





作者:来自 Elastic Scott Martens 及 Michael Günther

探索我们的 NeurIPS 2025 亮点,涵盖 model merging、 task vectors 和 VLM dynamics,以及我们的关于 Jina code embeddings 的 DL4C workshop 演讲 。
亲身体验 Elasticsearch :深入了解我们的示例 notebooks ,开始免费的 cloud 试用,或现在就在你的本地机器上试用 Elastic 。
在过去十年中, NeurIPS 已成为 AI 和 machine learning 领域最重要的学术会议之一,最重要的论文在这里发表,研究人员也在这里见面和交流。
来自 Elastic 的工程师 Michael Günther 和 Florian Hönicke 与 Daria Kryvosheieva 一起参加了今年在 San Diego 举办的会议。他们在 Deep Learning for Code ( DL4C ) workshop 上展示了她的实习项目 —— jina-code-embeddings models 。

Coding agents 和 automated coding 是非常热门的研究领域,也是今年 NeurIPS 的重点话题之一, DL4C workshop 上有 60 多篇论文和数百名参与者。能够生成 code 的 AI models 不仅对 software developers 很重要,它们还可以让 AI agents 执行 code 来解决问题,并与 databases 和其他 applications 交互,例如自己编写 SQL queries ,即时生成 SVG 和 HTML 用于展示,等等。
人们对 IT 行业中的 AI applications 非常感兴趣,包括Streams ,它正在使用 AI 来解读 system logs 。
Jina 在这一领域的贡献是一个非常紧凑、高性能的 embedding model,专门用于从 knowledge bases 和 repositories 中检索 code 和 computer documentation ,可应用于 IDEs 中的 code assistants ,以及以 IT 为中心的 RAG applications 。

总体来说,这次会议在 theoretical work 和 applied research 之间取得了很好的平衡。
