




 本文详细介绍了Java集合框架,包括常用的集合类、List、Set、Map的区别、底层数据结构、线程安全的集合、迭代器机制、快速失败与安全失败机制、Array与ArrayList的区别等,并深入探讨了HashSet的工作原理、HashMap的设计理念及其实现细节。
本文详细介绍了Java集合框架,包括常用的集合类、List、Set、Map的区别、底层数据结构、线程安全的集合、迭代器机制、快速失败与安全失败机制、Array与ArrayList的区别等,并深入探讨了HashSet的工作原理、HashMap的设计理念及其实现细节。
Java集合
1.常用的集合类有哪些?
Map接口和Collection接口是所有集合框架的父接口。
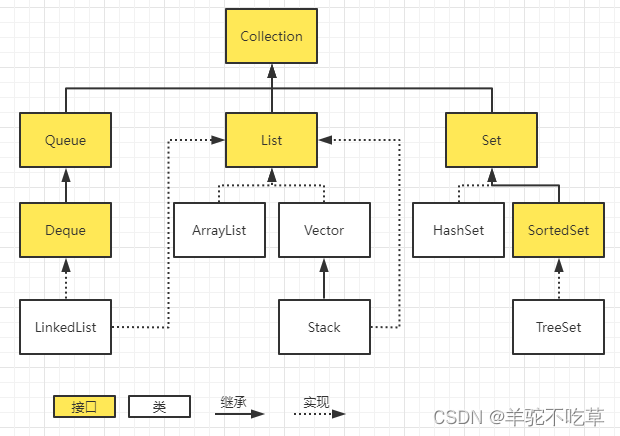
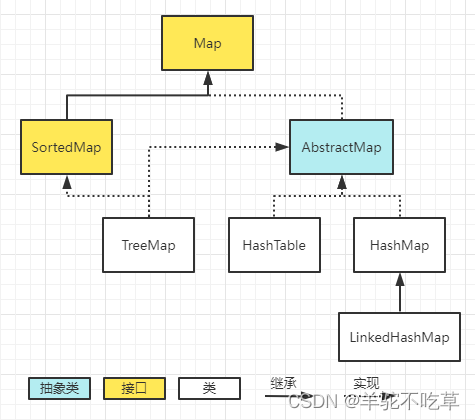
2.List、Set、Map三者的区别
- List:有序集合,存入和取出顺序相同,可存储重复元素,可存储多个null
- Set:无序集合,存入和取出顺序不同,不可存储重复元素,只能存储一个null
- Map:使用键值对的方式对元素进行存储,key是无序且唯一的,value值不唯一
3.常用集合框架底层数据结构
- List:
- ArrayList:数组
- LinkedList:双向链表
- Set:
- HashSet:底层基于HashMap实现,HashSet存入读取元素的方式和HashMap中的key是一致的
- TreeSet:红黑树
- Map:
- HashMap:JDK1.8之前HashMap由数组+链表组成的,JDK1.8之后有数组+链表/红黑树组成,当链表长度大于8且数组长度(数据总量)超过64,链表转化为红黑树,当长度小于6时,从红黑树转化为链表。
- HashTable:数组+链表
- TreeMap:红黑树
4.线程安全的集合有哪些
- Vector:所有需要保证线程安全的方法都添加了synchornized关键字,锁住整个对象,但由于加锁会导致性能降低到一定程度,在不需要并发访问同一对象时,这样强制性的同步机制就显得多余,所以被抛弃了
- HashTable:和Vector类似,所以也被抛弃了
- Collections:Collections针对了各种集合来声明了一个线程安全的包装类,它在原集合的基础上添加了锁对象,这样就使得集合中的每个方法都能够通过这个锁对象来实现同步。
ListsynArrayList = Collections.synchronizedList(new ArrayList()); SetsynHashSet = Collections.synchronizedSet(new HashSet()); MapsynHashMap = Collections.synchronizedMap(new HashMap());
5.迭代器Iterator
Iterator是Java迭代器最简单的实现,Iterator接口提供遍历任何Collection的接口。
6.Java集合的快速失败机制fail-fast和安全失败机制fail-safe是什么
- 快速失败:Java的快速失败机制是Java集合框架中的一种错误检测机制,当多个线程同时对集合的内容进行修改时可能会抛出ConcurrentModificationException异常;在单线程中使用增强for循环中一边遍历集合一边修改集合的元素也会抛出ConcurrentModificationException异常,可以使用Iterator.remove()方法可以边遍历边移除Collection中的元素。
- 安全失败机制:在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。所以在遍历的过程中对原集合所做的修改并不能被迭代器检测到,所以不会抛出ConcurrentModificaitonException异常。缺点是迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生了修改,迭代器是无法访问到修改后的内容。java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用。
