






作者:来自 Elastic JINA

今天我们发布了 jina-code-embeddings,这是一个新的代码 embedding 模型套件,提供两种规模 —— 0.5B 和 1.5B parameters,并支持 1-4 bit GGUF 量化版本。基于最新的代码生成 LLM 构建,这些模型在体积紧凑的同时仍实现了最先进的检索性能。它们支持五种检索任务,包括 nl2code、code2code、code2nl、code2completions 和 qa,覆盖 15 种编程语言,包括 Python、JavaScript、Java、C++、C#、Go、Rust、TypeScript、SQL、MATLAB、R、Swift、Kotlin、HTML/CSS、PHP、Ruby、Scala、Perl 和 Shell。
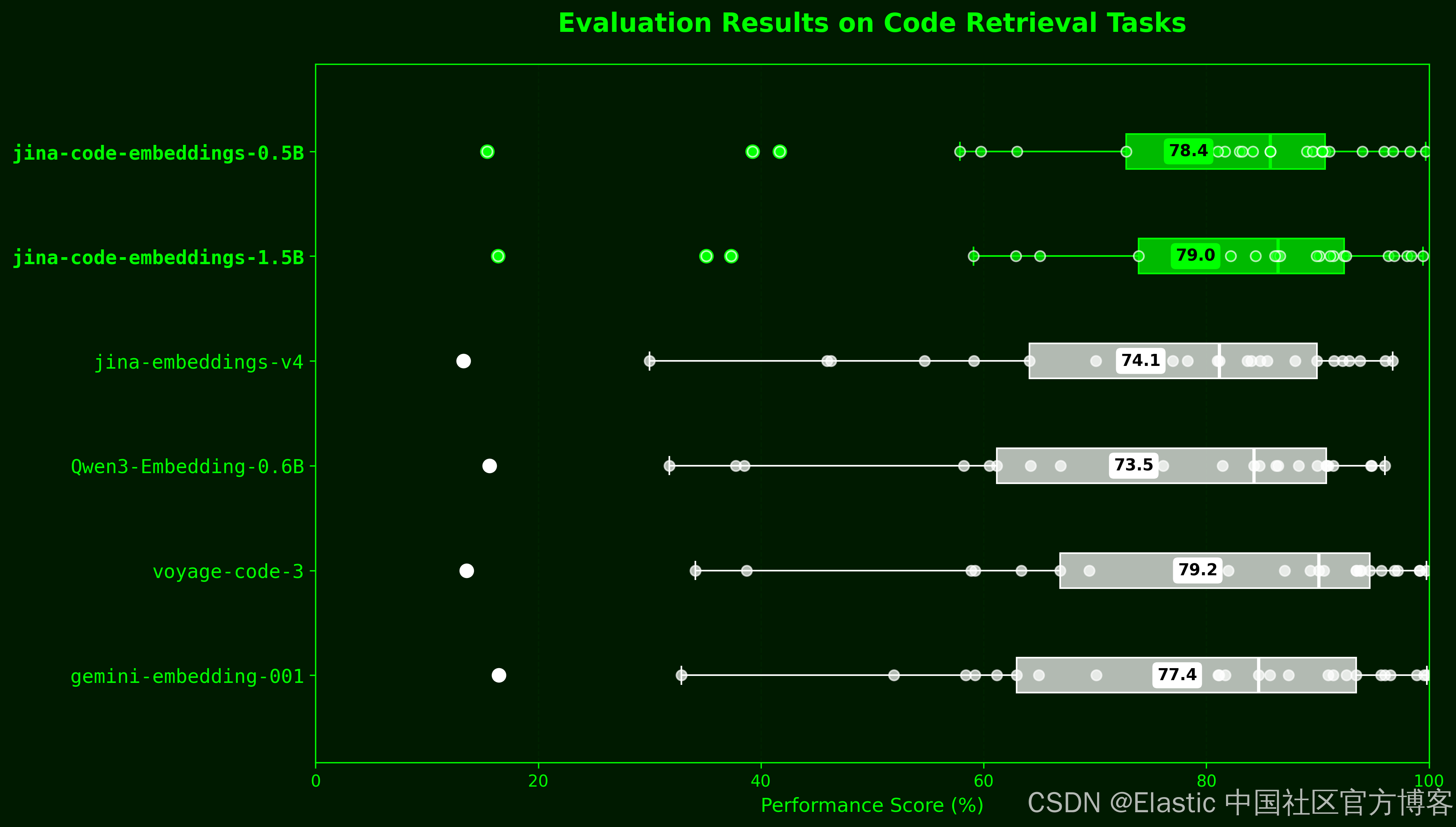
jina-code-embeddings 在 25 个代码检索基准上平均性能分别为 78.41%(0.5B)和 79.04%(1.5B)。0.5B 模型比 Qwen3-Embedding-0.6B 高 5 个百分点,尽管体积小 20%;1.5B 版本的性能与 voyage-code-3(79.23%)相当,并超过 gemini-embedding-001(77.38%)—— 这两个都是架构未公开的专有模型。
| Model | Parameters | Overall AVG | MTEB Code AVG |
|---|---|---|---|
| jina-code-embeddings-1.5b | 1.54B | 79.04% | 78.94% |
| jina-code-embeddings-0.5b | 494M | 78.41% | 78.72% |
| voyage-code-3 | Unknown* | 79.23% | 79.84% |
| gemini-embedding-001 | Unknown* | 77.38% | 76.48% |
| jina-embeddings-v4 | 3.8B | 74.11% | 74.87% |
| Qwen3-Embedding-0.6B | 600M | 73.49% | 74.69% |
*闭源且架构未公开的模型
两个模型都使用了五个针对不同检索场景的任务专用 instruction 前缀进行训练,每个前缀都支持 query 和 document 角色,用于非对称检索。例如,你可以使用 nl2code_query 来嵌入 queries,使用 nl2code_document 来嵌入 documents。
| Task | Use Case | Instruction Prefix |
|---|---|---|
nl2code | "How to read CSV" → pandas.read_csv() | "Find the most relevant code snippet given the following query:\n" |
qa | Technical Q&A retrieval | "Find the most relevant answer given the following question:\n" |
code2code | Finding similar implementations | "Find an equivalent code snippet given the following code snippet:\n" |
code2nl | Code to documentation | "Find the most relevant comment given the following code snippet:\n" |
code2completion | Autocomplete scenarios | "Find the most relevant completion given the following start of code snippet:\n" |
训练方案
我们使用预训练的代码生成模型作为 embedding backbone。基于 Qwen2.5-Coder-0.5B 和 1.5B 构建,我们的模型具有:
| Feature | jina-code-embeddings-0.5b | jina-code-embeddings-1.5b |
|---|---|---|
| Base Model | Qwen2.5-Coder-0.5B | Qwen2.5-Coder-1.5B |
| Embedding Dimensions | 896 | 1536 |