12 月初的 San Diego 气候温和宜人,城市氛围也很轻松。人们在各个 session 之间会在室外停留,到了晚上,咖啡馆和酒吧里到处都是佩戴着 conference badges 的人。

我们在 NeurIPS 2025 学到了很多,也很享受这次前往一座在这个季节比 Berlin 温暖得多的城市的旅行。在这篇文章中,我们简要分享了我们在会议上觉得最有价值的内容。
Model merging: theory,practice 和 applications
这个 tutorial 由 Marco Ciccone 、 Malikeh Ehghaghi 和 Colin Raffel 主讲,特别有意思。过去几年里, model merging 已成为一种被广泛使用的技术,用于在针对特定 applications 进行 fine-tuning 时提升 AI models 的鲁棒性(robust)。在最简单的情况下,它通过对源自同一个 base model 的两个或多个 fine-tuned models 的 weights 进行平均来将它们组合在一起,如下图所示:
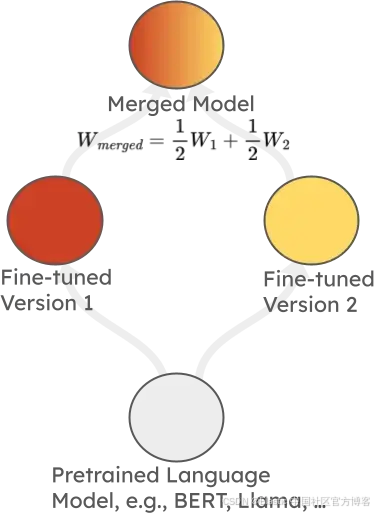
虽然听起来很简单,但这种方法通常有效,可以得到在两个 fine-tuned tasks 上表现更好(或至少不会差太多)的 models,同时保持 base model 在非特定任务上的性能。
这个 tutorial 对这一非常活跃的研究领域的最新进展进行了概览,尤其是超越简单 weight averaging 的更复杂 merging 方法的发展。值得注意的有:
-
TIES-Merging,通过选择 weight 的子集等方式,尝试减轻 weights 之间的 merging 冲突。
-
Fisher Merging 和 RegMean,利用 activation 信息来改善 model mergers 的结果。
-
还总结了在最大的 AI labs(如 Google DeepMind 和 Cohere)中使用的 model development 技术,这些实验室似乎都依赖于 model merging,显示了这一领域持续的兴趣和发展。
有趣的研究
我们还参加了 oral presentations 和 poster sessions,其中有几项给我们留下了特别深刻的印象。
大型语言扩散模型 - Large language diffusion models
