






作者:来自 Elastic Alexander Marquardt
了解为什么加法增强方法会使 BM25 排名不稳定,以及乘法评分如何在 Elasticsearch 中提供可控、可扩展的排名影响。
测试 Elastic 领先的、开箱即用的能力。深入了解我们的示例 notebooks,开始免费的 cloud 试用,或现在就在你的本地机器上试用 Elastic。
BM25 是 Elasticsearch 中最广泛使用的基于文本的评分模型之一。在许多电子商务实现中,它是决定产品相关性的主要组成部分,因为它提供了一个易于理解、可解释的分数,用来反映商品与用户查询的匹配程度。除了这种文本相关性之外,商品运营和搜索团队通常还需要通过业务指标来影响排序,例如利润率、库存水平、受欢迎程度、个性化或营销活动策略,同时又不破坏底层的文本相关性。
实现这一点最直观的手段是使用带 boost 的 should 子句或 rank_feature 字段。它们在一开始看起来可能有效,但随着查询模式变化或商品目录结构发生变化,这两种方法都会退化,甚至失效。它们的共同局限在于:在一个不同查询之间尺度变化很大的评分系统中,引入了加法调整。像 “+2” 这样的 boost,可能在某些查询中压倒基础的 BM25 分数,而在另一些查询中几乎不起作用。换句话说,加法方法可能会导致脆弱且不可预测的排序行为。
相比之下,使用 function_score 的乘法增强提供了一种稳定、数学上成比例的方式来塑造 BM25 分数,而不会扭曲其底层结构。你的应用逻辑决定哪些因素值得提升;function_score 以一种可预测、可解释的方式表达这种意图,保留了 BM25 相关性信号的几何结构(高层次的相对排序),通过受控的方式微调排名,而不是淹没核心的文本相关性。
本文基于之前的两篇文章,这两篇文章展示了乘法增强的实际用法:(1) 使用 Elasticsearch 中的 function score query 通过利润和受欢迎度来增强电子商务搜索,以及 (2) 如何通过个性化的、基于群组的排序来提升电子商务搜索相关性。在这里,我们从这些示例中抽身,回到其背后的架构原则:为什么通过 function_score 进行乘法增强,是在 Elasticsearch 中影响基于 BM25 排名时最可靠、最具扩展性的方法之一。
为什么保留基础 BM25 排名很重要
在许多基于 Elasticsearch 的应用中(包括电子商务),BM25 仍然是评估文本相关性的核心组成部分。它提供了一个可解释、透明的信号,方便需要理解为什么某个产品会排在当前位置的团队使用。这些特性使 BM25 在强调可解释性和运行可预测性的环境中特别有吸引力。
正因为如此,大多数团队希望对 BM25 生成的排名进行塑形,而不是替换它。例如,他们可能希望让高利润商品稍微更常出现,降低低库存商品的曝光度但不将其隐藏,或者突出与特定用户群体匹配的商品。理想情况下,这种塑形应当保留 BM25 算法生成的排名几何结构。
问题出现在团队尝试通过在基础 BM25 排名之上叠加独立评分流来实现这些目标时。这些加法调整并不总是与 BM25 的评分尺度可比,并且会随着查询、数据分布和商品目录结构的变化而表现不一致。随着时间推移,排序会变得脆弱、不直观,且难以调优。一个可靠的影响机制必须与 BM25 的评分几何结构协同工作,而不是压倒它。
使用乘法增强的 function_score 查询正具备这一特性。它允许团队以成比例、可解释的方式施加业务影响,同时保持 BM25 底层结构的完整性。
为什么许多影响排序的方法会削弱(甚至破坏)BM25
团队通常会从一些看起来很直接的机制入手:带 boost 的 should 子句、rank_feature 字段,或自定义 script_score 逻辑。这些工具在各自的设计场景中是有效的,这也是为什么它们看起来像是添加业务影响的自然手段。但当它们被用来塑造或影响基于 BM25 的文本相关性时,往往会导致不稳定、不透明或脆弱的排序行为。
根本问题在于,这些方法在一个基础 BM25 值在不同查询、字段和数据集之间差异很大的系统中,引入了彼此独立的加法评分贡献。如果不尊重这种变化性,影响效果就会变得不可预测。
下面是三种最常见的模式,以及它们在实际中为何会失败。
1)通过 should 子句进行加法增强
带 boost 的 should 子句看起来很直观:“提升符合这个业务规则的商品。” 但在底层,这种行为本质上是加法的。
考虑如下形式的查询:
GET products/_search
{
"query": {
"bool": {
"must": [ { "match": { "description": "running shoes" }}],