7.Array和ArrayList区别
-
存储类型不同
- Array:只可存储基本数据类型和对象
- ArrayList:只能存储对象
-
大小不同
- Array:被设置为固定大小
- ArrayList:是一个可变数组,大小可自动调整
-
对象所包含的方法不同
- Array:所包含的方法没有ArrayList多
- ArrayList有很多操作方法:addAll、removeAll、iteration等
8.Comparable和Comparator的区别
- 所属包不同
- Comparable接口属于java.lang
- Comparator接口属于java.util
- 排序需求不同
- 很多包装类如Integer、String都实现了Comparable接口,可以直接调用Collections.sort()可直接使用
- Comparator可以定义多种排序规则,在面对自定义排序需求时,选择Comparator
9.Collection和Collections的区别
- Collection是一个集合接口,提供了对集合对象进行基本操作的通用接口方法
- Conllections是一个集合工具类,提供了一系列静态方法,如sort()等
10.遍历List方式
- for循环
- Iterator
- foreach
顺序存储的可以用for循环,链表存储的用Iterator或foreach
11.ArrayList扩容机制
ArrayList初始容量为10,扩容时=旧容量值+旧容量值右移一位;位运算,相当于除以2,位运算效率更高,所以每次扩容都是旧容量值的1.5倍。
12.ArrayList和LinkedList区别
- 底层结构:ArrayList是数组;LinkedList是链表
- 内存占用:ArrayList扩容问题,存在空间浪费;LinkedList插入问题,每个元素都要消耗空间
- 应用场景:ArrayList多查,少增删;LinkedList多增删,少查
13.ArrayList和Vector区别
- 线程安全:ArrayList线程不安全;Vector线程安全
- 性能:Vector使用synchronized进行加锁,性能比ArrayList差
- 扩容:ArrayList旧容量的1.5倍;Vector旧容量的2倍
14.HashSet使用原理
HashSet底层是HashMap,默认构造函数是构造一个初始容量16,负载因子0.75的HashMap。HashSet的值存放于HashMap的key上,HashMap的value统一为present。
15.HashSet如何查重
HashSet特点是存储元素无序且唯一,在将对象存储在HashSet之前,要确保重写hashCode()方法和equals()方法,这样才能比较对象的值是否相等,确保集合中没有储存相同的对象。
在向HashSet添加值时,会先计算对象的hashCode来确定该对象的存储位置,如果该位置没有其他对象,直接将该对象添加到该位置;如果该存储位置有其他对象,调用equals()判断两个对象是否相同,相同则添加失败,不相同则将该对象重新散列到其他位置。
16.HashMap的长度为什么是2的幂次方
因为HashMap是通过key的hash值来确定存储位置的,但是hash的范围是-232到232-1,不可能建立一个这么大的数组来覆盖所有的hash值,所以在计算完hash值后会对数组的长度进行取余操作,如果数组的长度是2的幂次方,(length-1)&hash = hash%length,位运算可替代取余的操作,从而提高性能。
17.HashMap扩容机制
- HashMap初始容量为16,负载因子0.75,阈值为16*0.75
- 当容量大于阈值时,调用resize()进行扩容,每次扩容,都是之前的两倍
