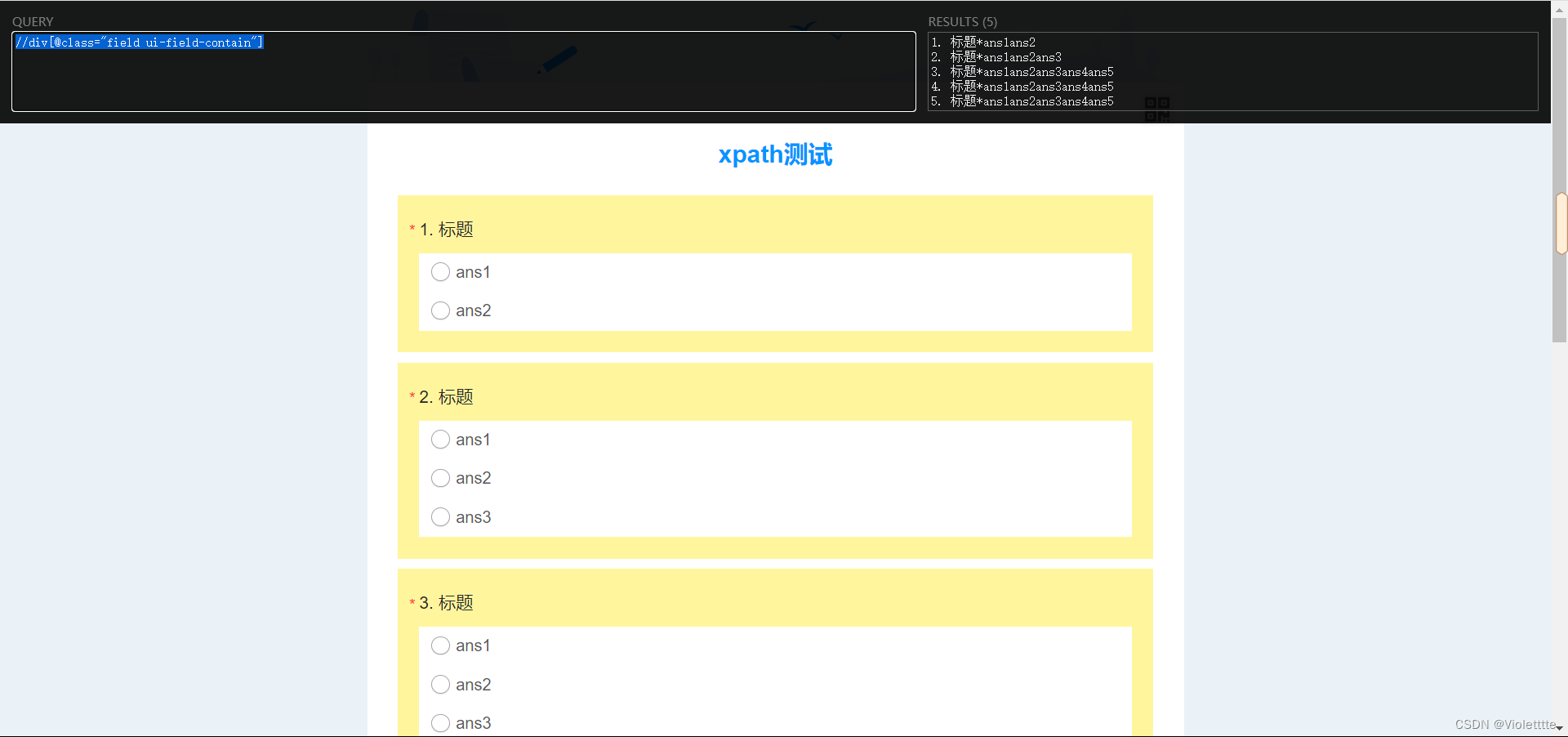
在前面提到的内容中,关于括号 [] 的用法实际上并没有那么简单,笔者在下面举两个例子进行解释。第一个例子,如果我直接写下//div[@class="field