"should": [ { "term": { "brand": { "value": "nike", "boost": 1 }}}]
}
}
}这种查询会产生如下行为:
final_score = base_BM25 + should_BM25问题在于 base_BM25 和 should_BM25 并不会一起按比例变化。随着数据集变化,或发出不同的查询,BM25 的量级可能会发生巨大变化。例如,在某种情况下,三个商品的基础 BM25 分数可能是 12、8、4;而在另一种情况下,可能变成 0.12、0.08、0.04。这种变化可能发生在商品目录更新之后,或查询结构被修改之后。
一个带 boost 的 should 子句会向最终分数中加入它自己的 BM25 风格贡献。在这种情况下,加法贡献(例如 should_BM25 = +2)会表现得非常不一致:
- 当 base_BM25 很小(0.12)时,+2 会主导最终分数 —— 大约是 18 倍的提升。
- 当 base_BM25 很大(12)时,同样的 +2 几乎不会改变文档位置 —— 只有大约 17% 的提升。
这种不稳定性意味着,组合后的 must 分数和 should 分数在不同查询或不同商品目录之间并没有稳定的语义。一个在某个查询中只是轻微提升品牌的规则,可能在另一个查询中主导整个排序,又在第三个查询中几乎不起作用。这不是调参问题,而是加法评分在结构层面上的固有属性。
2)使用 rank_feature 来施加业务影响
rank_feature 系列在表示诸如新鲜度或受欢迎度等数值特征时非常有用。它速度快、存储紧凑、运维简单。然而,当它被用来影响文本相关性(BM25)时,会遇到与上一节所述相同的结构性限制。
rank_feature 子句会生成它自己的评分贡献,然后将其加到 BM25 分数之上:
final_score = base_BM25 + feature_score就像带 boost 的 should 子句一样,这两个组成部分并不会一起按比例变化。BM25 的取值会随着查询中词项的稀有程度和商品目录统计而大幅波动,而 feature_score 则遵循被增强的业务属性本身的尺度(例如受欢迎度或新鲜度),这一尺度通常与 BM25 的尺度毫无关系。结果是,随着语料或查询模式的演进,这两条评分流会逐渐偏离。
其后果与前面讨论的 should 子句问题是一样的:
- feature score 可能在某个查询中主导 BM25,而在另一个查询中几乎可以忽略不计。
- 调参变得非常脆弱,因为你在校准两个彼此独立的尺度 —— 一个是随查询词项统计变化的 BM25,另一个是随业务属性自身分布变化的 feature score。
尽管 rank_feature 仍然是表示原始数值属性的优秀机制,但它并不适合用于对 BM25 施加成比例的影响;在这种场景下,目标不是增加第二个分数,而是对已有分数进行温和的塑形。
使用 script_score 进行自定义评分
当带 boost 的子句或 rank_feature 字段难以调优时,团队通常会将 script_score 作为最后手段。它提供了完全的自由来操作分数,包括根据任何业务规则加、减、乘或替换 BM25 值。script_score 查询会用自定义逻辑替换 Elasticsearch 的评分管道。脚本不是对 BM25 分数进行塑形,而是构建一个独立的评分机制,其行为完全取决于脚本内部的代码。虽然这很强大,但在系统规模扩大时,会引入三个更为显著的挑战。
-
不透明性
评分逻辑隐藏在脚本中,而非以声明方式表达。当排名行为出现意外变化时,很难判断问题出在脚本本身、数据变化,还是与 BM25 的交互。商品运营和相关性工程师失去了理解文档排名变化原因的能力。 -
性能与运维成本
脚本评分绕过了 Elasticsearch 的许多优化和缓存路径。每个匹配初始查询的文档都必须执行脚本,通常导致 CPU 使用率升高和延迟不可预测。 -
与 BM25 结合时的脆弱性
由于 script_score 允许任意计算,很容易产生不再类似 BM25 的评分行为,或者无法保持其相对结构。随着数据集的发展或查询模式的变化,自定义逻辑可能以意想不到的方式与 BM25 交互。在开发初期表现合理的脚本,一旦商品目录增长或数据分布变化,就可能产生令人意外或不稳定的结果。由于 script_score 允许任意数学操作,不同工程师在系统不同部分可能无意中编码了冲突的评分模型,使得随着组织规模扩大,排名变得难以理解。
function_score 如何对 BM25 提供可预测影响
BM25 已经衡量了文档与查询的匹配程度。它反映了文本相关性、词项稀有度、文档长度以及语料库的统计特性。当团队引入商业信号,包括 margin、库存水平、流行度、个性化或 merchandising 策略时,目标不是替代这种相关性,而是影响它。
