






有这么一个表,其中一列放的是一串数字,我们要求出相邻两项的差值。
例如:
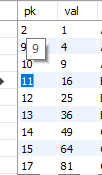
注意到主键不是等差数列。
首先想到的方法是利用上文提到的生成行号的方法,得到下面的SQL 语句
select t2.val - t1.val from
(select (@rowNum1:=@rowNum1+1) row_num ,v1.* from Test_table01 v1 ,(Select (@rowNum1 :=0) ) r1 ) t1,
(select (@rowNum2:=@rowNum2+1) row_num ,v2.* from Test_table01 v2 ,(Select (@rowNum2 :=0) ) r2 ) t2
where t2.row_num - t1.row_num =1
结果如下:

可见结果是正确的。
但是一旦引入稍微复杂的条件,结果就有点儿意外了,这个原因是行号的值是和子查询的结果相关的,如果两个子查询生成的结果集不一致,那么这个比较就极有可能不是相邻项的比较。换言之,要保证子查询的查询条件一致,不要想当然。如果查询结果确实需要对两个子查询使用不同的条件,可以采用再嵌套一层sql的方法,在外层使用附加的条件。
按:上述语句中的两个子查询的表面条件是一样的,但是估计mysql 采用了sql优化方案,当你在子查询之外使用有关条件时,会对子查询的结果集有影响。(待考证)
不采用上面的方法也可以利用主键递增的特性,实现相邻项的比较和计算。核心是如何查找相邻项。
方法是:
计算主键的差,找到最小值。示意代码如下:
select distinct t2.val from yourTab t1, yourTab t2
where t2.pk-t1.pk <= 1
and t2.pk-t1.pk>0 and concat(t2.pk,(t2.pk-t1.pk)) in
(select concat(t4.pk,min(t4.pk-t3.pk))
from yourTab t3, yourTab t4
where t4.pk >t3.pk and t4.pk-t3.pk <= 1
group by t4.pk)
上面代码的关键语句是 group by t4.pk, 代码比较复杂,容易出错。
两种方法各有利弊,第一种效率高,但是使用过程当中,如果两个表的查询条件不同,结果就可能不对。后面的代码复杂度比较高,运行速度也慢,但是两个表可以使用不同的条件满足更多的要求。据笔者简单测算,后面的速度比前面的慢了10几倍。
maraSun 2022-03-07 BJFWDQ


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









