




 本文围绕Redis展开,介绍了主从、哨兵和集群三种模式。主从模式实现读写分离,一定程度上提高可用性和性能,但存在数据一致性问题;哨兵模式是主从升级版,可自动故障恢复;集群模式实现数据分布式存储,解决扩容等问题。还给出了各模式的实操搭建和测试方法。
本文围绕Redis展开,介绍了主从、哨兵和集群三种模式。主从模式实现读写分离,一定程度上提高可用性和性能,但存在数据一致性问题;哨兵模式是主从升级版,可自动故障恢复;集群模式实现数据分布式存储,解决扩容等问题。还给出了各模式的实操搭建和测试方法。
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
当一个子进程重写AOF文件时,文件每生成32M数据会被同步
aof-rewrite-incremental-fsync yes
由于,单机版的Redis在并发量比较大的时候,并且需要较高性能和可靠性的时候,单机版基本就不适合了,于是就出现了**「主从模式」**。
主从模式
原理
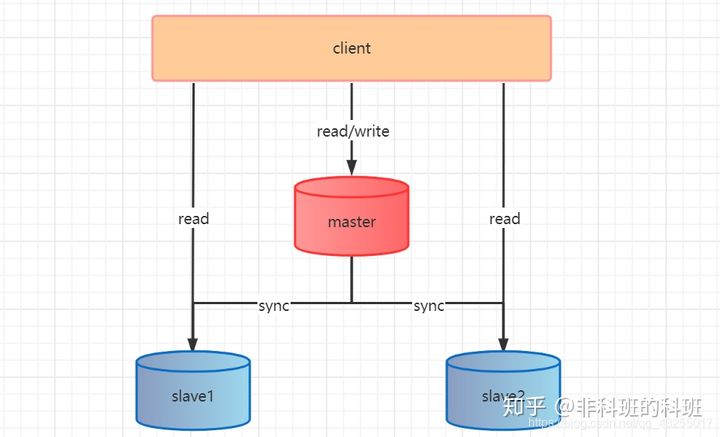
主从的原理还算是比较简单的,一主多从,「主数据库(master)可以读也可以写(read/write),从数据库仅读(only read)」。
但是,主从模式一般实现**「读写分离」,「主数据库仅写(only write)」**,减轻主数据库的压力,下面一张图搞懂主从模式的原理:
主从模式原理就是那么简单,那他执行的过程(工作机制)又是怎么样的呢?再来一张图:

当开启主从模式的时候,他的具体工作机制如下:
-
当slave启动后会向master发送
SYNC命令,master节后到从数据库的命令后通过bgsave保存快照(「RDB持久化」),并且期间的执行的些命令会被缓存起来。 -
然后master会将保存的快照发送给slave,并且继续缓存期间的写命令。
-
slave收到主数据库发送过来的快照就会加载到自己的数据库中。
-
最后master讲缓存的命令同步给slave,slave收到命令后执行一遍,这样master与slave数据就保持一致了。
优点
之所以运用主从,是因为主从一定程度上解决了单机版并发量大,导致请求延迟或者redis宕机服务停止的问题。
从数据库分担主数据库的读压力,若是主数据库是只写模式,那么实现读写分离,主数据库就没有了读压力了。
另一方面解决了单机版单点故障的问题,若是主数据库挂了,那么从数据库可以随时顶上来,综上来说,主从模式一定程度上提高了系统的可用性和性能,是实现哨兵和集群的基础。
主从同步以异步方式进行同步,期间Redis仍然可以响应客户端提交的查询和更新的请求。
缺点
主从模式好是好,他也有自己的缺点,比如数据的一致性问题,假如主数据库写操作完成,那么他的数据会被复制到从数据库,若是还没有即使复制到从数据库,读请求又来了,此时读取的数据就不是最新的数据。