这种区别微妙但关键。大多数业务需求本质上是比例性的:
- 略微提升高 margin 商品
- 减少低库存商品的曝光,但不隐藏它们
- 对这个用户群体的匹配商品略微提升
- 提升流行度,但不要让文本相关性丢失
这些自然以百分比调整而非固定加值表示。merchandiser 很少会要求“+2 分的 score”;他们要求的是“稍微增加可见度”,无论 BM25 分数的绝对数值是多少。数学上,这意味着所需的变换是:
final_score = BM25 × boost_factorboost_factor 可能是 1.05、1.2 或 1.5,取决于信号。乘法提升不会试图重新发明评分;它只是按比例调整 BM25 输出。乘法调整有三个特性,与现实世界的排序控制非常契合:
- 提升保持比例。换句话说,20% 的提升始终是 20% —— 无论 BM25 是 0.12 还是 12。提升的大小不依赖于 BM25 的底层尺度。
- BM25 保持其作为主要信号的作用。乘法调整轻微改变排序而不覆盖它。强文本匹配仍然优先;商业逻辑影响排序,但不主导。
- 因为操作是乘法而非加法,改变查询或更新语料库时不需要重新调整数值常量。提升在任何地方都有相同的意义。
Elasticsearch 的 function_score 查询提供了一个优雅的机制来表达这种模式。通过使用:
- score_mode: “sum” 来组合 boost factor(构建乘数),以及
- boost_mode: “multiply” 将提升(乘数)应用到 BM25
你可以以一种稳定且可解释的方式表达商业意图,随着数据和查询模式的发展仍然有效。function_score 不是在 BM25 旁边增加第二个分数,而是直接转换 BM25 —— 轻柔、可预测地调整,符合 merchandisers 和产品负责人对排序调整的思路。
实践中的例子:乘法提升在真实电商查询中的表现
为了说明乘法提升在真实排序场景中的作用,查看一个小而具体的例子会很有帮助。这里的目标不是展示调优或生产级评分,而是展示 function_score 如何以可预测、比例化的方式影响 BM25,与商业意图保持一致。
考虑一个简单的目录,有三双不同品牌的篮球鞋:Nike、Adidas 和 Reebok。产品描述是有意设计的,使 BM25 分数根据查询的具体性和字段长度表现出自然差异 —— 就像在真实目录中一样。
示例数据集
在以下例子中,我们使用一个小而简单的样本数据集,具有以下特征。
| Brand | Description |
|---|---|
| nike | “Nike basketball shoes” |
| adidas | “New Adidas basketball shoes” |
| reebok | “Reebok basketball shoes” |
我们可以使用 Kibana Dev Tools 中以下命令创建包含上述产品的索引:
PUT products
{
"mappings": {
"properties": {
"brand": { "type": "keyword" },
"description": { "type": "text" }
}
}
}
POST products/_bulk
{ "index": { "_id": "nike-001" } }
{ "brand": "nike", "description": "Nike basketball shoes" }
{ "index": { "_id": "adi-001" } }
{ "brand": "adidas", "description": "New Adidas basketball shoes" }
{ "index": { "_id": "ree-001" } }
{ "brand": "reebok", "description": "Reebok basketball shoes" }使用这个数据集,我们现在评估三个查询:
- 基准 “basketball shoes” 搜索
- 同样的查询,但对 Adidas 提升 50%,对 Nike 提升 25%
- 一个特定的 “Reebok basketball shoes” 查询,同时 Adidas 和 Nike 的提升仍然生效
每个场景都展示了乘法提升的不同特性。
1)基准排序:无提升
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"match": { "description": "basketball shoes" }
}
