






作者:来自 Elastic Julien_Martin

使用 n8n 和 Elastic Agent Builder 构建一个 AI 驱动的电子邮件钓鱼检测系统
钓鱼攻击仍然主导着网络安全威胁形势,攻击者越来越多地使用复杂的社会工程技术来绕过传统过滤器。作为一名使用 Elastic 技术的安全从业者,我构建了一个自动化的钓鱼检测与分析系统,将 n8n 工作流自动化与 Elastic 的 AI 驱动的 Agent Builder 相结合。本文将介绍该系统的架构、实现方式,以及对三个月内 44 封钓鱼邮件进行分析所获得的真实洞察。
为什么这种方法有效
传统的基于规则的电子邮件过滤器难以应对现代钓鱼活动,这些活动往往使用具有上下文语义的语言和看似合法的格式。通过利用 Elastic 推理管道中的大语言模型( LLMs ),我们可以分析电子邮件语义、提取恶意模式,并对威胁进行分类,准确率超过 95%。与 n8n 的集成实现了无缝自动化,而 Elastic Agent Builder 则使安全分析人员能够使用自然语言查询分析结果。
Elastic 入门:如果你是 Elastic 新用户,可以查看 Getting Started 指南来设置你的部署,并开始探索 Elastic 的搜索、可观测性和安全解决方案。
架构组件
n8n 工作流自动化
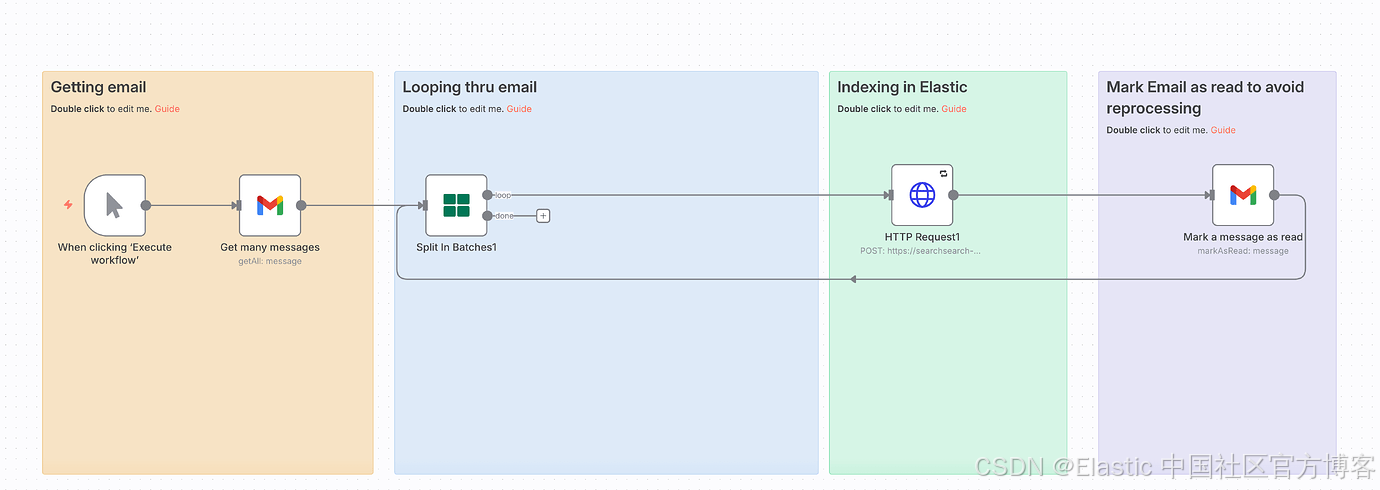
n8n 工作流在四个阶段中编排整个电子邮件处理流水线:
触发器节点在手动激活或按计划时启动执行。Gmail 节点(“Get many messages”)连接到你的 Gmail 账号,并通过 Gmail API 检索未读邮件。Split in Batches 节点以可配置的批大小(通常为 10–50)处理邮件,以优化吞吐量并防止 API 限流。HTTP Request 节点通过 POST 请求将每封邮件发送到 Elasticsearch 的 ingest pipeline 端点(https://[your-cluster]:9200/fishfish/_doc?pipeline=phishingornotphishing)。
在成功索引后,工作流会在 Gmail 中将邮件标记为已读,以防止重复处理。这种模块化设计遵循 n8n 最佳实践,通过分离关注点并允许每个组件独立测试。
你可以在这里找到 n8n 模板
Elasticsearch Ingest Pipeline
在配置 ingest pipeline 之前,你必须先设置一个连接到你的 AI 模型的 inference endpoint。Elastic 通过提供一个统一的 API 来简化这一过程,用于管理 inference 服务,无论你使用的是内置模型、Azure OpenAI、OpenAI、Cohere、Google AI、Anthropic,还是其他提供商。
要创建一个 inference endpoint,请使用 Elasticsearch API 来注册你的服务配置。对于 Azure OpenAI,endpoint 配置如下:
PUT _inference/completion/azure_openai_completion
{
"service": "azureopenai",
"service_settings": {
"resource_name": "test-ai",
"deployment_id": "gpt-4",
"api_version": "2024-02-01",
"api_key": "replacehere"
}
}一旦注册完成,inference endpoint 就可以在整个 Elasticsearch 集群中使用。你可以在 ingest pipelines、search queries,或任何需要 AI inference 的 Elasticsearch 操作中引用它。这种集中式的方法避免了在多个地方管理 API 凭证和连接细节 —— Elastic 会透明地处理认证、限流和错误处理。
使用语义搜索字段的索引映射
在摄取数据之前,你必须先定义一个索引映射,用来指定哪些字段支持语义搜索。Elastic 通过 semantic_text 字段类型简化了这一过程,它会在摄取时自动处理 embedding 生成和 inference。与需要手动配置 pipeline 的传统 vector 字段不同,semantic_text 字段提供了合理的默认配置,避免了复杂的 inference pipeline 设置。
