






作者:来自 Elastic Artem_Shelkovnikov

2025 年的企业系统搜索:要不要抓取(crawl)?
企业中有很多系统在使用: Github、 Gitlab、 Jira、 Confluence、 Sharepoint、 Salesforce、 Notion 等等。它们有不同的数据模型、不同的权限模型,而且往往差异多于相似之处。
不可避免地,关于流程、问题和解决方案的数据会分散在所有这些系统中。想象一个在组织中启动的项目:项目简介和其他文档写在 Google Docs 中,工作单元在 Jira 中创建,代码和文档放在 Github 里,客户支持工单存储在 Salesforce 中。
现在再想象有一个关于某个功能的支持工单进来,一名支持工程师需要进行分诊和问题排查。他们需要在每一个单独的系统中搜索 —— 手动或者通过前端。这会是大量的工作,而且每个系统的搜索体验和质量差异很大,使得找到答案成为一项并不简单的任务。再想象一个整个组织都在不断地查找答案、文档和讨论。这种搜索方式并不能很好地扩展。
我们需要一种方式,在不让用户登录并在每个系统中运行搜索查询的情况下,搜索企业系统中的数据。
抓取数据
传统的 Enterprise Search 系统,比如 Elastic Workplace Search,会使用 connectors 来抓取像 Sharepoint 或 Salesforce 这样的企业系统的内容。
我们以 Sharepoint Online 为例来看这个流程。
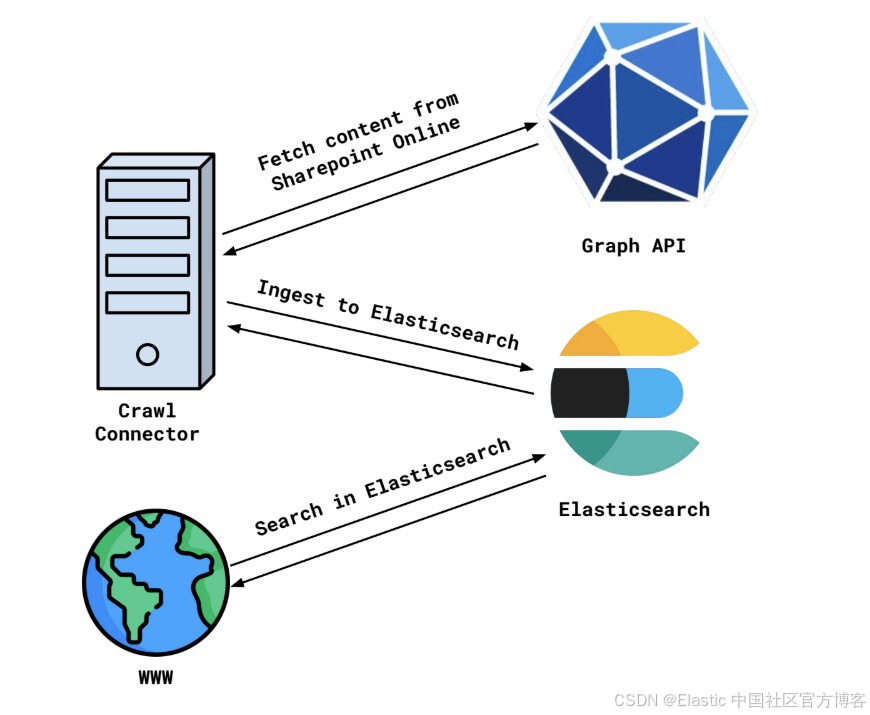
可以通过 Graph API 访问 Sharepoint Online。数据由一棵实体树表示 —— Sites、Site Pages、Site Drives(含 Drive Items)、Site Lists(含 List items)。每个实体也都有附加的权限 —— 有些 sites(或其他实体)是公开可见的,有些只对已登录用户可见,有些只对特定用户或组可见。
一个计划抓取(crawl)会启动,使用 Graph API 遍历 Sharepoint Online 实例的内容,然后将其存储到 Elasticsearch 或其他提供良好搜索能力的数据库中。对于用户需要搜索的每个系统重复这个过程,数据就存储在 Elasticsearch 中,并且可以很容易地通过你的网站进行搜索!这就是我们现有 Elastic content connectors 的工作方式。
当来自第三方系统的数据进入 Elasticsearch 后,我们得到显著的好处:
- 搜索更灵活、更相关。Elasticsearch 内置对全文搜索、向量搜索、语义搜索、重新排序的支持非常好 —— 这些为搜索提供了极大的灵活性,使结果更符合用户需求。
- 搜索更便宜、更快。像 Jira 或 Sharepoint 这样的系统扩展成本很高,而通过增加新的 Elasticsearch 实例或更好的硬件扩展 Elasticsearch 成本较低。同时 Elasticsearch 为搜索进行了优化,通常比从 Graph API 获取结果所需时间更少。