ui-field-contain"],即选择到每一个题的大框架,具体样子如下:
那在此基础之上,我添加一个[1],返回的是什么?结果如下
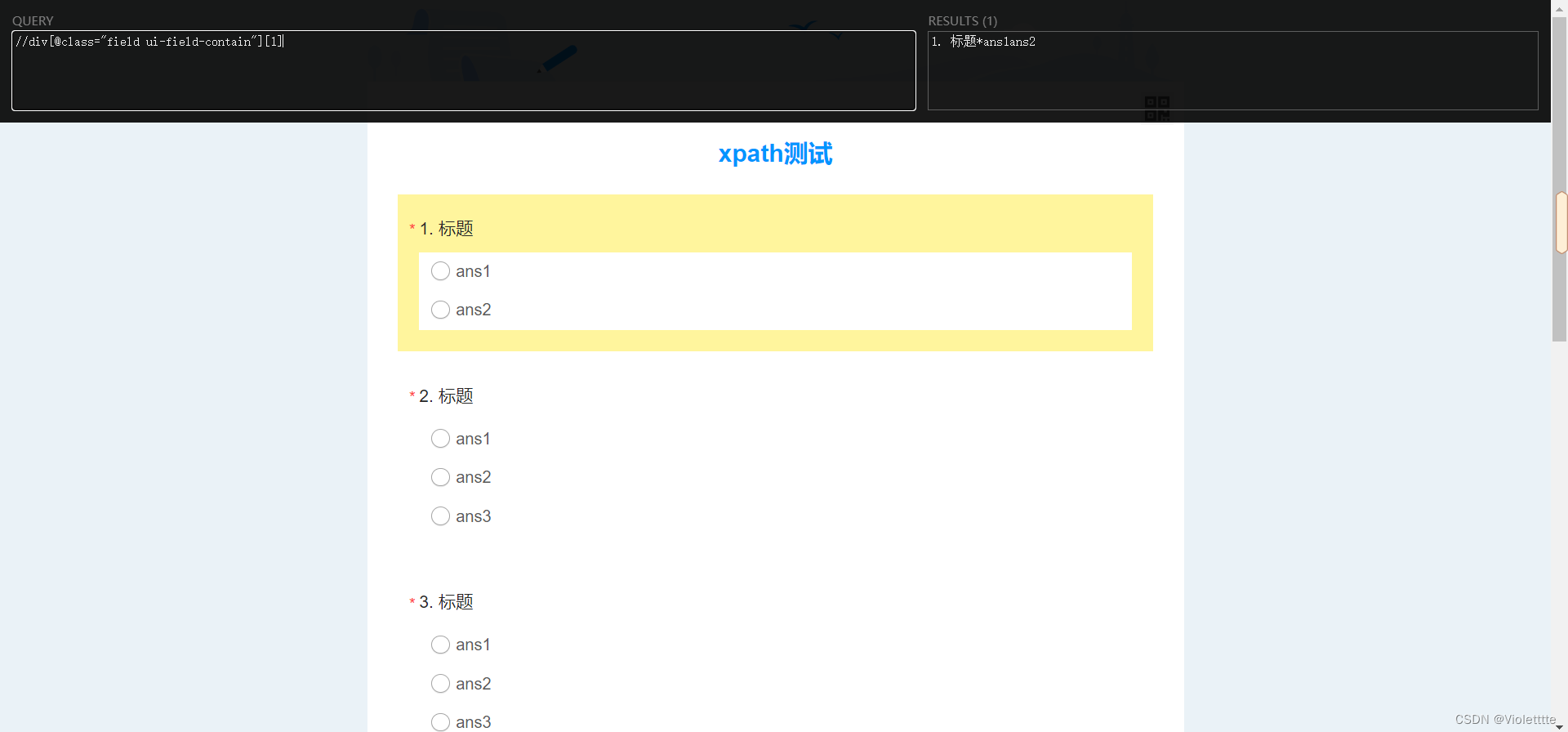