若是从主同步的过程网络出故障了,导致主从同步失败,也会出现问题数据一致性的问题。
主从模式不具备自动容错和恢复的功能,一旦主数据库,从节点晋升未主数据库的过程需要人为操作,维护的成本就会升高,并且主节点的写能力、存储能力都会受到限制。
实操搭建
下面的我们来实操搭建一下主从模式,主从模式的搭建还是比较简单的,我这里一台centos 7虚拟机,使用开启redis多实例的方法搭建主从。
redis中开启多实例的方法,首先创建一个文件夹,用于存放redis集群的配置文件:
mkdir redis
然后粘贴复制redis.conf配置文件:
cp /root/redis-4.0.6/redis.conf /root/redis/redis-6379.conf
cp /root/redis-4.0.6/redis.conf /root/redis/redis-6380.conf
cp /root/redis-4.0.6/redis.conf /root/redis/redis-6381.conf
复制三份配置文件,一主两从,6379端口作为主数据库(master),6380、6381作为从数据库(slave)。
首先是配置主数据库的配置文件:vi redis-6379.conf:
bind 0.0.0.0 # 注释掉或配置成0.0.0.0表示任意IP均可访问。
protected-mode no # 关闭保护模式,使用密码访问。
port 6379 # 设置端口,6380、6381依次为6380、6381。
timeout 30 # 客户端连接空闲多久后断开连接,单位秒,0表示禁用
daemonize yes # 在后台运行
pidfile /var/run/redis_6379.pid # pid进程文件名,6380、6381依次为redis_6380.pid、redis_6381.pid
logfile /root/reids/log/6379.log # 日志文件,6380、6381依次为6380.log、6381.log
save 900 1 # 900s内至少一次写操作则执行bgsave进行RDB持久化
save 300 10
save 60 10000
rdbcompression yes #是否对RDB文件进行压缩,建议设置为no,以(磁盘)空间换(CPU)时间
dbfilename dump.rdb # RDB文件名称
dir /root/redis/datas # RDB文件保存路径,AOF文件也保存在这里
appendonly yes # 表示使用AOF增量持久化的方式
appendfsync everysec # 可选值 always, everysec,no,建议设置为everysec
requirepass 123456 # 设置密码
然后,就是修改从数据库的配置文件,在从数据库的配置文件中假如以下的配置信息:
slaveof 127.0.0.1 6379 # 配置master的ip,port
