






作者:来自 Elastic _som

你是否希望可以直接和你的费用数据对话?
可以这样问:
“我上周花了多少钱?”
“显示我这个月的餐饮支出。”
“添加我昨天用 信用卡 支付的 350 的晚餐费用。”
这个项目将这些自然语言消息,甚至语音消息,转换为结构化数据和可搜索的洞察,使用了:
- Telegram 作为聊天 UI
- n8n 作为工作流编排器
- AWS Bedrock(本示例中使用 Claude 3.5 Sonnet)用于意图分类、数据写入和对话式查询 agent(你可以替换为任何你选择的 LLM)
- Sarvam Speech-to-Text 用于语音转写(你也可以接入 Whisper、Deepgram、AssemblyAI,或任何你觉得合适的方案)
- Elasticsearch Agent Builder + MCP 负责存储、语义搜索,以及自定义 ES|QL 函数调用工具
另外,还准备了一个单独的 Colab notebook,用于自动部署整个 n8n 工作流,这是临时的。对于长期运行的 n8n 服务,建议你将其部署在你自己的服务器上,而不是使用 Colab。
这个系统做了什么
- 将语音 → 文本
- 判断消息类型是:
- INGEST(“我在午餐上花了 250”)
- QUERY(“我上个月花了多少钱?”)
- 将结构化 JSON 和语义 embedding 写入 Elasticsearch
- 使用 Agent Builder 工具运行有上下文的 ES|QL 查询
- 在 Telegram 中返回友好的回复
- 在分类置信度较低时,通过交互式澄清步骤来处理
n8n 架构一览
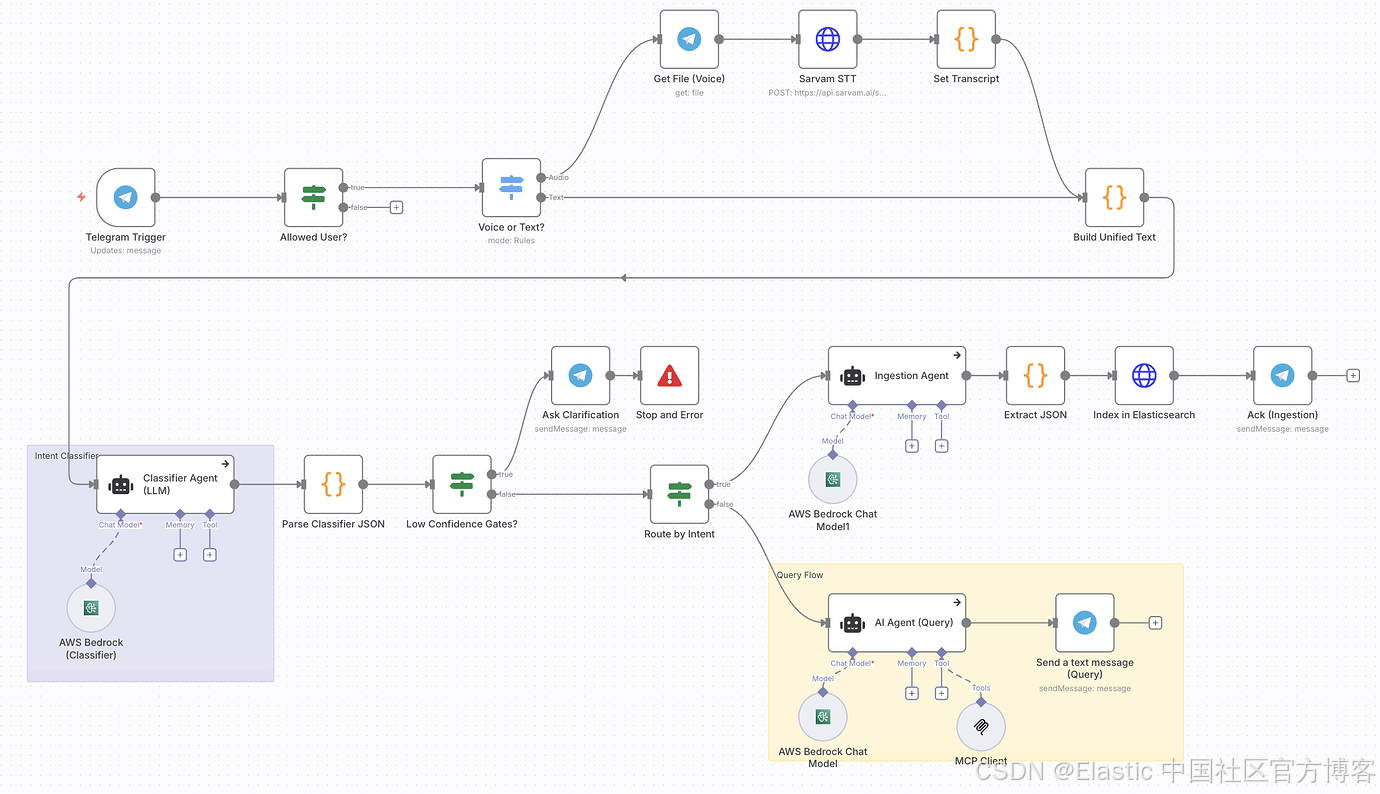
流程:
Telegram → n8n( STT → Classifier → Ingest / Query 路由)→ AWS Bedrock LLMs → Elasticsearch(索引 + 使用 MCP 的语义搜索)→ Elastic Agent Builder 工具 → Telegram 响应
关键节点 / 组件
n8n Workflow
- Telegram Trigger
- 语音 / 文本 切换
