






现在我的电脑已经安装配置 CUDA11.2,,cudnn11.2,vs2019.
他们的安装方法可以参考我的博客如下:
(105条消息) 2022最详细,最新的 Win11/WIN10 安装CUDA11.2和cuDNN(必坑之作)完美教程_Vertira的博客-优快云博客_cuda11.2
(105条消息) win11+显卡驱动+CUDA+CUDNN对应版本安装_Vertira的博客-优快云博客
我这里从TensorRT下载开始
官网下载地址:
NVIDIA TensorRT 8.x Download | NVIDIA Developer
先注册会员下载 。
下载window10版本,win11 应该能用,支持CUDA11.1,11.2,11.3,11.4,,11.5,11.6
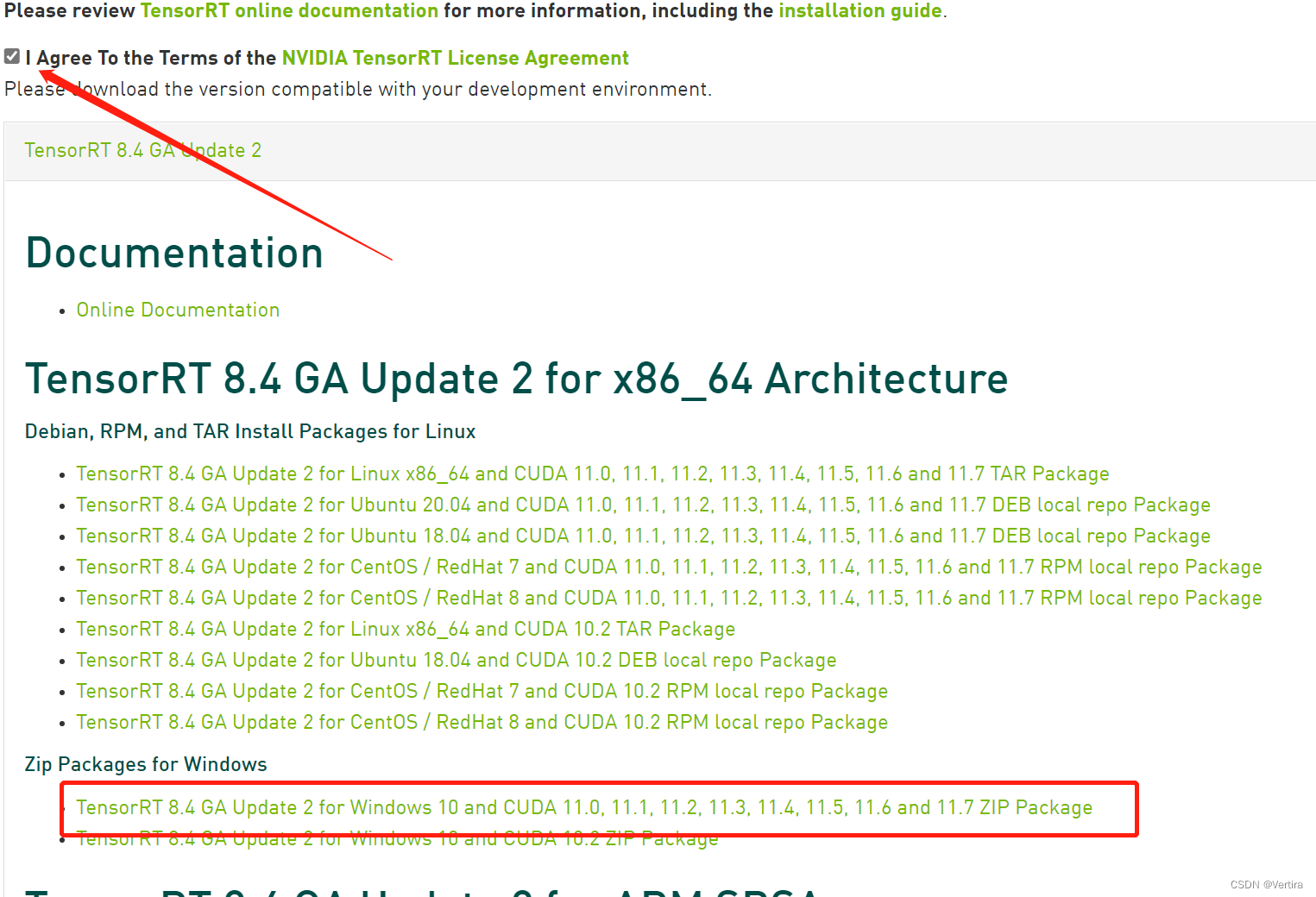
下载完后,

然后放到指定的位置解压 ,下面就是解压。
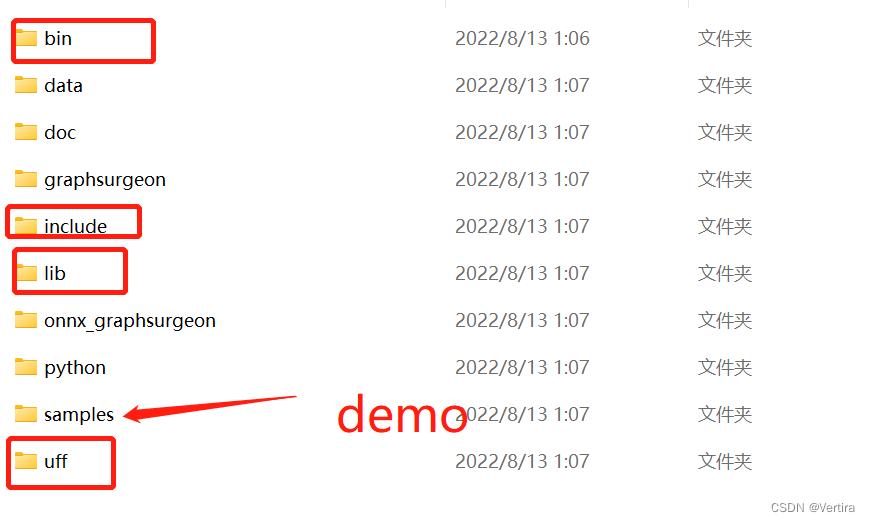
需要的文件都有。
这里只写C++部署,python部署这里忽略
下面就要配置一下,和配置opencv 有点相同,也有点不同
