




TensorBoard介绍
TensorBoard是TensorFlow的可视化工具,它可以通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态。TensorFlow和TensorBoard程序跑在不同的进程中,TensorBoard会自动读取最新的TensorFlow日志文件,并呈现当前程序运行的最新状态。
代码运行
(1)在Windows或者Linux下TensorFlow框架下,本人所用为win10下的Spyder。
(2)首先创建一个可视化.py文件,它会默认保存到程序的工作空间中,其中
writer = tf.summary.FileWriter("logs/",sess.graph)#加载到文件里,再从文件里加载出来观看测试代码如下:
import tensorflow as tf
def add_layer(input,in_size,out_size,activation_function=None):
#add one more layer and return the output of this layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1,name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(input,Weights),biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b,)
return outputs
#define placeholder for inputs to network
with tf.name_scope('input'):
xs = tf.placeholder(tf.float32,[None,1],name='x_input')
ys = tf.placeholder(tf.float32,[None,1],name='y_input')
#add hidder layer
l1 = add_layer(xs,1,10,activation_function=tf.nn.relu)
#add output layer
prediction = add_layer(l1,10,1,activation_function=None)
#the error between prediction and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
writer = tf.summary.FileWriter("logs/",sess.graph)#加载到文件里,再从文件里加载出来观看
#important step
sess.run(tf.initialize_all_variables())(3)运行完毕后会生成在log下生成文件,打开终端,切换到文件目录下:
activate tensorflow
cd 你的路径
tensorboard --logdir=logs此处出现了一个小的插曲。运行后出现
OSError:[Errno 22] Invalid argument此处查阅资料后,博主https://blog.youkuaiyun.com/u013244846/article/details/88380860,给出了解决方案。但是本人所用工具为Spyder,不过解决方法大致相同。
在tensorflow环境下查找...\Lib\site-packages\tensorboard路径下的manager.py 打开修改_type_timestamp的定义下的serialize,
serialize=lambda dt: int(dt.strftime("%S"))
最终运行后会出现如下结果:
(tensorflow) I:\TensorflowWS>tensorboard --logdir=logs
TensorBoard 1.13.1 at http://DESKTOP-RR115KR:6006 (Press CTRL+C to quit)(4)打开浏览器,将网址复制到地址栏。
然而此处遇到了问题
在几经周折以后,在博主https://blog.youkuaiyun.com/dr_theodore/article/details/80748068出找到了解决方法。即在末尾加一句--host=127.0.0.1
(tensorflow) I:\TensorflowWS>tensorboard --logdir=logs --host=127.0.0.1
TensorBoard 1.13.1 at http://127.0.0.1:6006 (Press CTRL+C to quit)完成后,如图: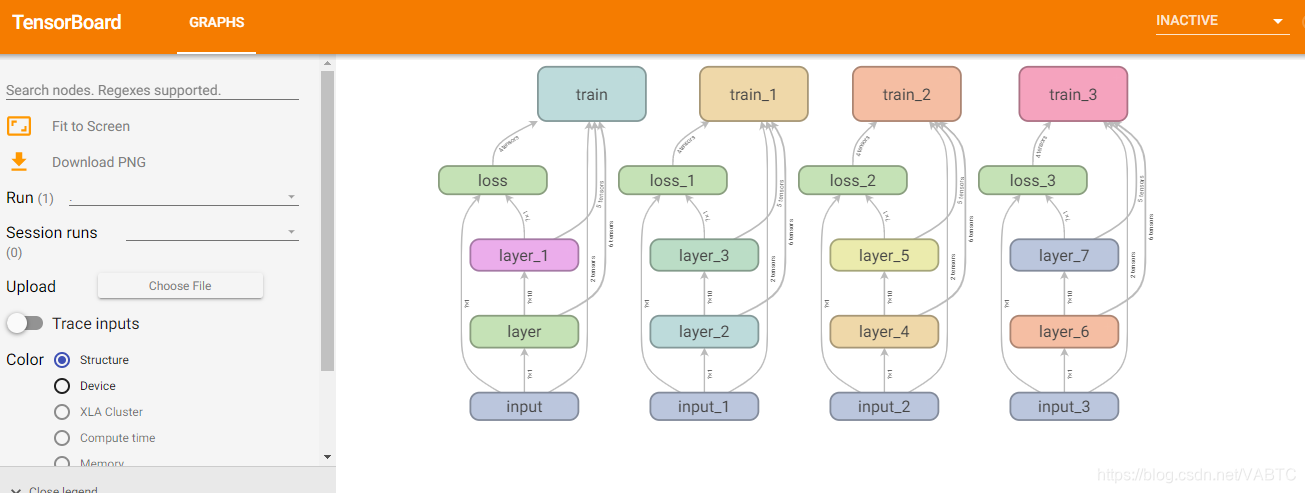
另附一条Tensorboard学习总结Tensorboard各显示块的作用


















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