| Matryoshka Dimensions | 64, 128, 256, 512, 896 | 128, 256, 512, 1024, 1536 |
| Max Sequence Length | 32,768 tokens | 32,768 tokens |
| Pooling Strategy | Last-token pooling | Last-token pooling |
| Attention | FlashAttention2 | FlashAttention2 |
| Data Type | BFloat16 | BFloat16 |
传统的代码 embedding 模型面临一个根本瓶颈:高质量的注释 - 代码对用于监督训练的数量非常有限。通过使用在 92+ 编程语言上预训练 5.5 万亿 tokens 的 Qwen2.5-Coder,我们继承了对编程结构的深层语义理解、跨语言模式识别以及对语法和惯用法的内置知识。随后进行的对比微调(contrastive fine-tuning)将这些知识适配到检索任务上,只需最少的对齐数据 —— 绕过了限制仅 encoder 模型的数据稀缺问题。
对于诸如跨框架代码翻译等数据不足的任务,我们使用 LLM 生成了合成数据,每个合成示例都经过人工质量验证。我们的训练数据将现有的 MTEB 代码任务训练拆分与改编的公开数据集结合,包括 CommitPackFT、SWE-Bench、Spider、MBPP 和 CodeSearchNet。
与 jina-embeddings-v3 和 v4 不同,我们没有使用 LoRA,而是直接进行完整的后训练(full post-training)。对于像我们这样的轻量模型(494M 和 1.54B parameters),LoRA 的参数效率优势不明显 —— adapter 的额外开销在容量有限时反而可能影响性能。我们需要每个参数都用于 embedding 任务。即便在多任务场景下,任务专用的 instruction 前缀也比多个 LoRA adapter 更简洁。我们只需在前面添加不同指令,而不是切换权重配置 —— 更精简,也更符合 LLM 自然处理条件信息的方式。
训练效率非常高:两个模型都使用 InfoNCE loss 的对比学习在 4x A100 80GB GPU 上训练,0.5B 模型仅 8.3 小时完成,1.5B 模型 12 小时完成。
最后,我们对不同的 pooling 策略进行了基准测试。last-token pooling 达到整体平均 78.41%,在所有基准类别中稳定超过 mean pooling(77.20%)和 latent attention pooling(78.27%)。这 1.2 个百分点的优势促使我们打破在 jina-embeddings-v2、v3 和 v4 中建立的 mean pooling 传统。随着更多检索模型基于仅 decoder 的 LLM,last-token pooling 成为自然选择——mean pooling 与单向 attention 机制不太契合。虽然 mean pooling 可以使用,并且在训练早期通常更容易收敛(可能因为其凸优化特性),我们的实验一致显示,它的性能上限低于 last-token pooling 所能达到的水平。
入门
两个模型都可以通过我们的 Search Foundation API 无缝使用,并支持包括 sentence-transformers、transformers 和 llama.cpp 在内的流行框架。我们可以参考之前的文章 “Jina-VLM:小型多语言视觉语言模型” 来获取 JINA API key。
通过 API
curl http://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d @- <<EOFEOF
{
"model": "jina-code-embeddings-1.5b",
"input": ["print hello world in python"],
"task": "nl2code.passage"
}
EOFEOF
通过 sentence-transformers
from sentence_transformers import SentenceTransformer
# Load the model (choose 0.5b or 1.5b)
model = SentenceTransformer(
"jinaai/jina-code-embeddings-1.5b",
model_kwargs={"torch_dtype": "bfloat16"},
tokenizer_kwargs={"padding_side": "left"}
)