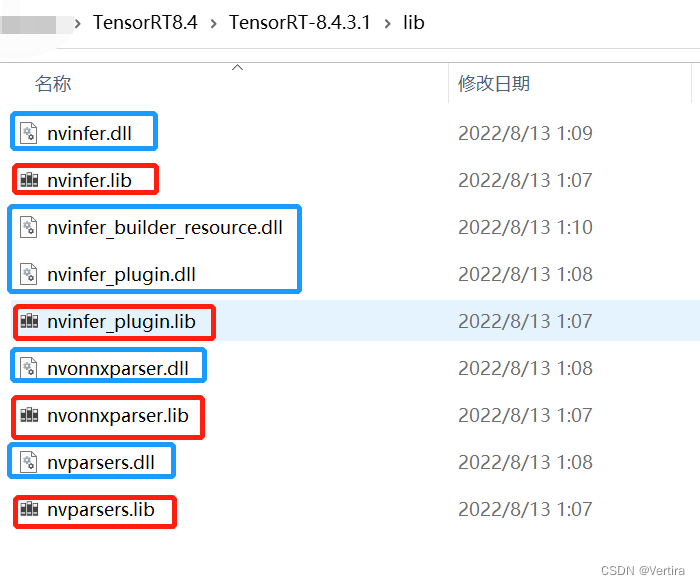
1)把这个路径添加到系统环境变量中,
2)复制lib目录下的dll文件到cuda的bin下。
1) 环境变量:系统的path ,如下
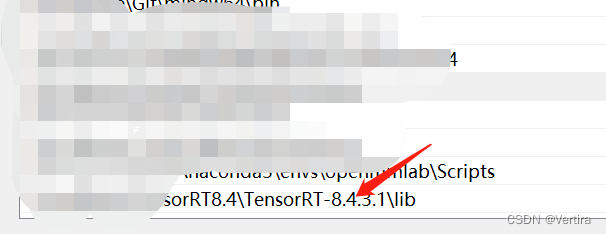
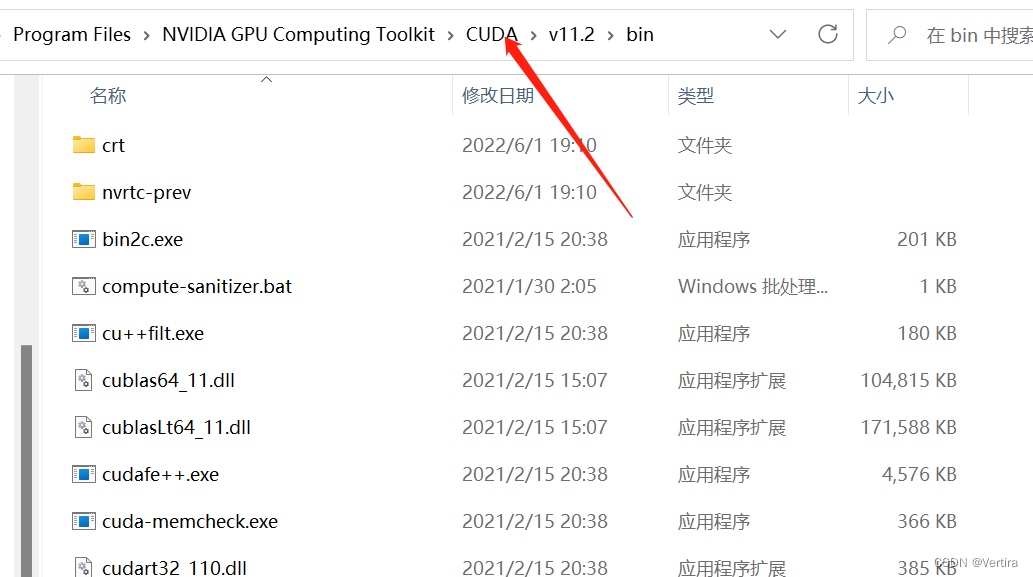
2)找到自己安装的CUDA路径
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin [根据自己的cuda安装路径即可]
4 安装uff和graphsurgeon
打开conda的虚拟环境 ,分别cd 到 graphsurgeon,uf 的文件夹在,分别执行下面两个命令
pip install graphsurgeon-0.4.6-py2.py3-none-any.whl
pip install uff-0.6.9-py2.py3-none-any.whl文件名称要正确
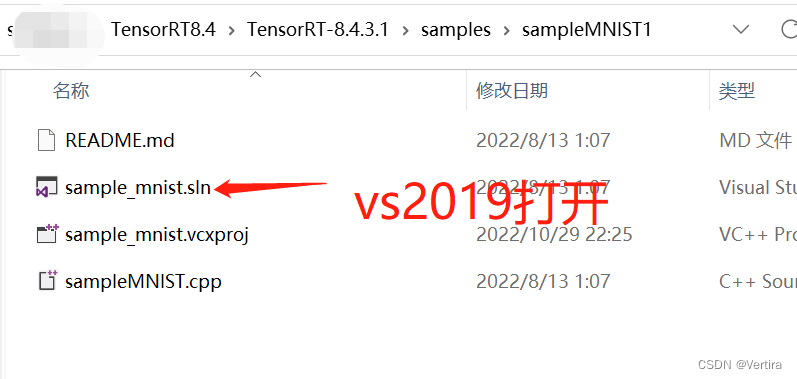