}⚠️ 本文中的示例在单节点测试集群(Elasticsearch 8.18.1)上运行,并且索引只有一个 primary shard。如果你使用 Elastic Cloud Serverless,它默认会为你的索引分配三个 primary shard。因此,如果你想重现本文中显示的相同 BM25 分数,你可以通过在搜索请求中添加
?search_type=dfs_query_then_fetch来启用全局分数计算。这个参数对于重现分数很有用,但通常不需要,并且不推荐在生产系统中使用。包含此参数后,上述查询将变为:POST blog_food_products/_search?search_type=dfs_query_then_fetch { "size": 5, "_source": ["description", "margin"], "query": { "match": { "description": "McCain Chips" } } }
dfs_query_then_fetch会在索引级别而非每个 shard 级别计算 BM25 词项统计,从而使分数在不同环境中更加一致。
该查询返回以下结果,其中 Nike 和 Reebok 排在 adidas 之前:
| Rank | Brand | Score (BM25) |
|---|---|---|
| 1/2 (tie) | nike | 0.27845407 |
| 1/2 (tie) | reebok | 0.27845407 |
| 3 | adidas | 0.24686474 |
2)使用 function_score 给 Adidas 和 Nike 增加权重
如果市场活动要求 Adidas 篮球鞋增加 50% 权重,Nike 增加 25% 权重,应用层可以这样构造查询:
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"function_score": {
"query": {
"match": { "description": "basketball shoes" }
},
"functions": [
{
"filter": { "term": { "brand": "adidas" } },
"weight": 0.5
},
{
"filter": { "term": { "brand": "nike" } },
"weight": 0.25
},
{
"weight": 1.0
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}乘数是如何构造的:
- 基础权重 = 1.0
- Adidas 额外增加 +0.5 → Adidas 的乘数 = 1.5
- Nike 额外增加 +0.25 → Nike 的乘数 = 1.25
- 其他品牌(包括 Reebok)保持基础权重乘数 = 1.0
应用乘数:
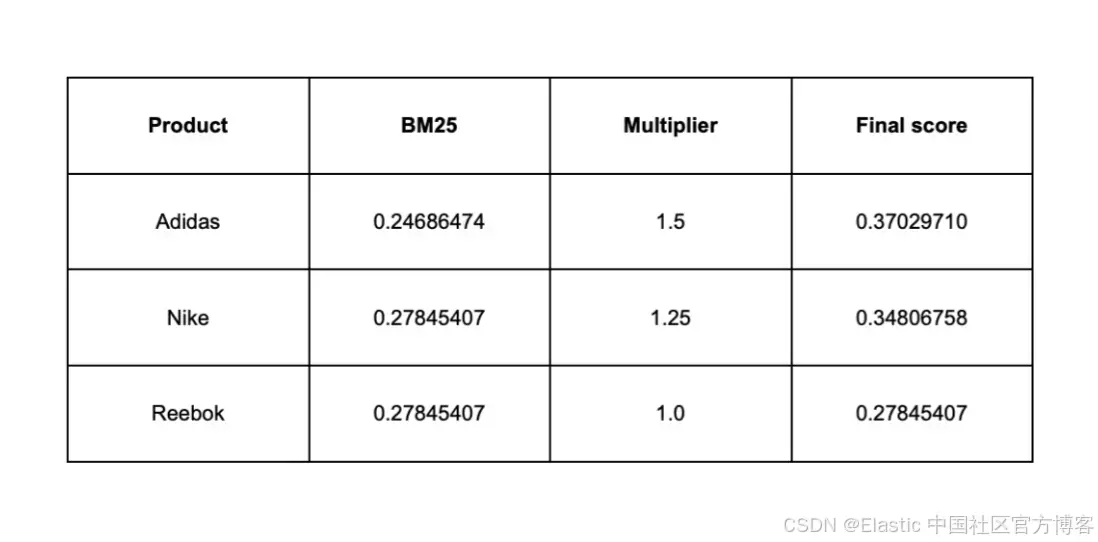
最终得分 = BM25 × 乘数
Product BM25 Multiplier Final score
Adidas 0.24686474 1.5 0.37029710
Nike 0.27845407 1.25 0.34806758
Reebok 0.27845407 1.0 0.27845407
结果
Adidas 排到最前,Nike 紧随其后,Reebok 保持在底部,分数没有变化。这正是乘法提升设计要实现的效果:
- Adidas 和 Nike 都获得了更多曝光,但按配置的提升比例增加。
- BM25 的相对差异仍然重要;我们是在调整排名,而不是替换它。
- 排序变化主要发生在 BM25 分数接近的情况下。
- 使用加法提升时,相同的 “50% 对 25%” 业务意图需要在任意 BM25 量表上用数字常量近似,并且效果会在不同查询间大幅变化。
3)特定意图仍然优先:“Reebok basketball shoes”
现在运行一个针对 “Reebok basketball shoes” 的高特定品牌查询,同时保持 Adidas(50%)和 Nike(25%)的促销仍然生效:
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"function_score": {
"query": {
"match": { "description": "Reebok basketball shoes" }
},
"functions": [
{
"filter": { "term": { "brand": "adidas" } },
"weight": 0.5
},
{
"filter": { "term": { "brand": "nike" } },
"weight": 0.25
},
{