masterauth 123456 # 配置访问master的密码
slaveof-serve-stale-data no
接下来就是启动三个redis实例,启动的命令,先cd到redis的src目录下,然后执行:
./redis-server /root/redis/6379.conf
./redis-server /root/redis/6380.conf
./redis-server /root/redis/6381.conf
通过命令ps -aux | grep redis,查看启动的redis进程:

如上图所示,表示启动成功,下面就开始进入测试阶段。
测试
我这里使用SecureCRT作为redis连接的客户端,同时启动三个SecureCRT,分别连接redis1的三个实例,启动时指定端口以及密码:
./redis-cli -p 6379 -a 123456
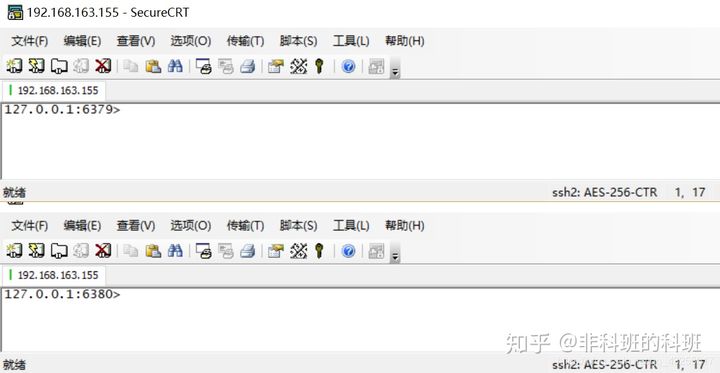
启动后,在master(6379),输入:set name ‘ldc’,在slave中通过get name,可以查看:
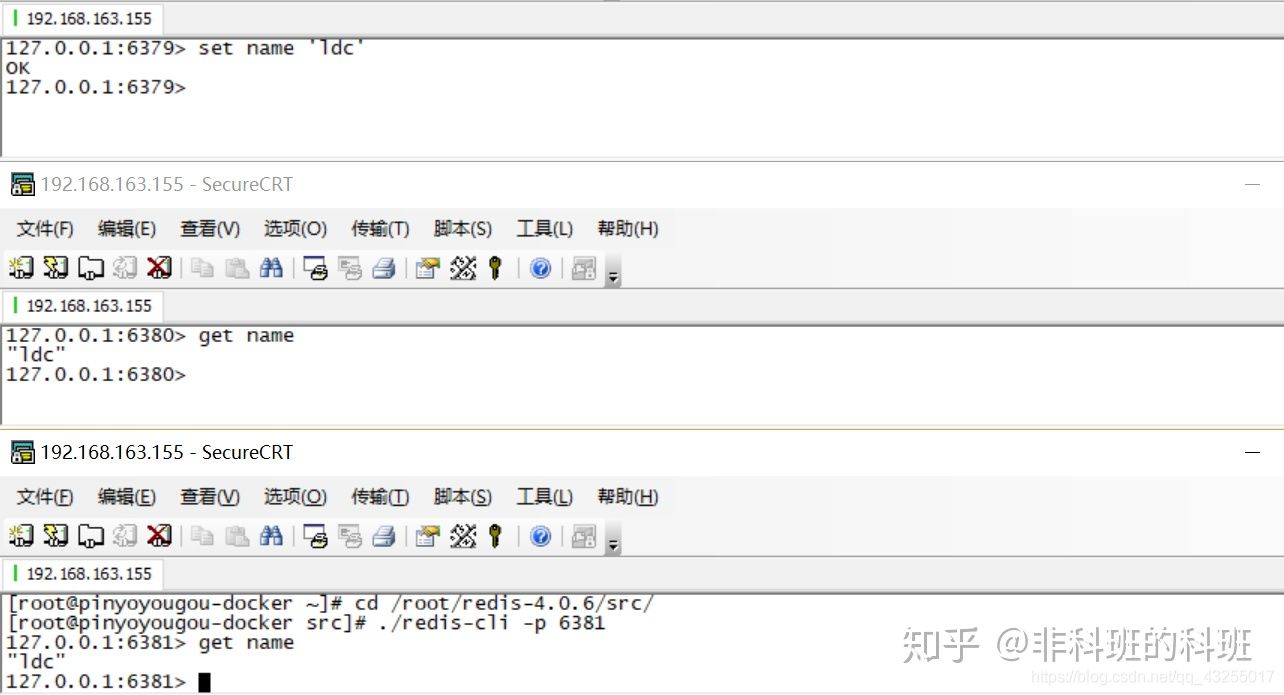
数据同步成功,这有几个坑一个是redis.conf中没有设置对bind,会导致非本机的ip被过滤掉,一般配置0.0.0.0就可以了。
另一个是没有配置密码requirepass 123456,会导致IO一直连接异常,这个是我遇到的坑,后面配置密码后就成功了。
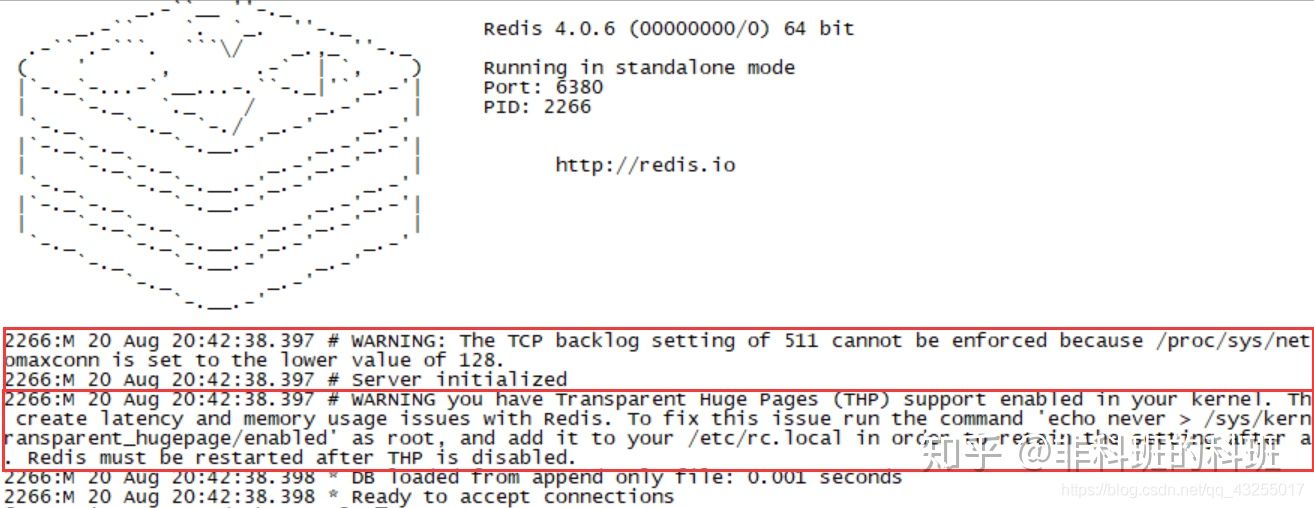
还有,就是查看redis的启动日志可以发现有两个warning,虽然不影响搭建主从同步,看着挺烦人的,但是有些人会遇到,有些人不会遇到。
但是,我这个人比较有强迫症,百度也是有解决方案的,这里就不讲了,交给你们自己解决,这里只是告诉你有这个问题,有些人看都不看日志的,看到启动成功就认为万事大吉了,也不看日志,这习惯并不好。
哨兵模式
原理
哨兵模式是主从的升级版,因为主从的出现故障后,不会自动恢复,需要人为干预,这就很蛋疼啊。
在主从的基础上,实现哨兵模式就是为了监控主从的运行状况,对主从的健壮进行监控,就好像哨兵一样,只要有异常就发出警告,对异常状况进行处理。
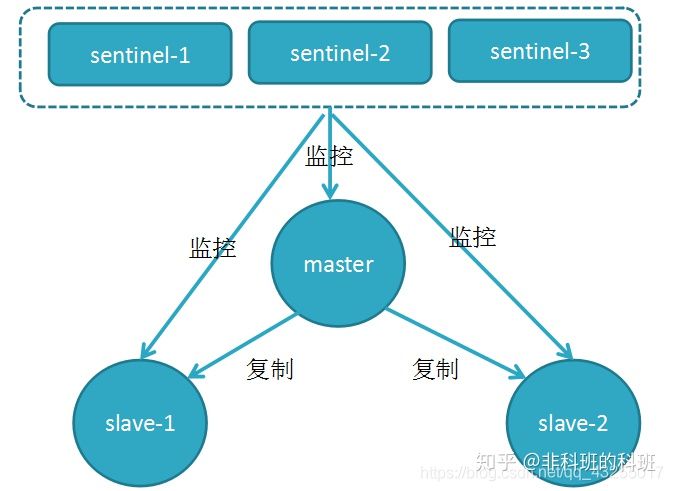
所以,总的概括来说,哨兵模式有以下的优点(功能点):
-
「监控」:监控master和slave是否正常运行,以及哨兵之间也会相互监控
-
「自动故障恢复」:当master出现故障的时候,会自动选举一个slave作为master顶上去。
哨兵模式的监控配置信息,是通过配置从数据库的sentinel monitor <master-name> <ip> <redis-port> <quorum> 来指定的,比如:
// mymaster 表示给master数据库定义了一个名字,后面的是master的ip和端口,1表示至少需要一个Sentinel进程同意才能将master判断为失效,如果不满足这个条件,则自动故障转移(failover)不会执行
sentinel monitor mymaster 127.0.0.1 6379 1
节点通信
当然还有其它的配置信息,其它配置信息,在环境搭建的时候再说。当哨兵启动后,会与master建立一条连接,用于订阅master的_sentinel_:hello频道。
该频道用于获取监控该master的其它哨兵的信息。并且还会建立一条定时向master发送INFO命令获取master信息的连接。
「当哨兵与master建立连接后,定期会向(10秒一次)master和slave发送INFO命令,若是master被标记为主观下线,频率就会变为1秒一次。」
并且,定期向_sentinel_:hello频道发送自己的信息,以便其它的哨兵能够订阅获取自己的信息,发送的内容包含**「哨兵的ip和端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本」**等信息。
以及,「定期的向master、slave和其它哨兵发送PING命令(每秒一次),以便检测对象是否存活」,若是对方接收到了PING命令,无故障情况下,会回复PONG命令。
所以,哨兵通过建立这两条连接、通过定期发送INFO、PING命令来实现哨兵与哨兵、哨兵与master之间的通信。
这里涉及到一些概念需要理解,INFO、PING、PONG等命令,后面还会有MEET、FAIL命令,以及主观下线,当然还会有客观下线,这里主要说一下这几个概念的理解:
-
INFO:该命令可以获取主从数据库的最新信息,可以实现新结点的发现
-
PING:该命令被使用最频繁,该命令封装了自身节点和其它节点的状态数据。
-
PONG:当节点收到MEET和PING,会回复PONG命令,也把自己的状态发送给对方。
-
MEET:该命令在新结点加入集群的时候,会向老节点发送该命令,表示自己是个新人
-
FAIL:当节点下线,会向集群中广播该消息。
上线和下线
当哨兵与master相同之后就会定期一直保持联系,若是某一时刻哨兵发送的PING在指定时间内没有收到回复(sentinel down-after-milliseconds master-name milliseconds 配置),那么发送PING命令的哨兵就会认为该master**「主观下线」**(Subjectively Down)。
因为有可能是哨兵与该master之间的网络问题造成的,而不是master本身的原因,所以哨兵同时会询问其它的哨兵是否也认为该master下线,若是认为该节点下线的哨兵达到一定的数量(「前面的quorum字段配置」),就会认为该节点**「客观下线」**(Objectively Down)。