这和我们上面用 [] 选择第二个子节点时的效果似乎是一样的。
那如果,我们换一串代码,写成//div[@class="ui-radio"]呢?这一串代码中的class="ui-radio"实际上对应的就是每一个选项,如下图
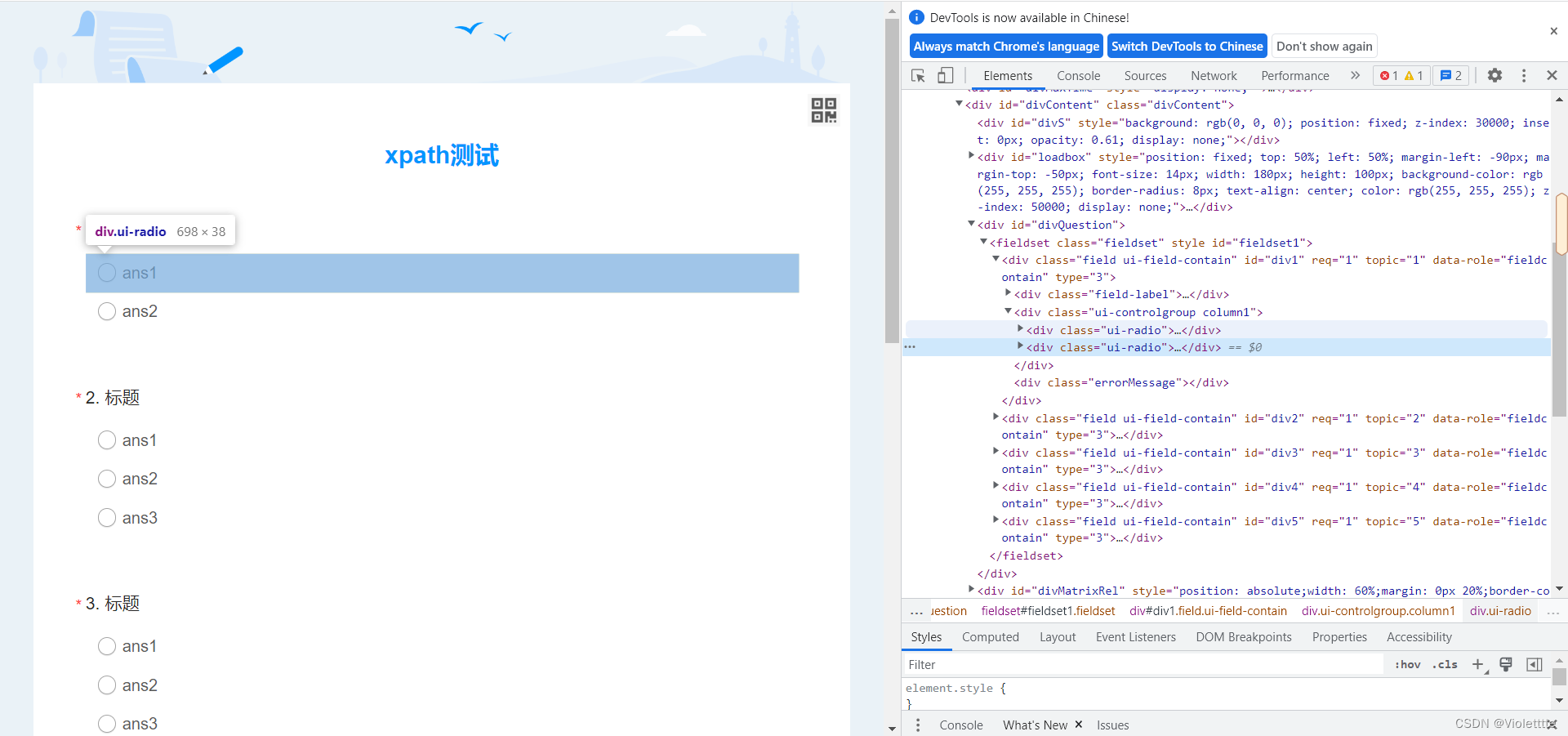