- Elasticsearch 易于扩展。如果负载增加,Elasticsearch 作为分布式数据库,本身可以横向和纵向扩展。根据需要添加或移除实例很容易,不会停机。
不过,这种方法并不完美,根本上存在一些难以解决的问题,例如:
- 同步可能需要几天才能完成。如果你的组织在 Google Drive、Sharepoint 和其他地方有 TB 级数据,遍历所有数据并上传到 Elasticsearch 不可避免地需要几天时间。如果第三方系统或 Elasticsearch 出现节流,或者远程系统负载很高且没有扩展预算,所需时间可能更长。
- 数据很快就会过时。由于同步可能需要几天完成,数据在同步结束时可能已经过时。某些情况下可以流式传输变更或增量同步,但并非每个系统都支持增量搜索。
- 文档级安全性难以实现。第三方系统的权限模型差异很大,从第三方 API 正确提取权限并不总是简单:可能存在隐藏组、运行时评估的基于规则的权限,以及许多复杂情况,使得推断实体权限几乎不可能。此外,即使使用 Okta 等外部身份提供商,将 Elasticsearch 中的用户与第三方系统的用户关联也不总是容易。
联合搜索
在 Workplace Search 中,有两个 connectors 支持我们称之为 “Remote Search” 的功能 —— 代表用户进行实时搜索。它们是 Slack 和 GMail connectors。用户使用他们设置的 OAuth 2 应用以自己的身份登录 Gmail。获取 token 后,就可以代表自己向 Gmail 的搜索 API 发出请求。
以之前 Graph API 的例子为例,非常简化的交互流程如下:
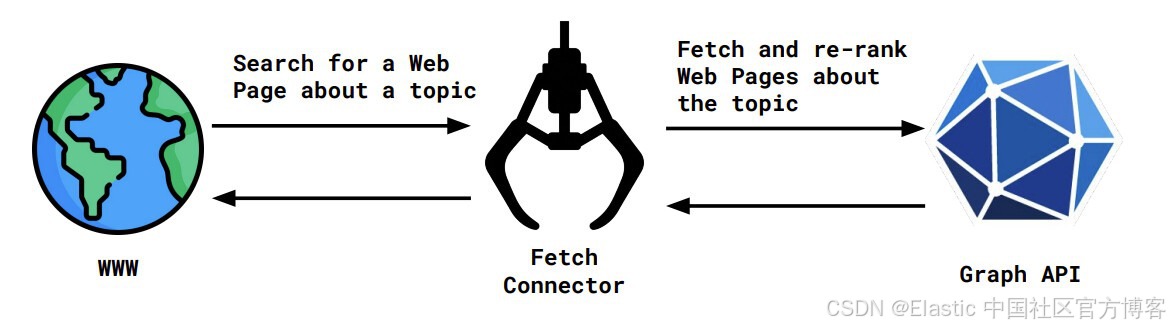
如前所述,这里的交互是非常简化的,但我们概念上来看一下设计。
按设计,联合搜索 connectors 有以下显著优势:
- 不需要从第三方系统获取所有数据来提供搜索结果。如果第三方系统中的数据量很大,需要很长时间才能同步,这是一大优势。此外,也不需要存储这些数据。
- 数据始终是最新的。数据不是被抓取的,而是在用户搜索时实时搜索。如果第三方系统有变化,搜索会立即返回最新结果。
- 用户始终只能看到自己有权限访问的数据。由于涉及 OAuth,用户以自己的身份认证,并授权搜索应用访问自己的数据。他们无法访问没有权限的数据。在抓取 connectors 的情况下,代表用户的 OAuth 凭证只能获取用户可访问的数据。如果每个用户都为自己设置抓取 connector,那么数据库中存储的数据量会非常巨大。
这些优势是抓取方式根本无法实现的。然而,这种方法也有缺点:
- 搜索和相关性质量高度依赖第三方源 API。如果第三方 API 仅提供精确匹配搜索词的端点,就无法进行任何语义搜索。搜索结果的相关性取决于第三方 API 的能力。如果第三方 API 不支持过滤,搜索结果的相关性也会显著下降。
- 第三方系统的节流和故障也会导致搜索应用中断。第三方系统有请求和吞吐配额。一旦超过配额,其 API 会开始返回错误信息,提示应用暂停并稍后重试。如果用户此刻需要数据,而第三方系统宕机,那么在系统恢复之前无法进行搜索。