若是没有足够数量的sentinel同意该master下线,则该master客观下线的标识会被移除;若是master重新向哨兵的PING命令回复了客观下线的标识也会被移除。
选举算法
当master被认为客观下线后,又是怎么进行故障恢复的呢?原来哨兵中首先选举出一个老大哨兵来进行故障恢复,选举老大哨兵的算法叫做**「Raft算法」**:
-
发现master下线的哨兵(sentinelA)会向其它的哨兵发送命令进行拉票,要求选择自己为哨兵大佬。
-
若是目标哨兵没有选择其它的哨兵,就会选择该哨兵(sentinelA)为大佬。
-
若是选择sentinelA的哨兵超过半数(半数原则),该大佬非sentinelA莫属。
-
如果有多个哨兵同时竞选,并且可能存在票数一致的情况,就会等待下次的一个随机时间再次发起竞选请求,进行新的一轮投票,直到大佬被选出来。
选出大佬哨兵后,大佬哨兵就会对故障进行自动回复,从slave中选出一名slave作为主数据库,选举的规则如下所示:
-
所有的slave中
slave-priority优先级最高的会被选中。 -
若是优先级相同,会选择偏移量最大的,因为偏移量记录着数据的复制的增量,越大表示数据越完整。
-
若是以上两者都相同,选择ID最小的。
通过以上的层层筛选最终实现故障恢复,当选的slave晋升为master,其它的slave会向新的master复制数据,若是down掉的master重新上线,会被当作slave角色运行。
优点
哨兵模式是主从模式的升级版,所以在系统层面提高了系统的可用性和性能、稳定性。当master宕机的时候,能够自动进行故障恢复,需不要人为的干预。
哨兵于哨兵之间、哨兵与master之间能够进行及时的监控,心跳检测,及时发现系统的问题,这都是弥补了主从的缺点。
缺点
哨兵一主多从的模式同样也会遇到写的瓶颈,已经存储瓶颈,若是master宕机了,故障恢复的时间比较长,写的业务就会受到影响。
增加了哨兵也增加了系统的复杂度,需要同时维护哨兵模式。
实操搭建
最后,我们进行一下哨兵模式的搭建,配置哨兵模式还是比较简单的,在上面配置的主从模式的基础上,同时创建一个文件夹用于存放三个哨兵的配置文件:
mkdir /root/redis-4.0.6/sentinel.conf /root/redis/sentinel/sentinel1.conf
mkdir /root/redis-4.0.6/sentinel.conf /root/redis/sentinel/sentinel2.conf
mkdir /root/redis-4.0.6/sentinel.conf /root/redis/sentinel/sentinel3.conf
分别在这三个文件中添加如下配置:
daemonize yes # 在后台运行
sentinel monitor mymaster 127.0.0.1 6379 1 # 给master起一个名字mymaster,并且配置master的ip和端口