我们在xpath插件中输入上面的代码,观察结果
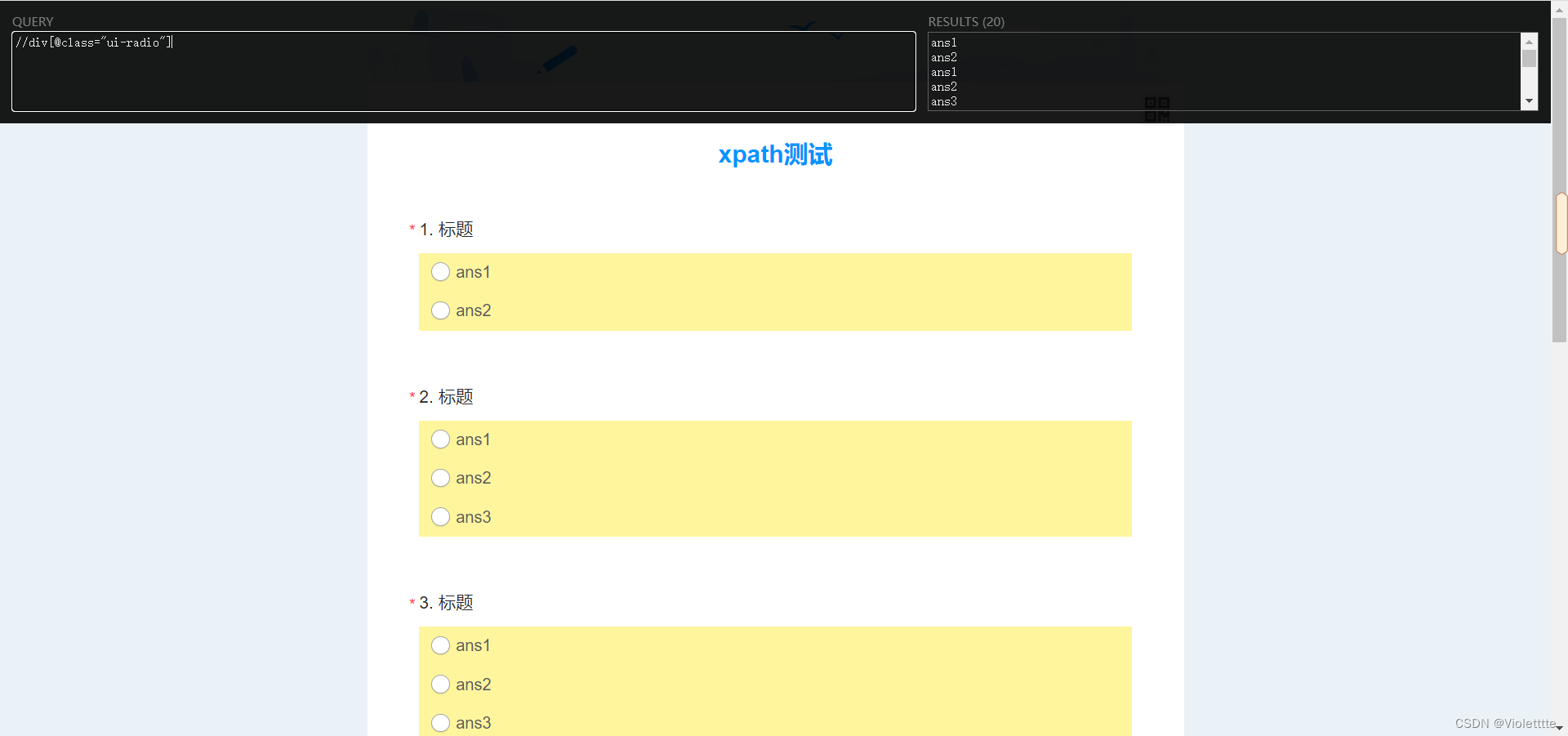
没错,整个页面的所有选项都被选中了,此时我们直接添加 [1] 会怎么样?
