




 本文详细解释了如何在IT技术中使用数据管道(pipe)、writer和cancel功能,以及ReducerFunc的作用。重点介绍了MapReduceWithSource函数,它是核心方法,处理数据源channel的输入,进行映射和聚合。文章涵盖并发执行、错误处理和数据处理流程控制。
本文详细解释了如何在IT技术中使用数据管道(pipe)、writer和cancel功能,以及ReducerFunc的作用。重点介绍了MapReduceWithSource函数,它是核心方法,处理数据源channel的输入,进行映射和聚合。文章涵盖并发执行、错误处理和数据处理流程控制。
// 数据聚合func
// pipe - 加工出来的数据
// writer - 调用writer.Write()可以将聚合后的数据返回给用户
// cancel - 终止流程func
ReducerFunc func(pipe <-chan interface{}, writer Writer, cancel func(error))
面向用户的方法定义
=========
使用方法可以查看官方文档,这里不做赘述
面向用户的方法比较多,方法主要分为两大类:
-
无返回
-
执行过程发生错误立即终止
-
执行过程不关注错误
-
有返回值
-
手动写入 source,手动读取聚合数据 channel
-
手动写入 source,自动读取聚合数据 channel
-
外部传入 source,自动读取聚合数据 channel
// 并发执行func,发生任何错误将会立即终止流程
func Finish(fns …func() error) error
// 并发执行func,即使发生错误也不会终止流程
func FinishVoid(fns …func())
// 需要用户手动将生产数据写入 source,加工数据后返回一个channel供读取
// opts - 可选参数,目前包含:数据加工阶段协程数量
func Map(generate GenerateFunc, mapper MapFunc, opts …Option)
// 无返回值,不关注错误
func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts …Option)
// 无返回值,关注错误
func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts …Option)
// 需要用户手动将生产数据写入 source ,并返回聚合后的数据
// generate 生产
// mapper 加工
// reducer 聚合
// opts - 可选参数,目前包含:数据加工阶段协程数量
func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts …Option) (interface{}, error)
// 支持传入数据源channel,并返回聚合后的数据
// source - 数据源channel
// mapper - 读取source内容并处理
// reducer - 数据处理完毕发送至reducer聚合
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts …Option) (interface{}, error)
核心方法是 MapReduceWithSource 和 Map,其他方法都在内部调用她俩。弄清楚了 MapReduceWithSource 方法 Map 也不在话下。
MapReduceWithSource 源码实现
========================
一切都在这张图里面了
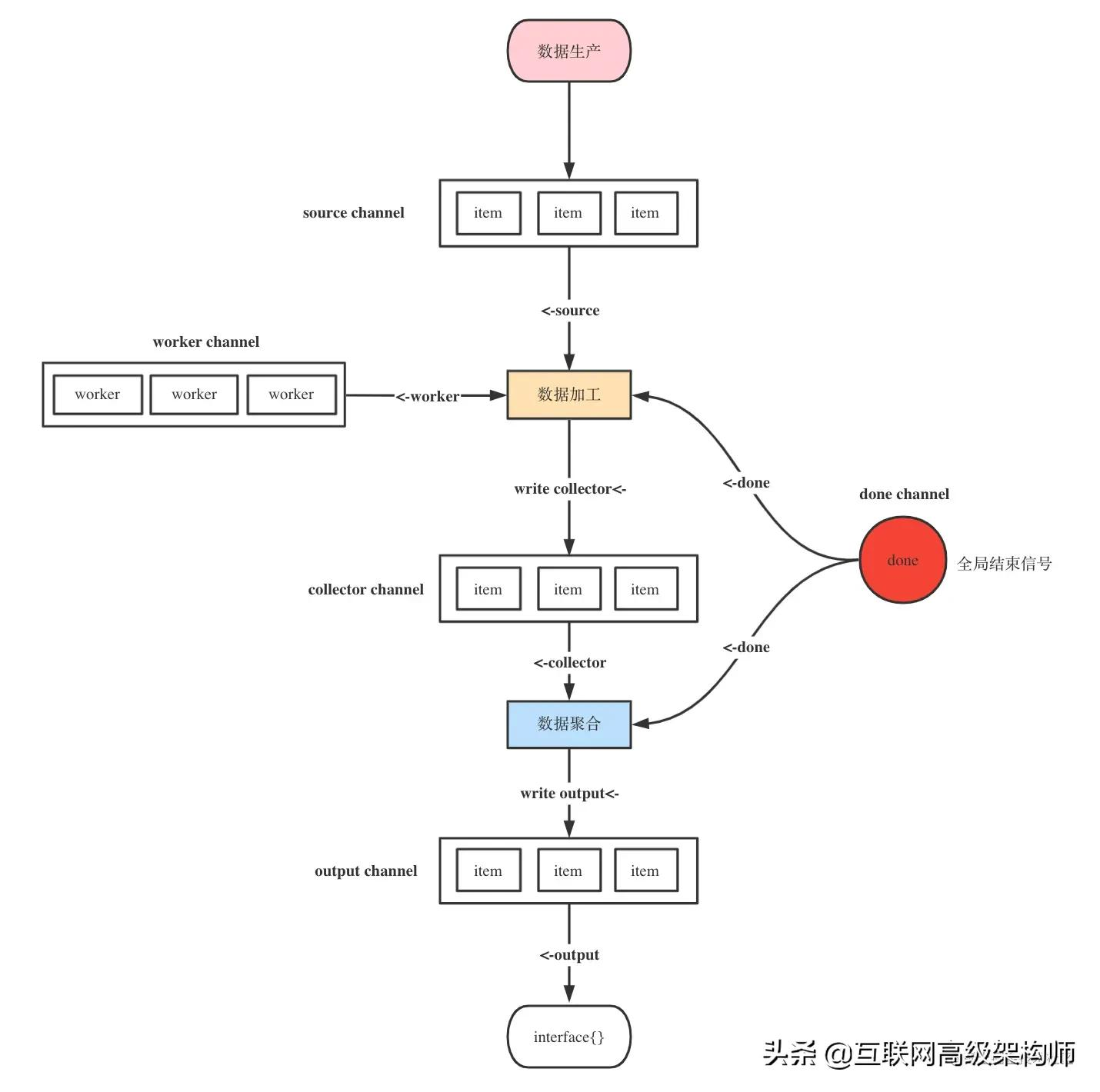
// 支持传入数据源channel,并返回聚合后的数据
// source - 数据源channel
// mapper - 读取source内容并处理
// reducer - 数据处理完毕发送至reducer聚合
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts …Option) (interface{}, error) {
// 可选参数设置
options := buildOptions(opts…)
// 聚合数据channel,需要手动调用write方法写入到output中
output := make(chan interface{})
// output最后只会被读取一次
defer func() {
// 如果有多次写入的话则会造成阻塞从而导致协程泄漏
// 这里用 for range检测是否可以读出数据,读出数据说明多次写入了
// 为什么这里使用panic呢?显示的提醒用户用法错了会比自动修复掉好一些
for range output {