sentinel auth-pass mymaster 123456 # master的密码
port 26379 #另外两个配置36379,46379端口
sentinel down-after-milliseconds mymaster 3000 # 3s未回复PING就认为master主观下线
sentinel parallel-syncs mymaster 2 # 执行故障转移时,最多可以有2个slave实例在同步新的master实例
sentinel failover-timeout mymaster 100000 # 如果在10s内未能完成故障转移操作认为故障转移失败
配置完后分别启动三台哨兵:
./redis-server sentinel1.conf --sentinel
./redis-server sentinel2.conf --sentinel
./redis-server sentinel3.conf --sentinel
然后通过:ps -aux|grep redis进行查看:

可以看到三台redis实例以及三个哨兵都已经正常启动,现登陆6379,通过INFO Repliaction查看master信息:
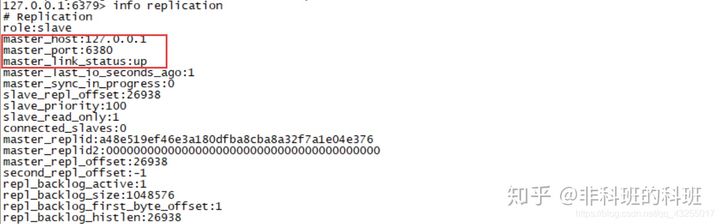
当前master为6379,然后我们来测试一下哨兵的自动故障恢复,直接kill掉6379进程,然后通过登陆6380再次查看master的信息:
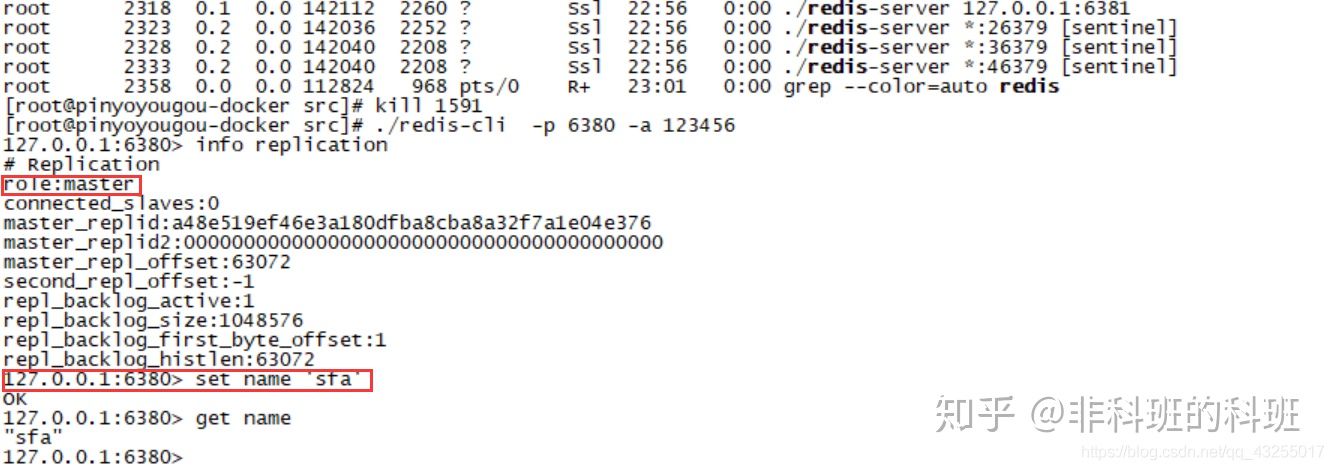
可以看到当前的6380角色是master,并且6380可读可写,而不是只读模式,这说明我们的哨兵是起作用了,搭建成功,感兴趣的可以自行搭建,也有可能你会踩一堆的坑。
Cluster模式
最后,Cluster是真正的集群模式了,哨兵解决和主从不能自动故障恢复的问题,但是同时也存在难以扩容以及单机存储、读写能力受限的问题,并且集群之前都是一台redis都是全量的数据,这样所有的redis都冗余一份,就会大大消耗内存空间。
集群模式实现了Redis数据的分布式存储,实现数据的分片,每个redis节点存储不同的内容,并且解决了在线的节点收缩(下线)和扩容(上线)问题。
集群模式真正意义上实现了系统的高可用和高性能,但是集群同时进一步使系统变得越来越复杂,接下来我们来详细的了解集群的运作原理。
数据分区原理
集群的原理图还是很好理解的,在Redis集群中采用的使虚拟槽分区算法,会把redis集群分成16384 个槽(0 -16383)。
比如:下图所示三个master,会把0 -16383范围的槽可能分成三部分(0-5000)、(5001-11000)、(11001-16383)分别数据三个缓存节点的槽范围。
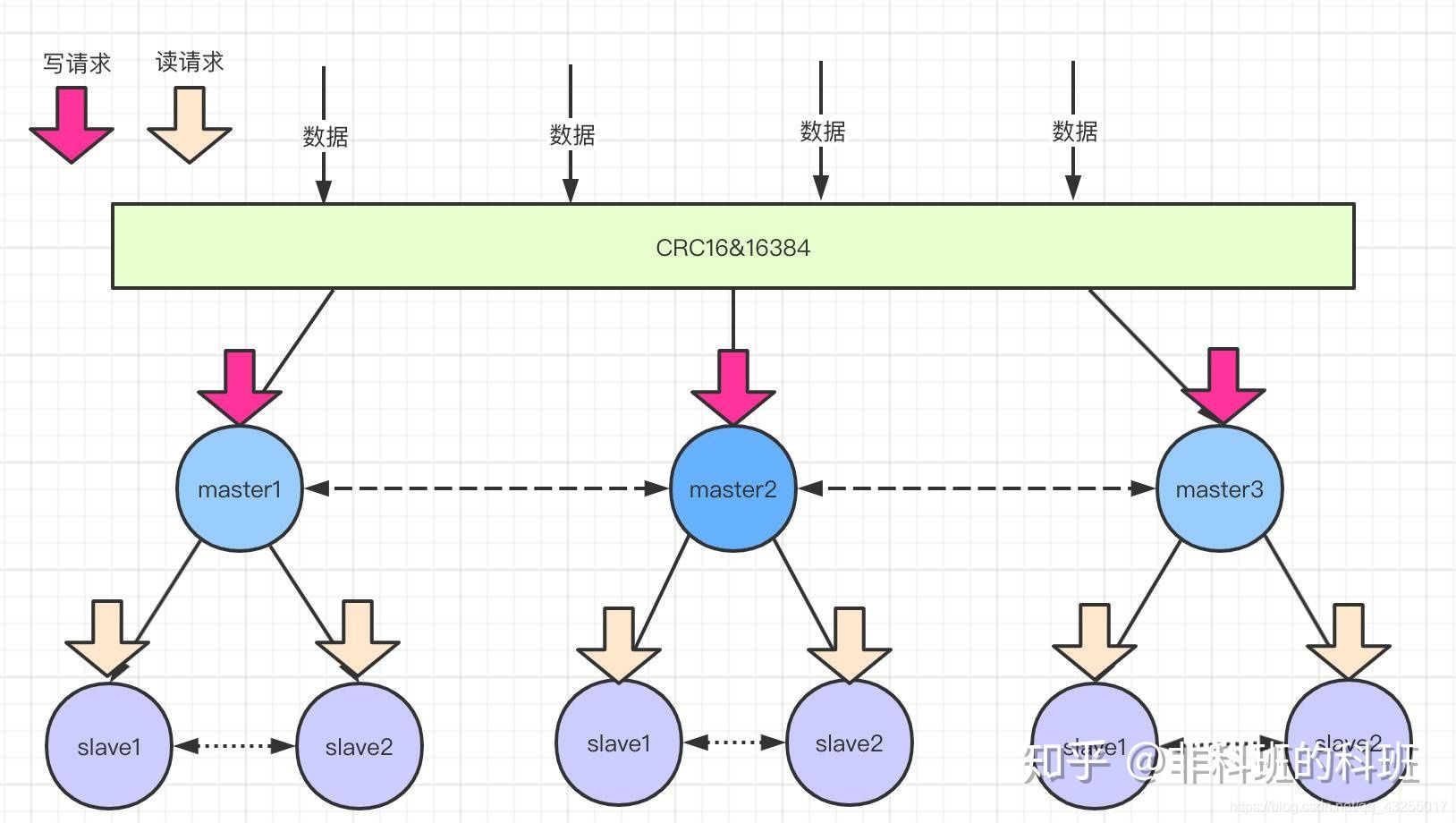