5 VS 2019配置TensorRT并测试
找到sample_mnist.sln,用vs2019打开
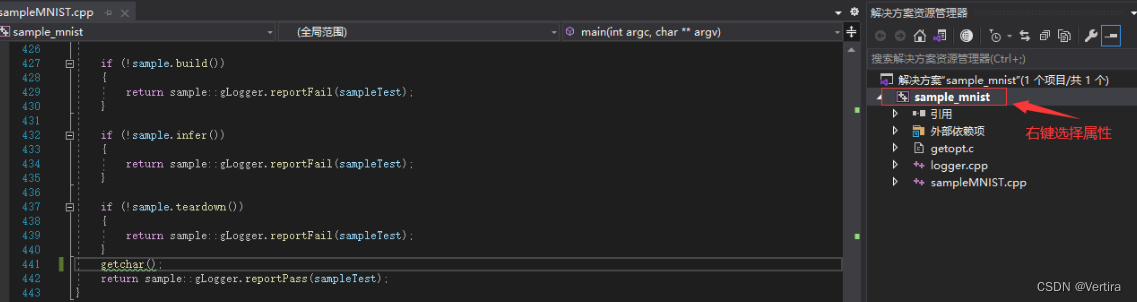
配置一下tensorRT,和配置opencv雷同,
首先,VC++目录,包含目录(就是include文件夹),库目录,就是刚才的lib所在文件夹
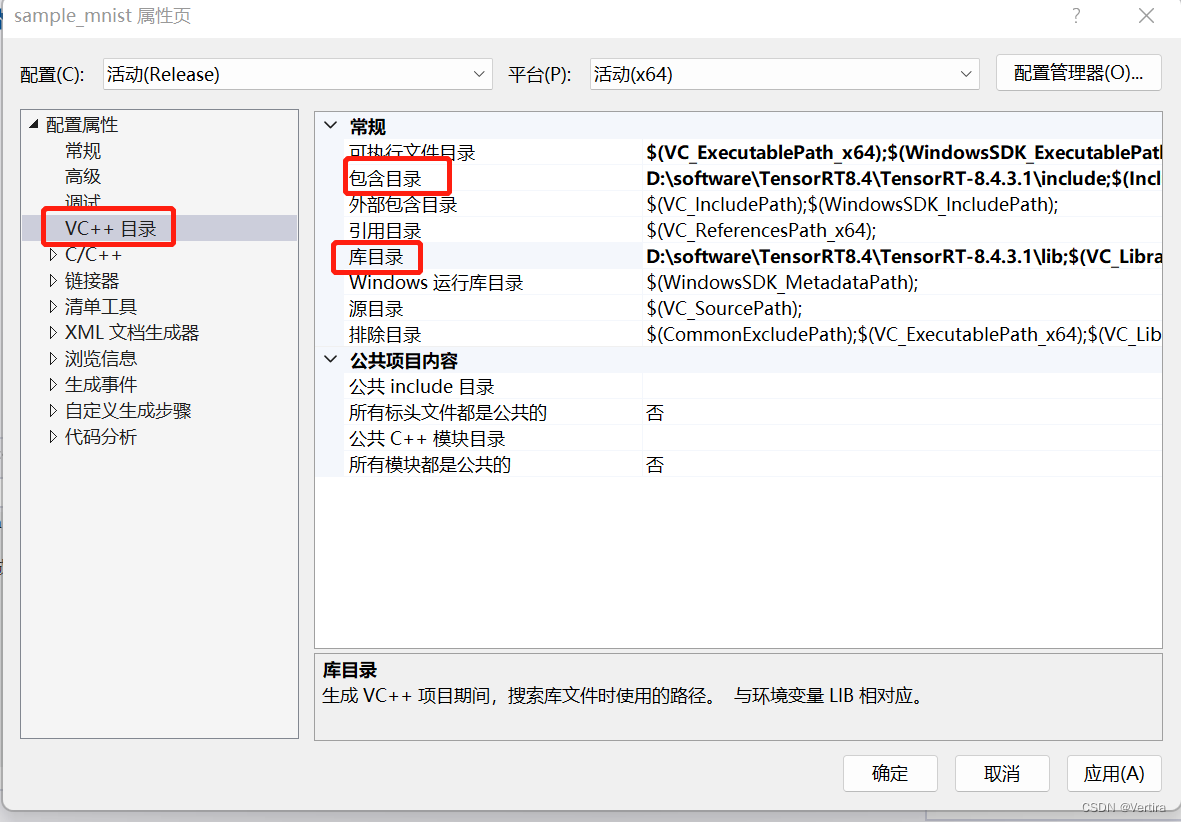
添加依赖项
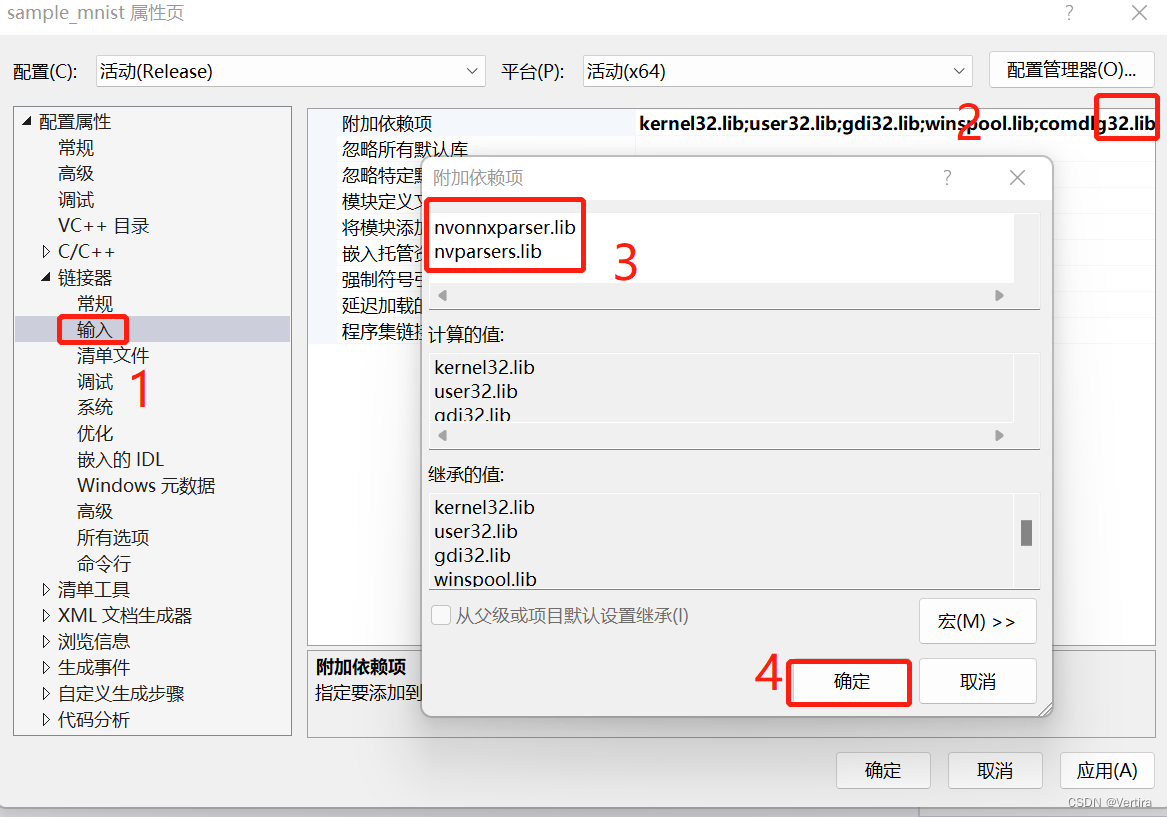
然后
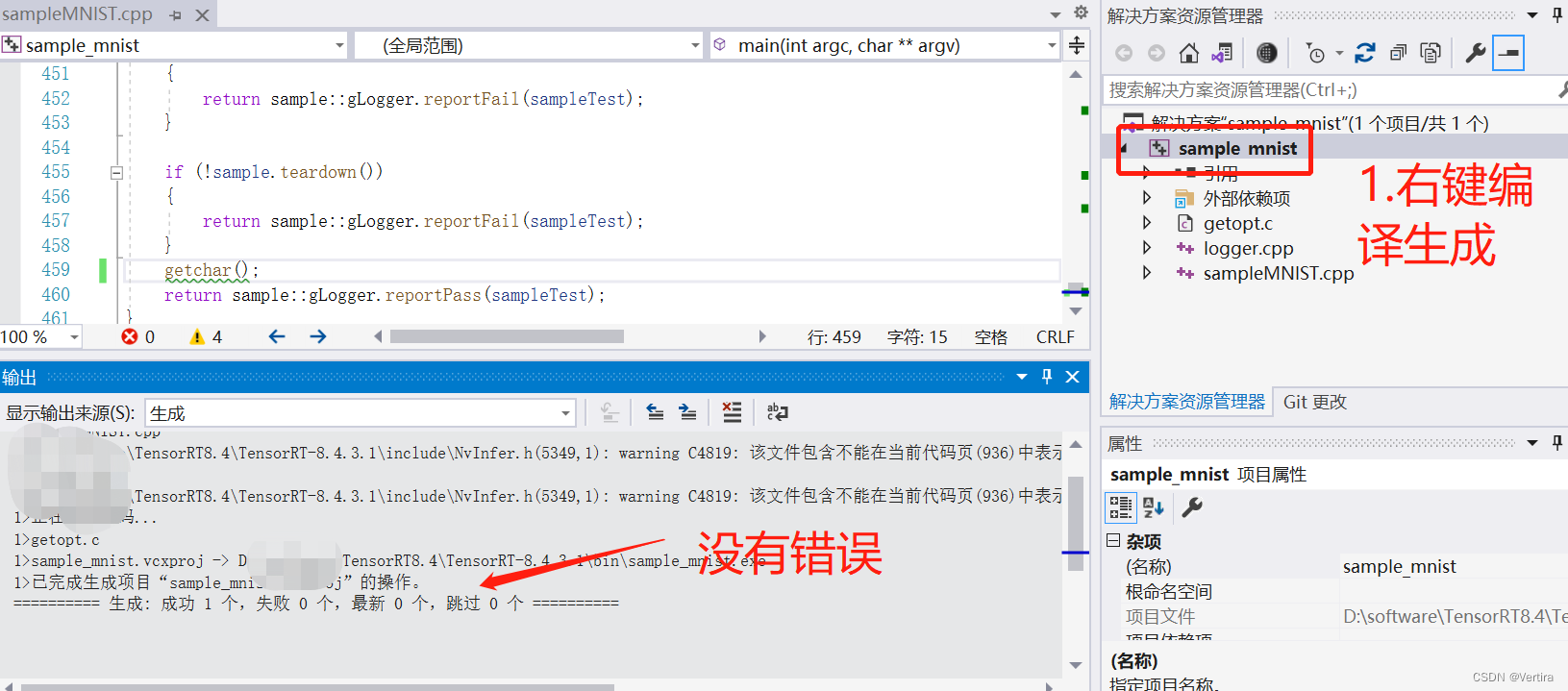
为了防止后面执行exe操作闪退,添加getchar()到main函数下(不加会有卡顿,亲测)
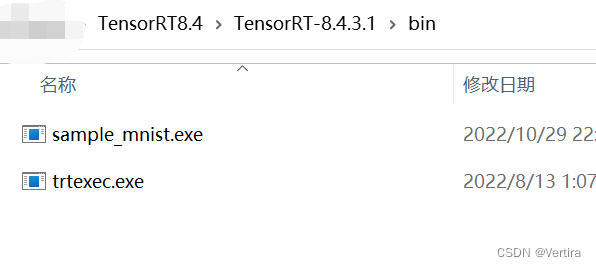
编译成功后,会在 TensorRT8.4\TensorRT-8.4.3.1\bin路径下生成文件sample_mnist.exe
这是一个可执行文件。
测试数据(运行图中的py文件)
运行,双击bin文件夹下的sample_mnist.exe