panic(“more than one element written in reducer”)
}
}()
// 创建有缓冲的chan,容量为workers
// 意味着最多允许 workers 个协程同时处理数据
collector := make(chan interface{}, options.workers)
// 数据聚合任务完成标志
done := syncx.NewDoneChan()
// 支持阻塞写入chan的writer
writer := newGuardedWriter(output, done.Done())
// 单例关闭
var closeOnce sync.Once
var retErr errorx.AtomicError
// 数据聚合任务已结束,发送完成标志
finish := func() {
// 只能关闭一次
closeOnce.Do(func() {
// 发送聚合任务完成信号,close函数将会向chan写入一个零值
done.Close()
// 关闭数据聚合chan
close(output)
})
}
// 取消操作
cancel := once(func(err error) {
// 设置error
if err != nil {
retErr.Set(err)
} else {
retErr.Set(ErrCancelWithNil)
}
// 清空source channel
drain(source)
// 调用完成方法
finish()
})
go func() {
defer func() {
// 清空聚合任务channel
drain(collector)
// 捕获panic
if r := recover(); r != nil {
// 调用cancel方法,立即结束
cancel(fmt.Errorf(“%v”, r))
} else {
// 正常结束
finish()
}
}()
// 执行数据加工
// 注意writer.write将加工后数据写入了output
reducer(collector, writer, cancel)
}()
// 异步执行数据加工
// source - 数据生产
// collector - 数据收集
// done - 结束标志
// workers - 并发数
go executeMappers(func(item interface{}, w Writer) {
mapper(item, w, cancel)
}, source, collector, done.Done(), options.workers)
// reducer将加工后的数据写入了output,
// 需要数据返回时读取output即可
// 假如output被写入了超过两次
// 则开始的defer func那里将还可以读到数据
// 由此可以检测到用户调用了多次write方法
value, ok := <-output
if err := retErr.Load(); err != nil {
return nil, err
} else if ok {
return value, nil
} else {
return nil, ErrReduceNoOutput
}
}
// 数据加工
func executeMappers(mapper MapFunc, input <-chan interface{}, collector chan<- interface{},
done <-chan lang.PlaceholderType, workers int) {
// goroutine协调同步信号量
var wg sync.WaitGroup
defer func() {
// 等待数据加工任务完成
// 防止数据加工的协程还未处理完数据就直接退出了
wg.Wait()
// 关闭数据加工channel
close(collector)
}()
// 带缓冲区的channel,缓冲区大小为workers
// 控制数据加工的协程数量
pool := make(chan lang.PlaceholderType, workers)
// 数据加工writer
writer := newGuardedWriter(collector, done)
for {
select {
// 监听到外部结束信号,直接结束
case <-done:
return
// 控制数据加工协程数量
// 缓冲区容量-1
// 无容量时将会被阻塞,等待释放容量
case pool <- lang.Placeholder:
// 阻塞等待生产数据channel
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

独家面经总结,超级精彩
本人面试腾讯,阿里,百度等企业总结下来的面试经历,都是真实的,分享给大家!