当客户端请求过来,会首先通过对key进行CRC16 校验并对 16384 取模(CRC16(key)%16383)计算出key所在的槽,然后再到对应的槽上进行取数据或者存数据,这样就实现了数据的访问更新。
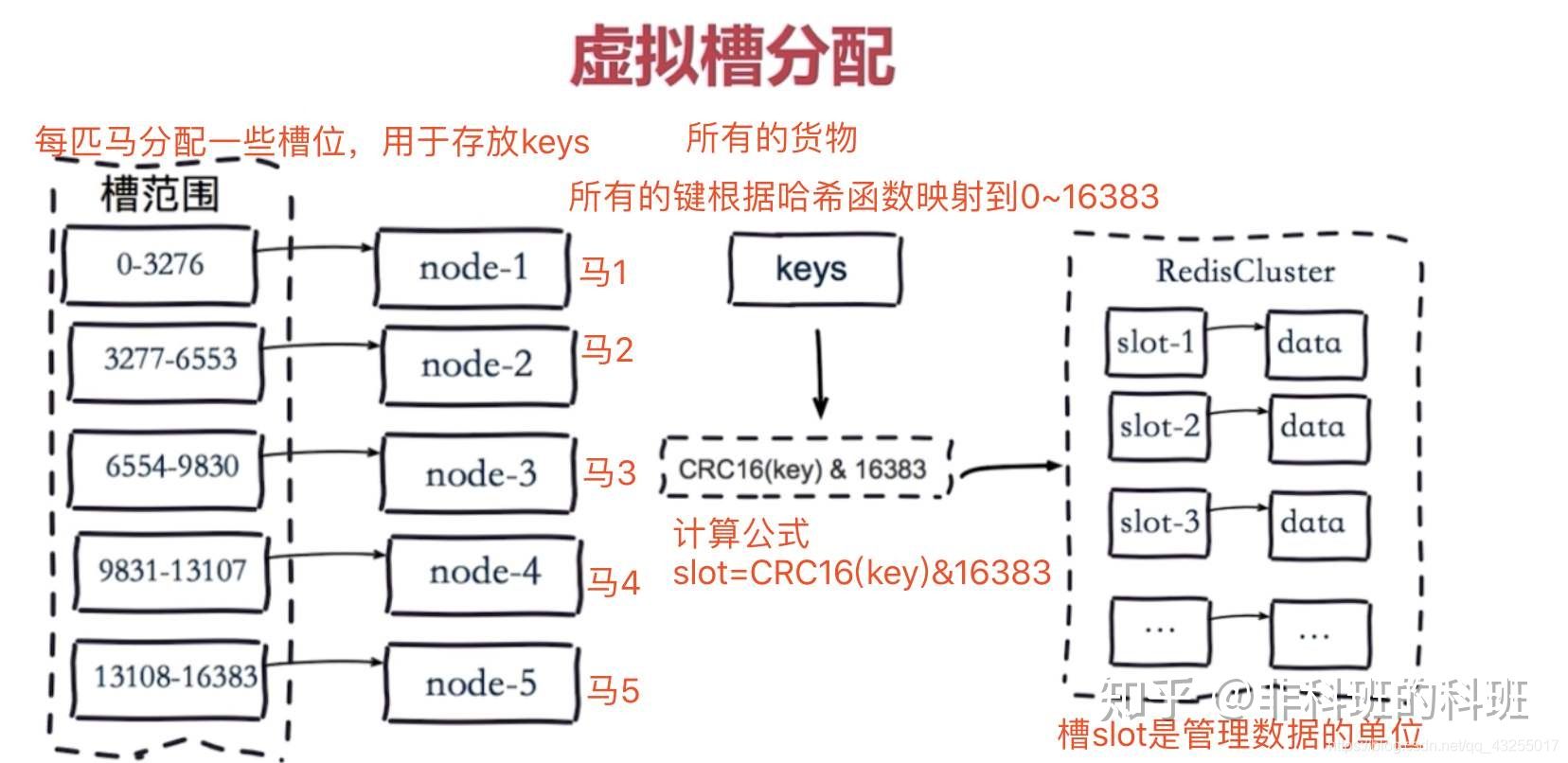
之所以进行分槽存储,是将一整堆的数据进行分片,防止单台的redis数据量过大,影响性能的问题。
节点通信
节点之间实现了将数据进行分片存储,那么节点之间又是怎么通信的呢?这个和前面哨兵模式讲的命令基本一样。
首先新上线的节点,会通过 Gossip 协议向老成员发送Meet消息,表示自己是新加入的成员。
老成员收到Meet消息后,在没有故障的情况下会恢复PONG消息,表示欢迎新结点的加入,除了第一次发送Meet消息后,之后都会发送定期PING消息,实现节点之间的通信。
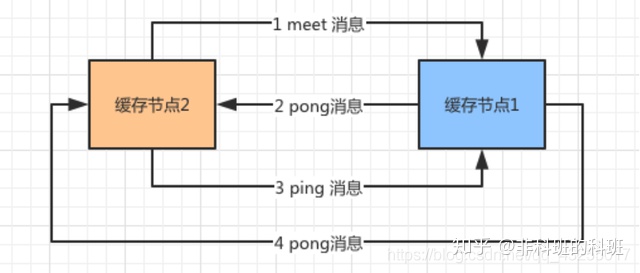
通信的过程中会为每一个通信的节点开通一条tcp通道,之后就是定时任务,不断的向其它节点发送PING消息,这样做的目的就是为了了解节点之间的元数据存储情况,以及健康状况,以便即使发现问题。
数据请求
上面说到了槽信息,在Redis的底层维护了unsigned char myslots[CLUSTER_SLOTS/8] 一个数组存放每个节点的槽信息。
因为他是一个二进制数组,只有存储0和1值,如下图所示:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
小编在这里分享些我自己平时的学习资料,由于篇幅限制,pdf文档的详解资料太全面,细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
程序员代码面试指南 IT名企算法与数据结构题目最优解
这是” 本程序员面试宝典!书中对IT名企代码面试各类题目的最优解进行了总结,并提供了相关代码实现。针对当前程序员面试缺乏权威题目汇总这一-痛点, 本书选取将近200道真实出现过的经典代码面试题,帮助广“大程序员的面试准备做到万无一失。 “刷”完本书后,你就是“题王”!
《TCP-IP协议组(第4版)》
本书是介绍TCP/IP协议族的经典图书的最新版本。本书自第1版出版以来,就广受读者欢迎。
本书最新版进行」护元,以体境计算机网络技不的最新发展,全书古有七大部分共30草和7个附录:第一部分介绍一些基本概念和基础底层技术:第二部分介绍网络层协议:第三部分介绍运输层协议;第四部分介绍应用层协议:第五部分介绍下一代协议,即IPv6协议:第六部分介绍网络安全问题:第七部分给出了7个附录。
Java开发手册(嵩山版)
这个不用多说了,阿里的开发手册,每次更新我都会看,这是8月初最新更新的**(嵩山版)**
MySQL 8从入门到精通