- 扩容时判断e.hash&table.length,hash值对数组长度的取余操作,若等于0,位置不变,若等于1,位置变为原位置+旧容量
18.为什么HashMap红黑树的阈值是8,为什么不直接使用红黑树
- 红黑树节点空间是普通链表节点的两倍,但是查找的空间复杂度低,所以节点比较多时,红黑树的优点才能体现。8是数据分析的出来的结果,链表长度到达8的概率极低。
- 当链表长度大于8且数组长度(数据总量)size()超过64,链表转化为红黑树;如果size()没达到,链表长度大于8的话,会直接扩容。
19.HashMap多线程导致死循环问题
由于JDK1.7的HashMap在遇到hash冲突时采用的是头插法,在多线程的情况下会导致死循环问题;JDK1.8已经改成了尾插法,不存在这个问题了,但是JDK1.8的HashMap仍然是不安全的,在多线程情况下仍然会出现线程安全问题。
20.HashMap在JDK1.7和JDK1.8中有哪些不同
| JDK1.7 | JDK1.8 | JDK1.8优势 | |
|---|---|---|---|
| 底层结构 | 数组+链表 | 数组+链表/红黑树 | 链表过长时可转换为红黑树,提高查询效率 |
| hash值计算方式 | 9次扰动=4次位运算+5次异或运算 | 2次扰动=1次位运算+1次异或运算 | 可以均匀地把之前冲突的节点分散到新的桶 |
| 插入数据方式 | 头插法 | 尾插法 | 解决多线程导致的死循环问题 |
| 扩容后存储位置计算方式 | 重新进行hash计算 | 原位置/原位置+旧容量 | 省去了重新计算hash的时间 |
| JDK1.8的两次扰动分别是 key.hashCode()与key.hashCode()右移16位进行异或,这样做的目的是,高16位不变,低16位于高16位进行疑惑操作,进而减少碰撞的发生,高低位都参与到hash的计算。 |
21.ConcurrentHashMap底层实现
JDK1.7
一个ConcurrentHashMap数组包含了一个Segment数组(实现了ReentrantLock),一个Segment数组包含了一个HashEntry数组,HashEntry是一个链表结构,如果要获取HashEntry里的元素,首先要获取Segment锁

JDK1.8
Node数组+链表/红黑树,采用synchronized+CAS来保证线程安全,synchronized只锁链表/红黑树的头节点
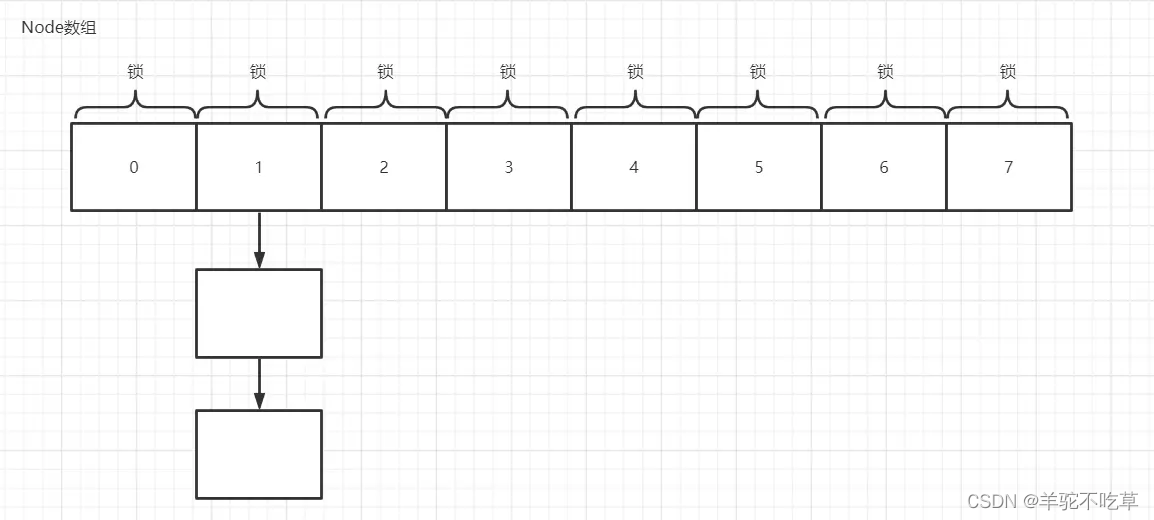
- JDK1.7底层是Segment(实现了ReentrantLock)+HashEntry,JDK1.8是Node数组+链表/红黑树(实现了synchronized+CAS)
- JDK1.7实现的是分段锁,同时锁住几个HashEntry,JDK1.8锁的是链表/红黑树的头节点,只要没有发生hash冲突,就不会产生锁的竞争,粒度更小,提高了ConcurrentHashMap的并发能力
22.HashMap、ConcurrentHashMap、HashTable区别
| HashMap(JDK1.8) | ConcurrentHashMap(JDK1.8) | HashTable | |
|---|---|---|---|
| 底层结构 | 数组+链表/红黑树 | 数组+链表/红黑树 | 数组+链表 |
| 线程安全 | 线程不安全 | 线程安全 | 线程安全 |
| 效率 | 高 | 较高 | 低 |
| 扩容 | 初始16,每次扩容2n | 初始16,每次扩容2n | 初始11,每次扩容2n+1 |
| 是否支持Null key或Null value | 可以有一个Null key,Null value | 不支持 | 不支持 |

















 4345
4345


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