这种方法在企业搜索系统中使用较少,但 Model Context Protocol (MCP) 的出现使这种方法变得更加流行。现在,使用 Claude Code、 Visual Studio Code 或类似应用且带 MCP Client 的用户,可以使用 LLM 查询第三方系统,LLM 会帮助重新排序和总结用户搜索结果。
当数据源数量增加且数据分散在各系统时,这种方法真正体现其优势 —— 带 LLM 的搜索应用可以查询多个系统、合并结果、重新排序,并即时提供相关且更准确的结果,而无需抓取所有系统的内容,这可能需要几周时间。
不过,这并不是万能的。如果 MCP 工具的结果相关性低,或者文档很大,LLM 可能无法提供好的答案。不过,这个问题可以通过改进 LLM 使用的工具来解决。
- 如果第三方系统无法运行语义搜索,LLM 可以帮助重新表述查询。想象一个用户搜索术语 “cat”,但他们要找的文档实际上包含词 “feline”。LLM 可以将 “cat” 拓展成一个同义词云,包括 “kitten”、“feline”、“tabby”等词。这可以增加找到期望文档的机会,而无需用户手动重新表述查询。
- 从第三方来源过度抓取并重新排序结果可以显著提高相关性。如果第三方应用不进行相关性排序,用户寻找的结果可能不会出现在搜索返回的第一批文档中。可以通过从第三方系统获取更多搜索结果并实时重新排序来解决这个问题。这也有助于处理大文档,因为大文档会增加 LLM 的上下文窗口大小 —— 将文档分块并只返回相关块可以帮助 LLM 提供准确结果,同时保持上下文窗口可控。
理论上,这两种方法可以以模块化方式结合使用 —— 对于每个用例,用户可以选择使用查询重新表述、过度抓取、分块和重新排序来提高相关性。
搜索正在变化
几年前,我们不会想到让用户直接在自己的机器上获得搜索体验。提供 Web 界面的搜索大应用曾是主流,但随着 LLM 的出现和 MCP 协议的发展,搜索正在变化。新的搜索是一种由 AI agent 辅助的搜索,更加分布式、个性化且相关性更高。
最终,联合搜索很棒!它提供实时体验、新鲜数据和开箱即用的权限控制,但其缺点存在,并可能成为决定因素。
最终,最佳搜索体验在于抓取数据与联合搜索的结合。
抓取仍然是静态内容和简单权限模型的好方法 —— 例如共享的 Google drives、网站和 wiki。抓取并存储在 Elasticsearch 中后,数据始终可用且易于搜索。
联合搜索在数据量大、数据需要实时更新或数据访问权限复杂且需严格执行时非常有效。
最终,每个用例都需要在将数据抓取到数据库和联合搜索之间找到良好的平衡,以获得更高的相关性。
Elastic Agent Builder 提供了一个很棒的平台,使得使用这两种方法结合构建出优秀的搜索体验变得更容易 —— 拥有对 Elasticsearch 索引中的静态内容访问权限的自定义 agent 和实时联合搜索 connectors,可以通过聊天界面提供高相关性的优质搜索体验!通过内置于 Kibana 的 MCP Server,同时支持联合搜索和 Elasticsearch 搜索,Agent Builder 可以成为你所寻找的现代搜索的窗口!


















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