"weight": 1.0
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}结果显示如下:
| Rank | Brand | Final score |
|---|---|---|
| 1 | reebok | 1.3011196 |
| 2 | adidas | 0.3702971 |
| 3 | nike | 0.34806758 |
结果
Reebok 压倒性获胜,因为 BM25 正确识别了 “Reebok basketball shoes” 的强烈意图。Adidas 和 Nike 仍分别获得 50% 和 25% 的提升,但这些乘数远不足以覆盖 BM25 分数。
这正是乘法提升设计要实现的效果:
- 当 BM25 分数接近时,提升可以改变相对排序。
- 当 BM25 分数差异显著时(如本例,由于强文本匹配),相同的提升几乎没有实际效果。
- 促销影响排名,但不会覆盖核心文本相关性信号。
本例展示了什么
这些实际查询展示了乘法提升的关键特性:
- 影响是按比例的,而非任意的。基于百分比的提升在任何 BM25 量表下都有相同比例效果。
- 文本相关性保持主导。强品牌意图的查询仍然显示正确的产品。
- 系统行为直观。商品经理可以看到期望的排名变化。
- 数学在所有查询中稳定。无论匹配广泛还是高度具体,相同的促销都能正确应用。
- 应用逻辑保持清晰。业务层决定提升;Elasticsearch 可预测地应用它。
通过 function_score 的乘法提升在可控和可预测的方式下保留了相关性,同时实现了业务影响。
应用逻辑仍然是影响的作者
决定哪些内容应该被提升与在 Elasticsearch 中应用该提升之间有明确的分离。function_score 负责第二部分,而第一部分完全属于应用逻辑。
你的应用逻辑负责做出如下决策:
- 哪些利润阈值对业务重要
- 是否根据季节性调整受欢迎度
- 如何解读客户行为或群体归属
- 如何编码活动规则
- 何时显示或屏蔽某些产品组
这些是业务决策,而不是评分决策。Elasticsearch 不会判断用户是注重预算还是奢侈品、是否有促销活动,或者低库存是否需要调整曝光度。这些判断发生在上游系统中,系统可以访问用户上下文、会话特征、分析数据和业务配置。在应用逻辑生成明确的数字信号(如权重、提升因子、阈值、群体标签)之后,function_score 查询提供了一种可靠方式,将这些信号以可控乘数应用于 BM25。
这创建了一个清晰的架构约定:
- 应用逻辑:决定哪些内容应受影响
- BM25:提供核心文本相关性
- function_score:以数学稳定的方式应用影响
因为业务逻辑位于索引之外,团队可以在不重新索引或重构文档的情况下调整或实验提升策略。
结论
电商搜索必须在核心文本相关性与业务考虑(如盈利能力、库存状况、客户意图、季节性和个性化)之间取得平衡。BM25 提供稳定且可解释的文本相关性基础,但影响该分数需要谨慎。业务信号应塑造排名,而非覆盖它。
然而,最常用的手段如 boosted should 子句、rank_feature 字段和临时脚本评分往往表现不稳定。这些方法在开发早期看似有效,但随着目录变化或新查询模式出现,其局限性很快显现。加法提升波动巨大,因为其影响完全依赖于 BM25 的底层量表,而 BM25 在不同查询中变化极大。在某种情况下产生微小调整的提升,在另一种情况下可能主导排序。脚本评分则带来不透明逻辑、性能下降以及评分行为难以理解或维护的问题。
通过 function_score 的乘法提升避免了这些问题,它按比例调整 BM25,而不是与其竞争。它不是添加一个独立的分数组件,而是对 BM25 本身应用可控乘数。这产生了商品经理实际期望的可预测调整,例如:轻微提升高利润商品、适度降低低库存商品的可见性,或为相关用户群体提供温和提升。
同样重要的是,架构保持清晰。应用逻辑决定哪些业务信号重要,function_score 以一致且可解释的方式应用它们。业务团队可以演化策略而不破坏相关性,工程团队可以优化相关性而不干扰业务规则。
这一原则是之前博客的基础,这些博客展示了如何影响电商排名:
两种方法都基于一个理念:业务信号应引导 BM25,而不是覆盖它。通过 function_score 的乘法提升,提供了一种在实际电商搜索中实现这种平衡的可行、透明且可扩展的方法。
原文:https://www.elastic.co/search-labs/blog/bm25-ranking-multiplicative-boosting-elasticsearch


















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