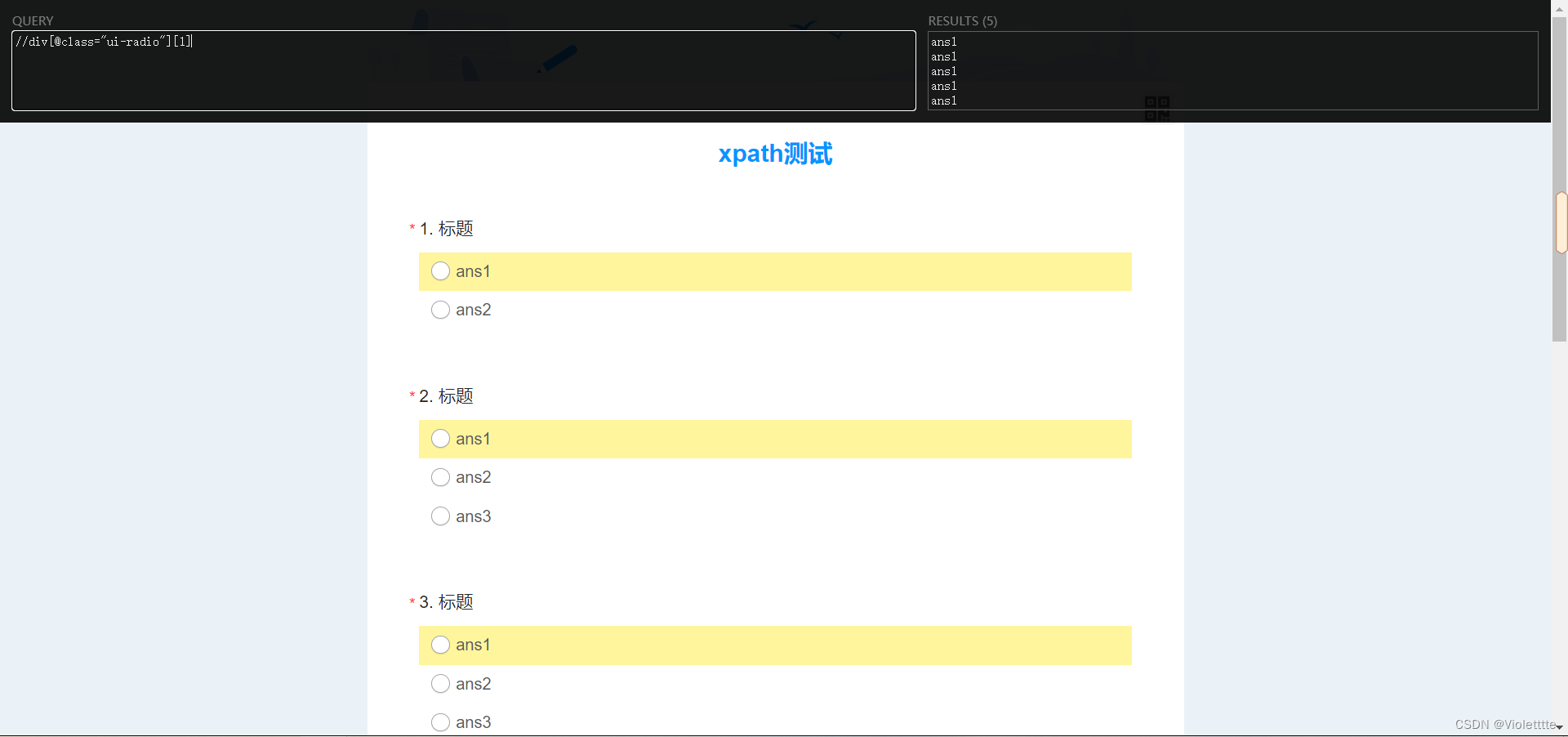
很奇怪,结果是把所有第一个选项选中,这是为什么?
分析一下,在第一个例子中,我们写下的//div[@class="field ui-field-contain"]会先选中每个题目对应的框架,这个问卷有5道题,所以返回的RESULTS有5个,这5个RESULTS彼此之间互为兄弟节点,且具有同一个父亲节点。
在第二个例子中,我们写下的//div[@class="ui-radio"]会选中每个选项,这5道题一共有20个选项,每个选项之间的关系并不如第一个那么简单,在这样的情况下,如果你直接写[1],只会返回所有其父亲节点的第一个选项。(即此题会返回整个选项框中的第一个 (因为每一个单独的选项的父节点就是整个选项框 ( 选项框不包含标题) ) )
我再举个例子,我们定位到每一题的标题,然后直接填[1]会怎么样?