Diffusion models 的工作方式与大多数 language models 非常不同。一般的 language models 使用 autoregressive 方法训练:给定一段文本,它们被训练去生成下一个 token。相比之下, diffusion language models 的训练文本中会有部分 tokens 被 mask 掉,模型学习去填充这些 tokens。它们以非线性方式生成文本,多次遍历文本并以无特定顺序添加 tokens,而不是一个接一个地生成单词。Diffusion 最初在 image generation 上取得了非常成功的应用,但直到最近才被广泛应用于文本。
这项研究将 diffusion 方法应用于一个相对较大的基于 transformer 的 language model(80 亿参数),用于 pretraining 和 supervised fine-tuning。在 pretraining 阶段,模型学习用随机(最多 100%)被 mask 的文本进行填充。在 supervised fine-tuning 阶段,prompt 从不被 mask,因此模型可以学习从 instructions 生成文本。
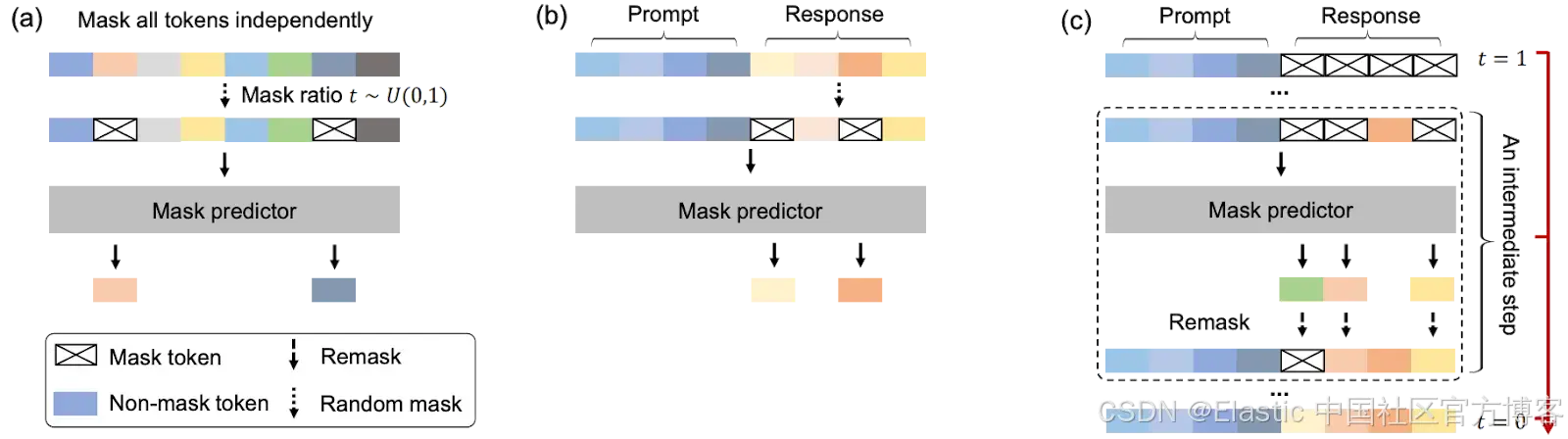
(a) Pre-training:LLaDA 在文本上训练,随机 mask 独立应用于所有 tokens,比例为 t ∼ U[0, 1]。
(b) SFT:只有 response tokens 可能被 mask。
(c) Sampling:LLaDA 模拟一个从 t = 1(完全 masked)到 t = 0(unmasked)的 diffusion 过程,每一步同时预测所有 masks,并使用灵活的 remask 策略。
得到的模型在许多任务上与 autoregressively 训练的模型表现相当,同时在某些领域表现突出,尤其是与数学相关的任务。这是 language modeling 研究中一个非常有前景的方向,我们也很期待 diffusion models 是否会在训练 language models 时变得更加重要,以及是否会被应用到 embedding models 上。
基于激活信息的大型语言模型合并 - Activation-informed merging of large language models
这篇论文提出了另一种改进 model merging 的技术。其直觉是,在合并一个或多个 fine-tuned models 时,识别并保留 base model 中最重要的 weights。