&&&& RUNNING TensorRT.sample_mnist [TensorRT v8403] # D:\******\TensorRT8.4\TensorRT-8.4.3.1\bin\sample_mnist.exe
[10/29/2022-22:51:36] [I] Building and running a GPU inference engine for MNIST
[10/29/2022-22:51:38] [I] [TRT] [MemUsageChange] Init CUDA: CPU +385, GPU +0, now: CPU 10713, GPU 1132 (MiB)
[10/29/2022-22:51:39] [I] [TRT] [MemUsageChange] Init builder kernel library: CPU +335, GPU +104, now: CPU 11240, GPU 1236 (MiB)
[10/29/2022-22:51:40] [W] [TRT] The implicit batch dimension mode has been deprecated. Please create the network with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH flag whenever possible.
[10/29/2022-22:51:44] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +690, GPU +272, now: CPU 11803, GPU 1508 (MiB)
[10/29/2022-22:51:48] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +461, GPU +264, now: CPU 12264, GPU 1772 (MiB)
[10/29/2022-22:51:48] [W] [TRT] TensorRT was linked against cuDNN 8.4.1 but loaded cuDNN 8.2.1
[10/29/2022-22:51:48] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[10/29/2022-22:52:04] [I] [TRT] Detected 1 inputs and 1 output network tensors.
[10/29/2022-22:52:04] [I] [TRT] Total Host Persistent Memory: 9136
[10/29/2022-22:52:04] [I] [TRT] Total Device Persistent Memory: 0
[10/29/2022-22:52:04] [I] [TRT] Total Scratch Memory: 0
[10/29/2022-22:52:04] [I] [TRT] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 0 MiB, GPU 0 MiB
[10/29/2022-22:52:04] [I] [TRT] [BlockAssignment] Algorithm ShiftNTopDown took 0.0454ms to assign 3 blocks to 10 nodes requiring 92164 bytes.