- STT 请求
- Classifier agent
- Ingestion agent
- 通过 Agent Builder MCP 的 Query agent
- Elasticsearch indexer
- 低置信度门控
Elasticsearch
- 启用带有 Bedrock embeddings 的 semantic_text 字段
- 干净的索引 mapping( amount 、 merchant 、 category 、 ts / @timestamp 、 raw_transcript )
- 使用 ES|QL 构建的 Agent Builder 工具
AWS Bedrock
- Claude 3.5 Sonnet v2 用于:
- Intent 分类
- Expense JSON 提取
- Query agent 推理(通过 MCP 进行函数调用)
自己动手试试( 一键设置 )
我把所有内容都打包在这个 Colab notebook 里:
Colab:
Colab 为你做了什么:
- 在 Colab 内启动 n8n,进行临时设置
- 通过 Cloudflare Tunnel 将其暴露到互联网上
- 通过 API 在 n8n 中创建 AWS、ES、Telegram 凭证
- 安装完整的工作流模板
- 设置 Elasticsearch:
- Bedrock 推理端点
- 带 semantic_text 的索引 mapping
- 提供批量写入工具,用于你的合成费用数据集
- 让你可以立即从 Telegram 开始与你的 bot 对话
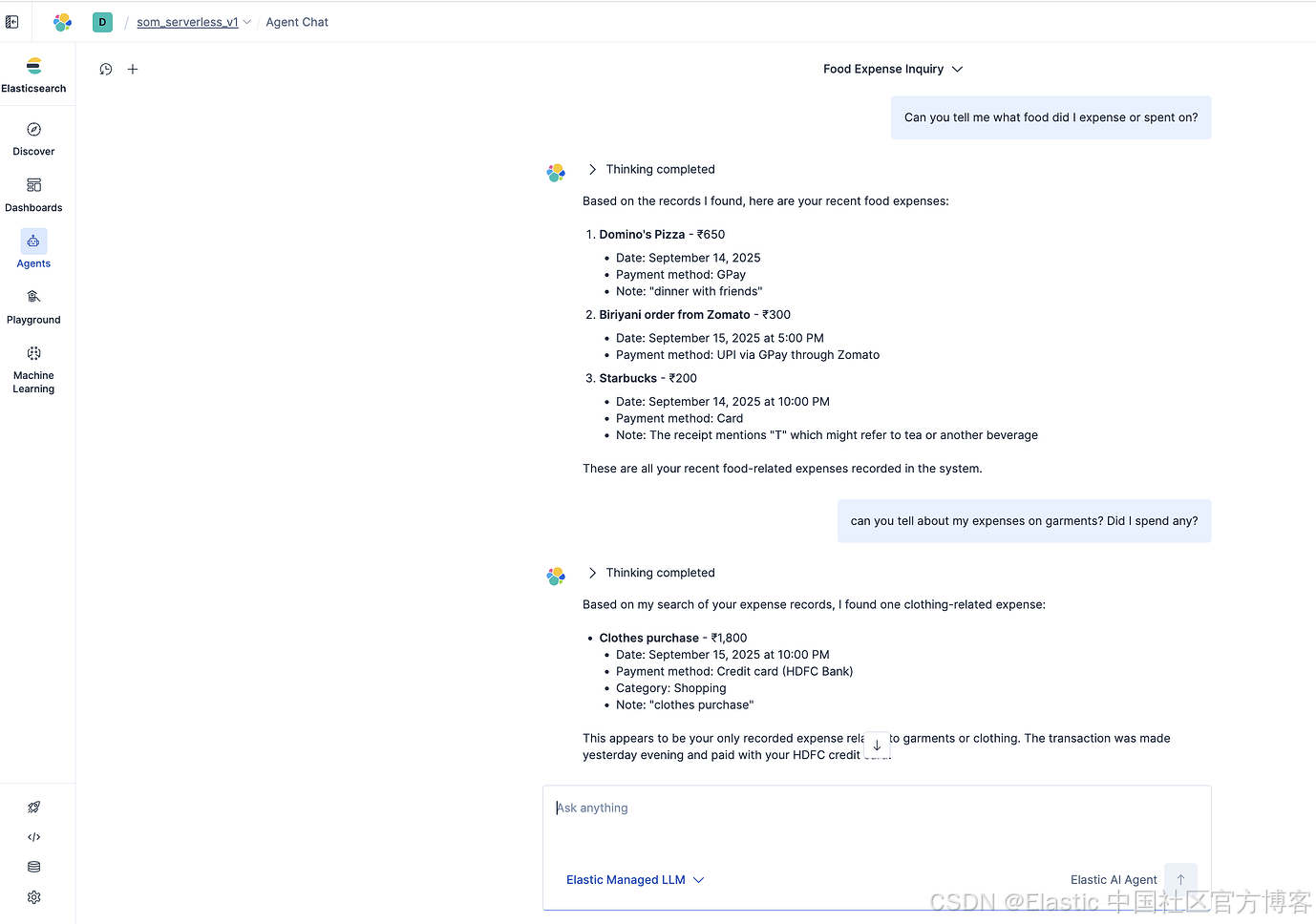
演示截图
- Telegram 对话

- Agent Builder(直接对话)
- Elastic Agent Builder YouTube 视频
总结
这个技术栈为你提供:
- 一个对话式个人理财助手
- 使用 Elastic Agent Builder 的完整语义 + 结构化搜索
- 来自聊天或语音的实时写入


















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