它使用一个 calibration dataset 来获取模型所有层的平均 activation,通过计算每个 weight 对模型 activation 水平的影响来识别最关键的 weights。然后利用这些信息决定在 merging 时哪些 weights 不应被大幅修改。
这种方法可以与其他 model-merging 技术兼容。作者展示了在将此方法与各种其他 merging 方法结合使用时,能取得显著改进。
SuperCLIP:带简单分类监督的 CLIP
一个众所周知的问题是,使用 Contrastive Language Image Pretraining (CLIP) 训练的 image-text models 由于架构限制以及通常用于训练 vision models 的 web-scraped 数据的特性,难以捕捉细粒度的文本信息。在开发 Jina-CLIP models 时,我们也发现 CLIP models 通常不擅长理解更复杂的文本,因为它们训练时使用的是短文本。我们通过向训练数据中添加更长的文本来进行补偿。
这篇论文提出了一个替代方案:在普通 CLIP 中添加一个新的 classification loss 组件。
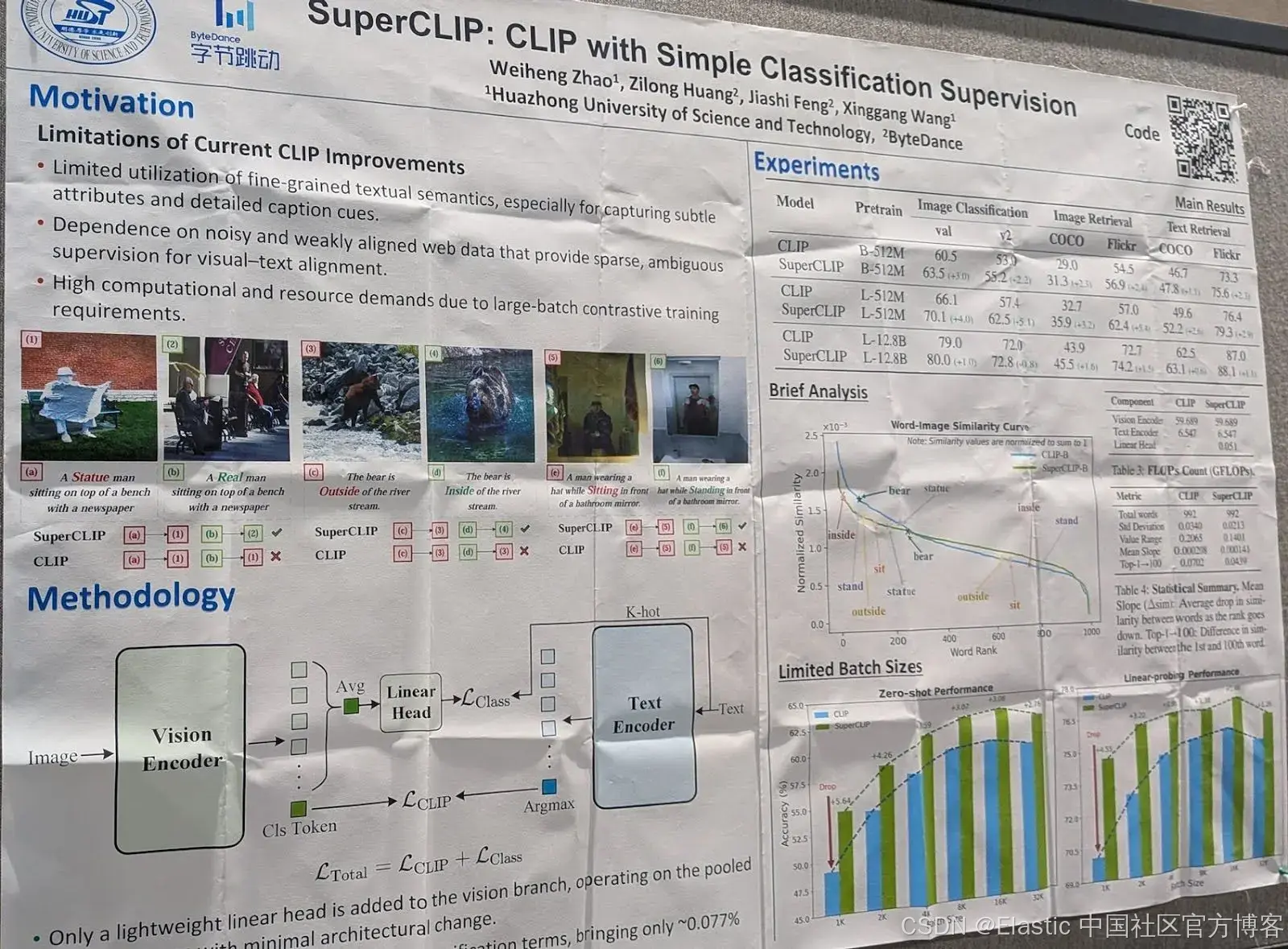
它依赖于训练时添加的 layers,使用输出的 image tile embeddings 来预测描述中的 text tokens。训练同时优化这一目标和 CLIP loss。
Datasets, documents, and repetitions:不均等数据质量的实际问题
这篇论文讨论了 large language models (LLMs) 训练数据质量的问题。通常,这类模型使用的大型 datasets 中常常包含重复项。然而,矛盾的是,去重(deduplication)往往会导致更差的结果。
作者提出了对这一令人困惑的发现的解释,并提供了一些解决方案的要素。
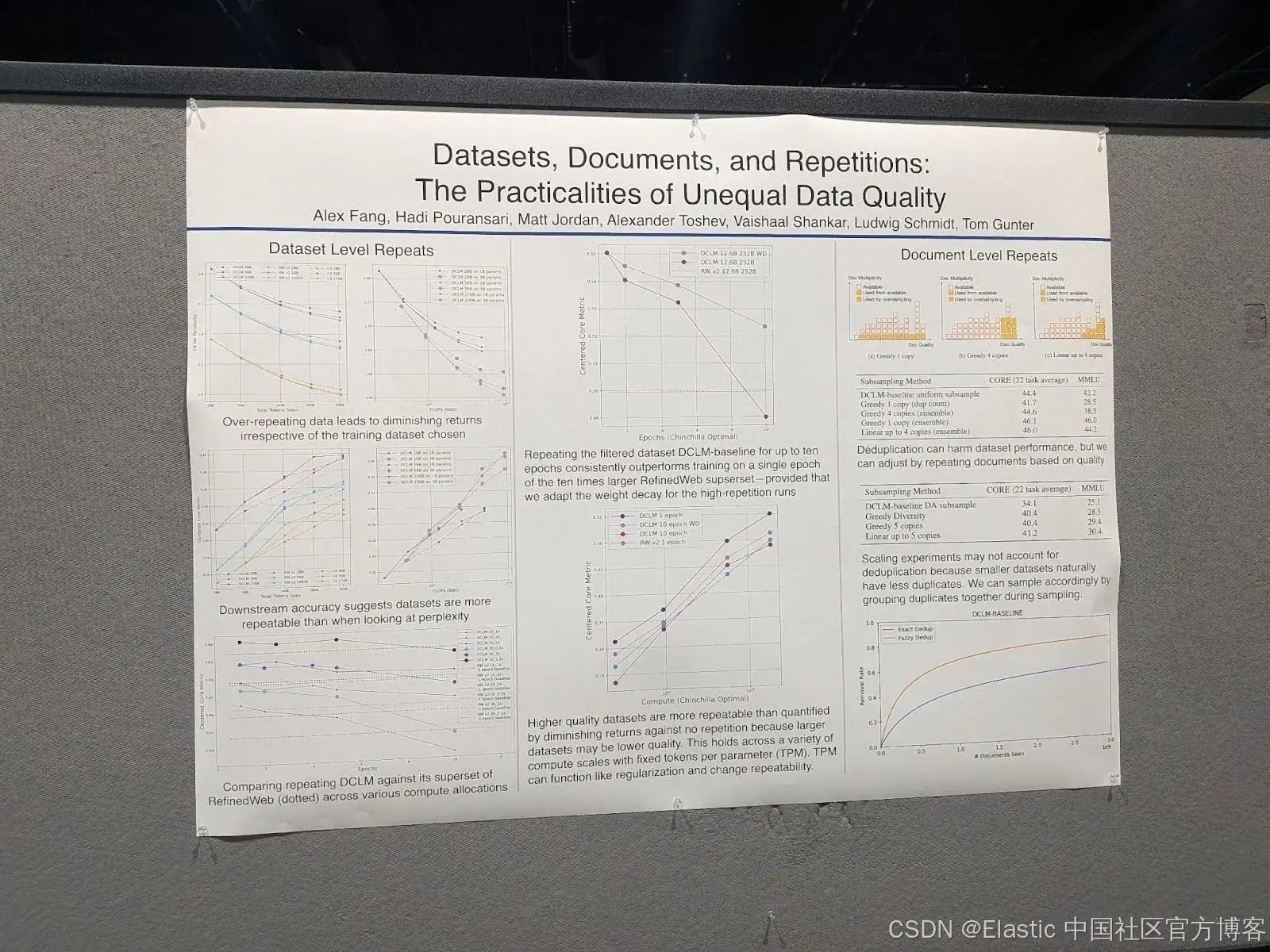
他们的主要发现是:
- Large models 在训练数据重复时受影响比 small models 更大。
- 复制高质量 documents 可以改善训练结果,或者至少比复制低质量 documents 对结果的影响小。
- 高质量 documents 在真实训练 datasets 中更可能出现多次。
- 这最后两点特别解释了去重(deduplication)的悖论。
强化学习真的能在 LLMs 中提升推理能力,超越 base model 吗?