[10/29/2022-22:52:04] [I] [TRT] Total Activation Memory: 92164
[10/29/2022-22:52:04] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
[10/29/2022-22:52:04] [I] [TRT] [MemUsageChange] Init CUDA: CPU +0, GPU +0, now: CPU 12669, GPU 1894 (MiB)
[10/29/2022-22:52:04] [I] [TRT] Loaded engine size: 1 MiB
[10/29/2022-22:52:04] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
[10/29/2022-22:52:04] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
[10/29/2022-22:52:04] [I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@.*@@@@@@@@@@
@@@@@@@@@@@@@@@@.=@@@@@@@@@@
@@@@@@@@@@@@+@@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@+ *@@:-@@@@@@@@@@
@@@@@@@@@@@= *@@= @@@@@@@@@@
@@@@@@@@@@@. #@@= @@@@@@@@@@
@@@@@@@@@@= =++.-@@@@@@@@@@
@@@@@@@@@@ =@@@@@@@@@@
@@@@@@@@@@ :*## =@@@@@@@@@@
@@@@@@@@@@:*@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@* *@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@=.@@@@@@@@@@@
@@@@@@@@@@@@@@@++@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[10/29/2022-22:52:04] [I] Output:
0:
1:
2:
3:
4: **********
5:
6:
7:
8:
9:
到这里 看出只能证明 cuda,cudnn,cpu ,tensorRT配置成功(但是没有配置opencv,我没有配置,如果你要部署YOLO,opencv是必不可少的)。
测试一个项目:
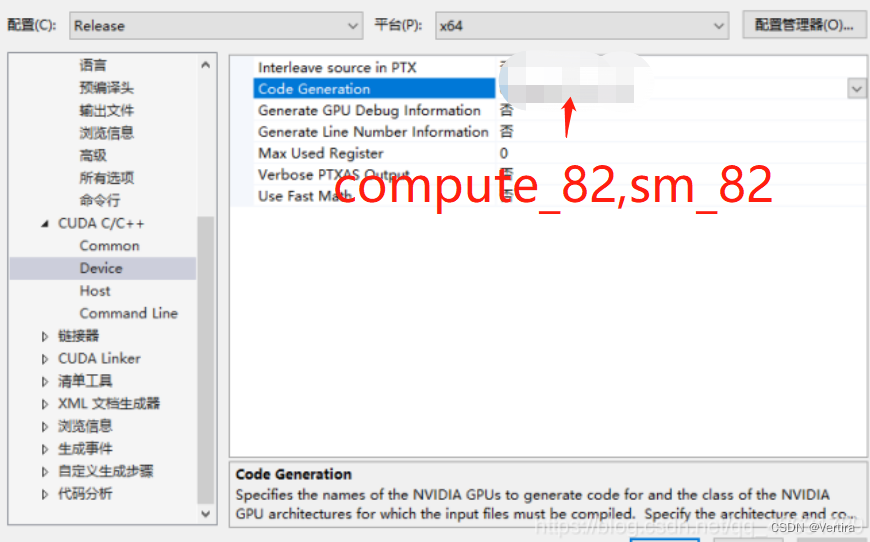
我查了一下我的GPU的算力,后面会用到。
W0708 10:08:38.641642 17232 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 11.6, Runtime API Version: 11.2
W0708 10:08:38.688902 17232 gpu_context.cc:306] device: 0, cuDNN Version: 8.2.