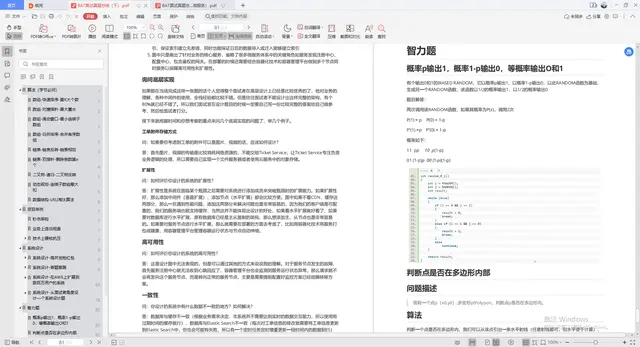
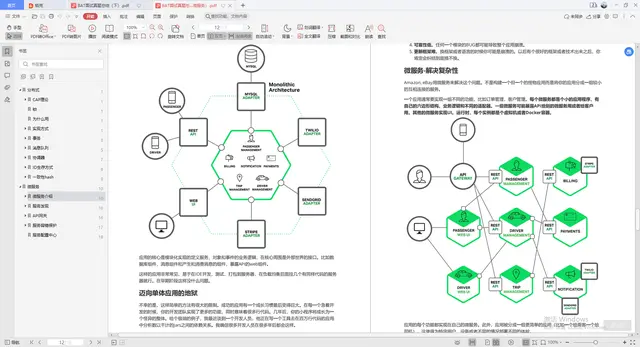
Java面试准备
准确的说这里又分为两部分:
- Java刷题
- 算法刷题
Java刷题:此份文档详细记录了千道面试题与详解;
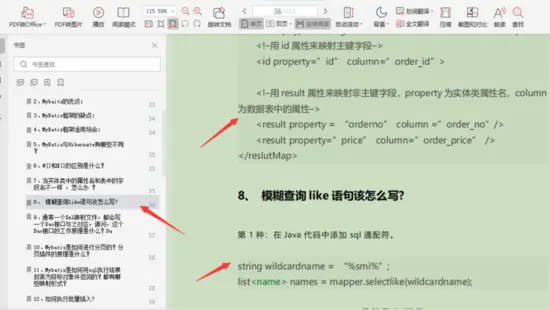
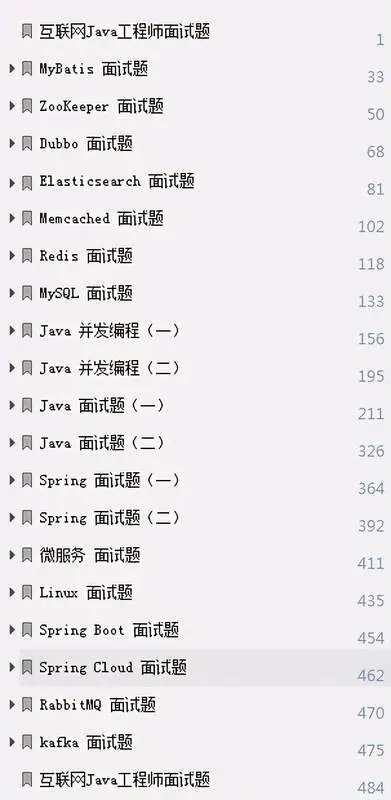
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
074731)]
[外链图片转存中…(img-i4h0FIUX-1712475074731)]
[外链图片转存中…(img-aNa6iWWK-1712475074731)]
[外链图片转存中…(img-4UG7V5ub-1712475074731)]
Java面试准备
准确的说这里又分为两部分:
- Java刷题
- 算法刷题
Java刷题:此份文档详细记录了千道面试题与详解;
[外链图片转存中…(img-DvVT0OPM-1712475074732)]
[外链图片转存中…(img-J7su4T3D-1712475074732)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