基于可验证奖励的强化学习(RLVR)是一种使用 reinforcement learning 对 LLMs 进行 reasoning fine-tuning 的方法,它不需要人工标注,因为训练问题的解可以自动验证。这与 Reinforcement Learning from Human Feedback (RLHF) 不同,后者在训练期间需要直接的人工监督。例如,这可以用于训练模型解决数学问题或执行 coding 任务,输出可以由机器独立测试,例如自动检查数学问题的解答,或运行单元测试来验证一段代码是否正确。
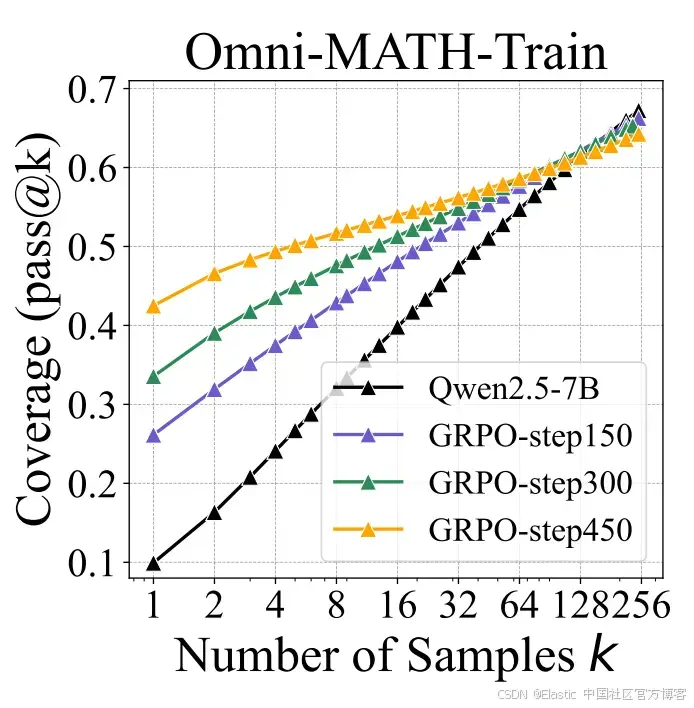
作者的测试方法是评估在给定不同尝试次数的情况下,模型对一组问题的正确答案数量。每次尝试都是在生成过程中采样一个答案。他们比较了模型在不同 RLVR 训练 epochs 后的表现。结果显示,训练显著提高了模型在只有一次或少数机会时的答案准确率,但在多次尝试时效果不明显。这表明他们提高了得到正确答案的概率,但并没有真正提升模型的推理能力。
结论
从会议活动来看,AI 研究仍在经历爆炸性增长,且没有结束迹象。学术工作仍然非常重要,尤其对那些没有数十亿美元预算租用数据中心进行研究的 AI 开发者来说尤为关键。
然而,这种爆炸性增长也使得跟踪所有最新进展变得越来越困难。
在 Elastic,尤其是在 Jina 团队,我们始终对 AI 的下一步发展充满期待,并尽力掌握最新进展和新兴研究方向。希望这篇文章能让你感受到这种兴奋,并一窥当今搜索 AI 领域的工作情况。
原文:https://www.elastic.co/search-labs/blog/neurips-2025-model-merging-task-vectors-code-embeddings


















 2032
2032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