我的GPU的算例是 8.2
项目地址:tensorrt跨平台部署
 https://gitcode.net/mirrors/enazoe/yolo-tensorrt?utm_source=csdn_github_accelerator
https://gitcode.net/mirrors/enazoe/yolo-tensorrt?utm_source=csdn_github_accelerator把这个项目下载下来
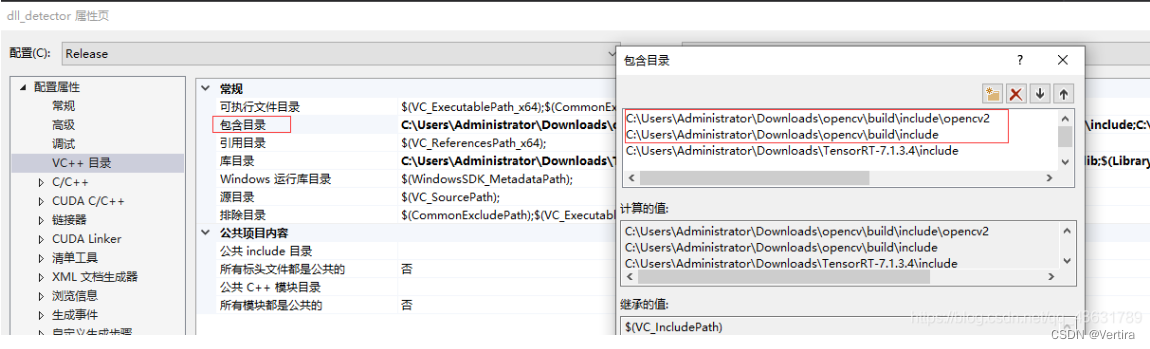
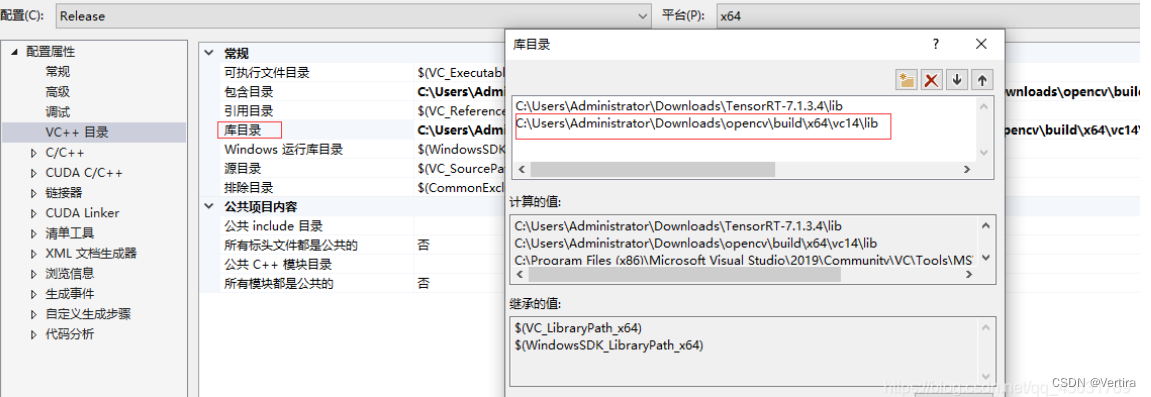
vs2019打开,和上面的一样,唯一的区别是 还需要配置opencv,感觉版本高点好opencv4.x应该可以。
这个opencv3.x,4.x配置方法,网上多的是。这里我简化了。
1)配置好TensorRT,
2)配置opencv
修改算力值,这个要根据显卡支持的算力来改,我的3060算力8.2
c++17报错解决
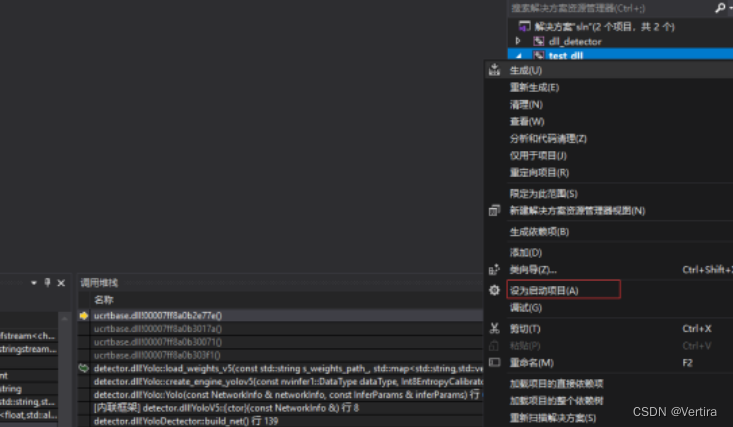
在右键属性配置种把test编译成exe ,detect编译成动态库,然后把test设成启动项
如何把Ubuntu训练的模型 放在电脑上部署 我还在研究,会陆续更新进展



















 5526
5526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