# Natural language to code
queries = ["print hello world in python", "initialize array of 5 zeros in c++"]
documents = ["print('Hello World!')", "int arr[5] = {0, 0, 0, 0, 0};"]
# Generate embeddings with task-specific prefixes
query_embeddings = model.encode(queries, prompt_name="nl2code_query")
document_embeddings = model.encode(documents, prompt_name="nl2code_document")
# Compute similarity
similarity = model.similarity(query_embeddings, document_embeddings)
通过 transformers
from transformers import AutoModel, AutoTokenizer
import torch.nn.functional as F
def last_token_pool(last_hidden_states, attention_mask):
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size), sequence_lengths]
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-code-embeddings-1.5b')
model = AutoModel.from_pretrained('jinaai/jina-code-embeddings-1.5b')
# Apply task-specific prefix
query = "Find the most relevant code snippet given the following query:\nprint hello world"
code = "Candidate code snippet:\nprint('Hello World!')"
# Tokenize and embed
batch_dict = tokenizer([query, code], padding=True, truncation=True, return_tensors="pt")
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
Matryoshka Embeddings 截断
两个模型都使用 Matryoshka(套娃) 表示学习训练,适用于维度 [64, 128, 256, 512, 896],允许你在不重新计算的情况下截断 embeddings:
# Full embeddings: 896d (0.5B) or 1536d (1.5B)
full_embedding = model.encode(text)
# Truncate to smaller dimensions for efficiency
small_embedding = full_embedding[:256] # Works for both models
tiny_embedding = full_embedding[:128] # 0.5B supports down to 64d
这种灵活性允许你根据需求在性能和效率之间进行权衡。
结论
jina-code-embeddings 表明,高效的 code embeddings 并不需要超大规模。通过基于 code generation 模型并应用针对性的微调,我们在参数量不到 1.5B 的模型上实现了最先进的性能。
这些紧凑模型(0.5B/1.5B)的强劲结果验证了我们的观点:正确的基础比参数数量更重要。生成模型理解 code 语义——这种理解可以直接转移到表示任务中。
这与 Jina AI 的更广泛愿景一致:统一架构,使 embedding 和 generation 都源于同一基础,推动 search foundation 模型的可能性边界。
原文:https://jina.ai/news/jina-code-embeddings-sota-code-retrieval-at-0-5b-and-1-5b/


















 2069
2069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