本书主要内容包括MySQL的安装与配置、数据库的创建、数据表的创建、数据类型和运算符、MySQL 函数、查询数据、数据表的操作(插入、更新与删除数据)、索引、存储过程和函数、视图、触发器、用户管理、数据备份与还原、MySQL 日志、性能优化、MySQL Repl ication、MySQL Workbench、 MySQL Utilities、 MySQL Proxy、PHP操作MySQL数据库和PDO数据库抽象类库等。最后通过3个综合案例的数据库设计,进步讲述 MySQL在实际工作中的应用。
Spring5高级编程(第5版)
本书涵盖Spring 5的所有内容,如果想要充分利用这一领先的企业级 Java应用程序开发框架的强大功能,本书是最全面的Spring参考和实用指南。
本书第5版涵盖核心的Spring及其与其他领先的Java技术(比如Hibemate JPA 2.Tls、Thymeleaf和WebSocket)的集成。本书的重点是介绍如何使用Java配置类、lambda 表达式、Spring Boot以及反应式编程。同时,将与企业级应用程序开发人员分享一些见解和实际经验,包括远程处理、事务、Web 和表示层,等等。
JAVA核心知识点+1000道 互联网Java工程师面试题
企业IT架构转型之道 阿里巴巴中台战略思想与架构实战
本书讲述了阿里巴巴的技术发展史,同时也是-部互联网技 术架构的实践与发展史。
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
Spring5高级编程(第5版)
本书涵盖Spring 5的所有内容,如果想要充分利用这一领先的企业级 Java应用程序开发框架的强大功能,本书是最全面的Spring参考和实用指南。
本书第5版涵盖核心的Spring及其与其他领先的Java技术(比如Hibemate JPA 2.Tls、Thymeleaf和WebSocket)的集成。本书的重点是介绍如何使用Java配置类、lambda 表达式、Spring Boot以及反应式编程。同时,将与企业级应用程序开发人员分享一些见解和实际经验,包括远程处理、事务、Web 和表示层,等等。
[外链图片转存中…(img-kGBAyRcS-1712265675272)]
JAVA核心知识点+1000道 互联网Java工程师面试题
[外链图片转存中…(img-q7LcHzp1-1712265675272)]
[外链图片转存中…(img-X7zGJnoy-1712265675272)]
企业IT架构转型之道 阿里巴巴中台战略思想与架构实战
本书讲述了阿里巴巴的技术发展史,同时也是-部互联网技 术架构的实践与发展史。
[外链图片转存中…(img-LPhFdWag-1712265675273)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!

















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