我们先看,定位到标题的结果如下
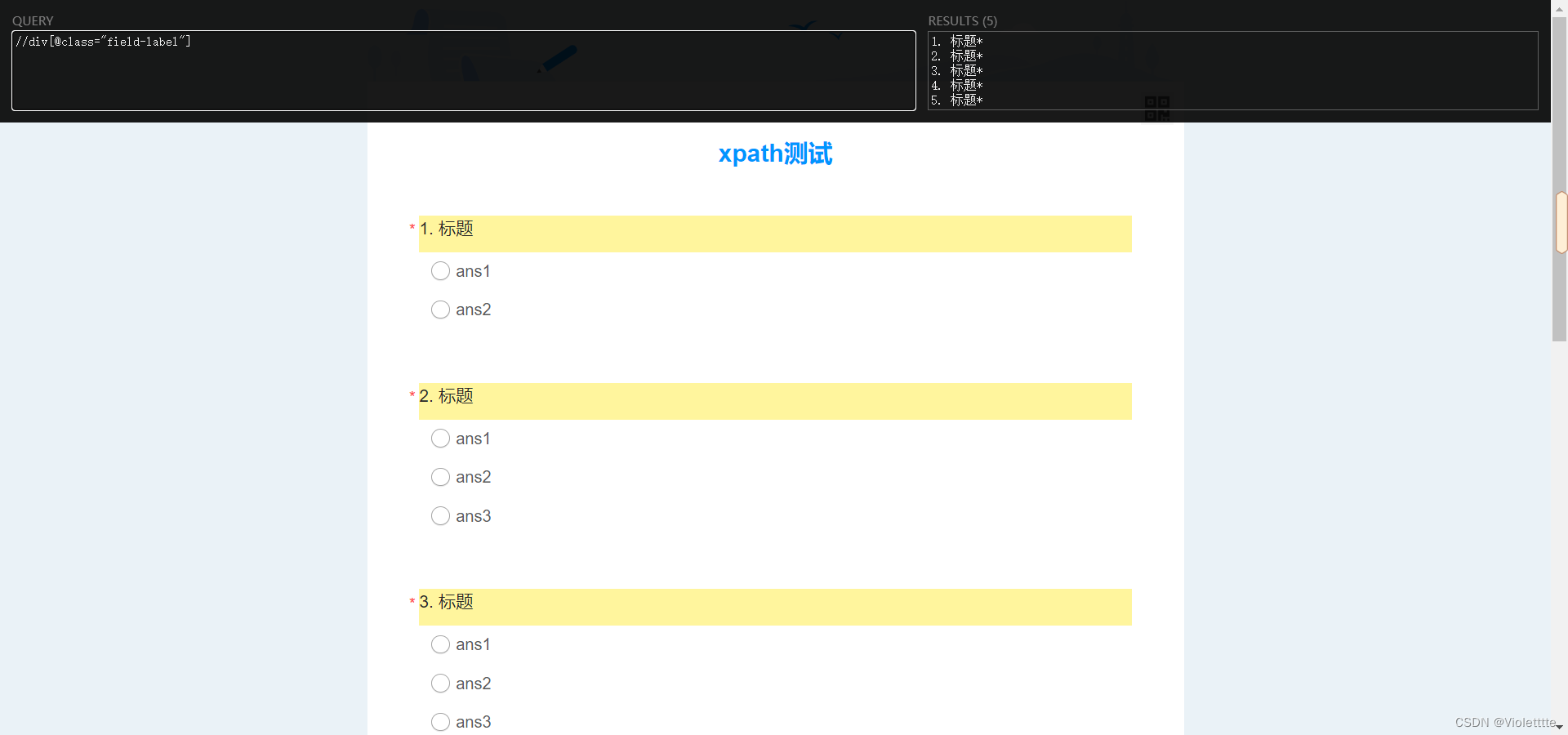
在此基础上添加一个[1]看看
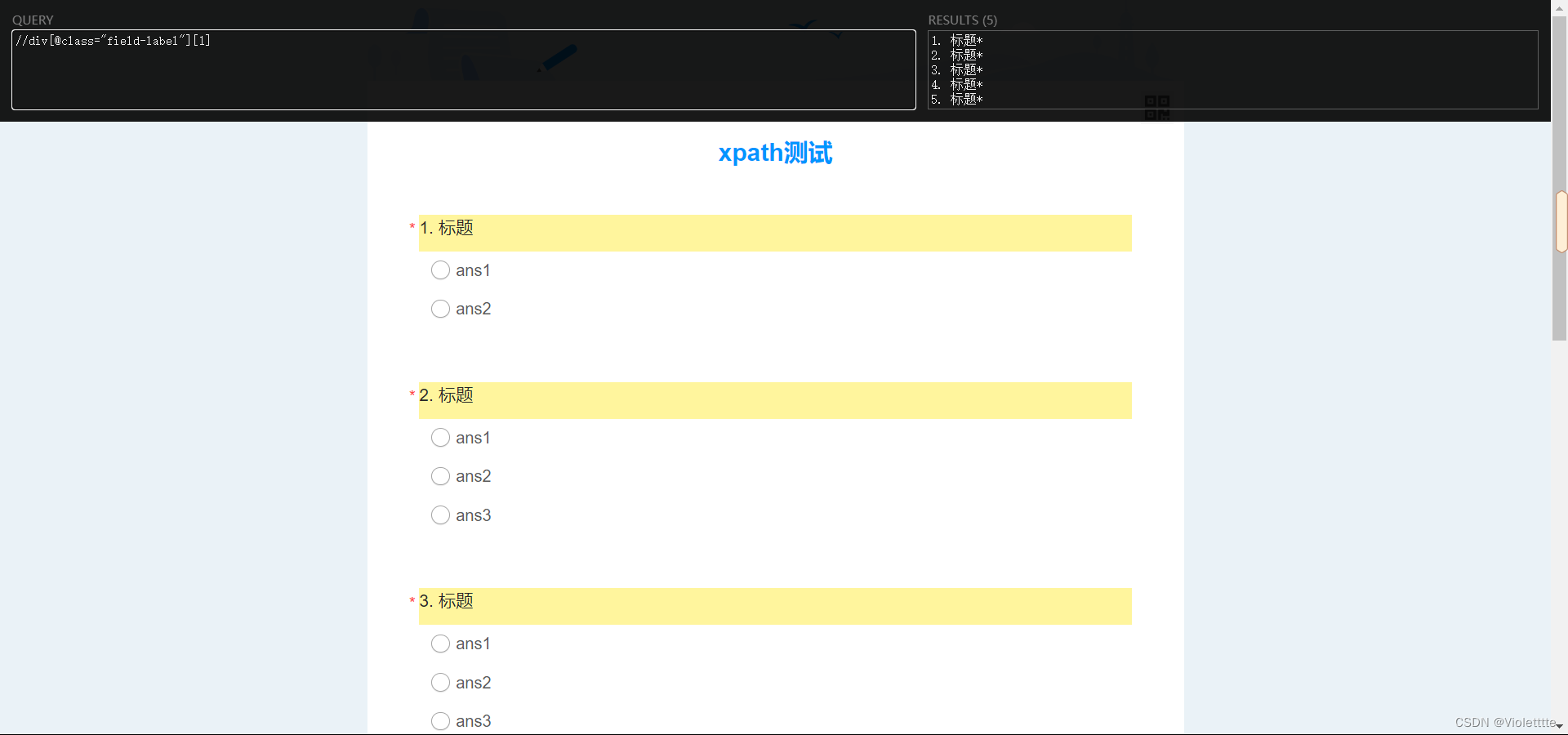 发现,添加了[1]之后的结果完全一样,这是为什么?其实按照上面的推理就很简单了,每个标题由于没有一个共同的父节点,所以添加[1]的结果是,返回到各自的父节点之后再选择第一个子节点,结果仍然是所有标题。
发现,添加了[1]之后的结果完全一样,这是为什么?其实按照上面的推理就很简单了,每个标题由于没有一个共同的父节点,所以添加[1]的结果是,返回到各自的父节点之后再选择第一个子节点,结果仍然是所有标题。

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









