 阿里云团队在ICCV2021 MFR挑战赛中夺魁:人物身份鉴别技术解析
阿里云团队在ICCV2021 MFR挑战赛中夺魁:人物身份鉴别技术解析






1. 引言
10月11-17日,万众期待的国际计算机视觉大会 ICCV 2021 (International Conference on Computer Vision) 在线上如期举行,受到全球计算机视觉领域研究者的广泛关注。
今年阿里云多媒体 AI 团队(由阿里云视频云和达摩院视觉团队组成)参加了 MFR 口罩人物身份鉴别全球挑战赛,并在总共5个赛道中,一举拿下1个冠军、1个亚军和2个季军,展现了我们在人物身份鉴别领域深厚的技术积淀和业界领先的技术优势。
2. 竞赛介绍
MFR口罩人物身份鉴别全球挑战赛是由帝国理工学院、清华大学和InsightFace.AI联合举办的一次全球范围内的挑战赛,主要为了解决新冠疫情期间佩戴口罩给人物身份鉴别算法带来的挑战。竞赛从6月1日开始至10月11日结束,历时4个多月,共吸引了来自全球近400支队伍参赛,是目前为止人物身份鉴别领域规模最大、参与人数最多的权威赛事。据官方统计,此次竞赛收到的总提交次数超过10000次,各支队伍竞争异常激烈。
2.1 训练数据集
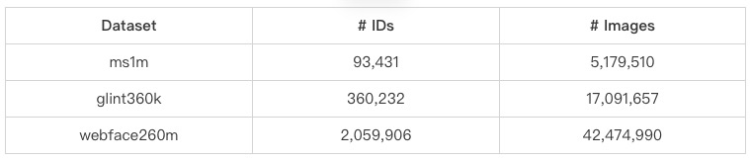
此次竞赛的训练数据集只能使用官方提供的3个数据集,不允许使用其它额外数据集以及预训练模型,以保证各算法对比的公平公正性。官方提供的3个数据集,分别是ms1m小规模数据集、glint360k中等规模数据集和webface260m大规模数据集,各数据集包含的人物ID数和图片数如下表所示:
2.2 评测数据集
此次竞赛的评测数据集包含的正负样本对规模在万亿量级,是当前业界规模最大、包含信息最全的权威评测数据集。值得注意的是所有评测数据集均不对外开放,只提供接口在后台进行自动测评,避免算法过拟合测试数据集。
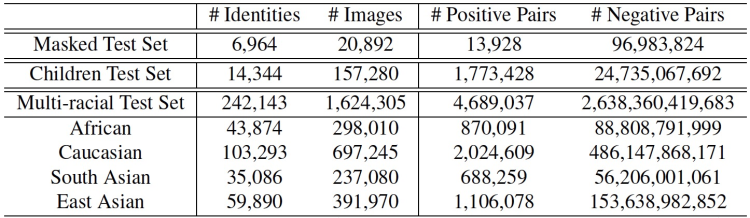
InsightFace赛道评测数据集的详细统计信息如下表所示:
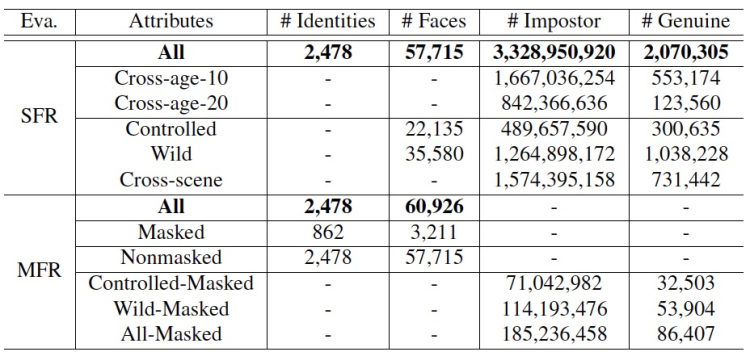
WebFace260M赛道评测数据集的详细统计信息如下表所示:
2.3 评测指标
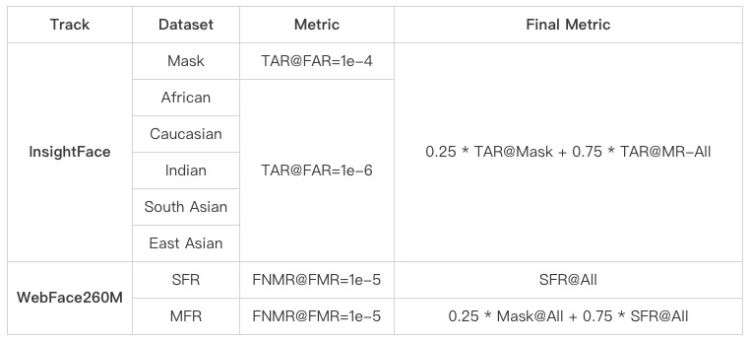
此次竞赛的评测指标不仅有性能方面的指标,而且还包含特征维度和推理时间的限制,因此更加贴近真实业务场景。详细的评测指标如下表所示:

3. 解决方案
下面,我们将从数据、模型、损失函数等方面,对我们的解决方案进行逐一解构。
3.1 基于自学习的数据清洗
众所周知,人物身份鉴别相关的训练数据集中广泛存在着噪声数据,例如同一人物图片分散到不同人物ID下、多个人物图片混合在同一人物ID下,数据集中的噪声会对识别模型的性能产生较大影响。针对上述问题,我们提出了基于自学习的数据清洗框架,如下图所示:
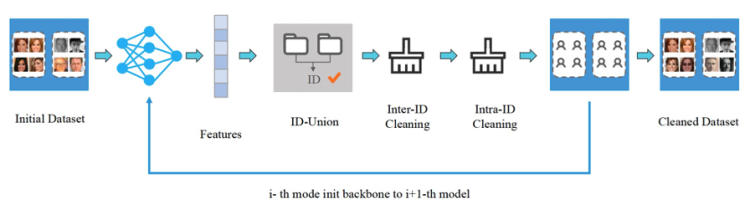
首先,我们使用原始数据训练初始模型M0,然后使用该模型进行特征提取、ID合并、类间清洗和类内清洗等一系列操作。对于每个人物ID,我们使用DBSCAN聚类算法去计算中心特征,然后使用中心特征进行相似度检索,这一步使用的高维向量特征检索引擎是达摩院自研的Proxima,它可以快速、精准地召回Doc中与Query记录相似度最高的topK个结果。紧接着,我们使用清洗完成的数据集,训练新的模型M1,然后重复数据清洗及新模型训练过程,通过不断进行迭代自学习方式,使得数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