在 fishfish 索引中,像 content.semantic 和 subject.semantic 这样的关键字段被配置为 semantic_text 字段,从而启用语义搜索能力。这些字段在文档索引时,会自动使用指定的 inference endpoint(本例中是 .multilingual-e5-small-elasticsearch,用于多语言文本 embedding)生成 embeddings。映射配置如下:
{
"fishfish": {
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"content": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"date": {
"type": "date"
},
"extracted_data": {
"properties": {
"category": {
"type": "keyword"
},
"date": {
"type": "date"
},
"reasoning": {
"type": "text"
},
"urls": {
"type": "text"
}
}
},
"from": {
"type": "keyword"
},
"model_id": {
"type": "keyword"
},
"output": {
"type": "text"
},
"reasoning": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"requirements_prompt": {
"type": "text"
},
"subject": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
}使用 semantic_text 字段时,Elastic 会在摄取阶段自动生成 embeddings,而不需要显式配置 inference pipeline processor。这意味着索引到 fishfish 索引中的文档,会自动为 content.semantic、subject.semantic 和 reasoning.semantic 字段创建语义 embeddings,从而支持理解语义和上下文的语义搜索查询,而不仅仅是精确的关键词匹配。
随后,phishingornotphishing ingest pipeline 会使用预先配置好的 Azure OpenAI completion model 来执行智能分类:
PUT _ingest/pipeline/phishingornotphishing
{
"description": "Categorize email in 3 categories: valid,marketing,phishing",
"processors": [
{
"set": {
"field": "requirements_prompt",
"value": """
You are a cybersecurity analyst. Extract and categorize the following email data. Return ONLY valid JSON with no additional text.
Input data:
- Content: {{content}}
- Subject: {{subject}}
- Authors: {{from}}
- Date: {{date}}
Requirements:
1. Set the date field to ISO8601 format
2. Extract all URLs from the Content field. Extract it from HTLM code if needed
3. Categorize the email as one of: "valid", "marketing", or "phishing" based on Content, Subject, and authors
4. Explaing your reasoning
5. Return JSON with these fields: date, urls, category
JSON format:
{
"date": "ISO8601_date_here",
"urls": ["url1", "url2"],
"category": "valid|marketing|phishing",
"reasoning": "reasoning_here"
}
""",
"ignore_failure": true
}
},
{
"inference": {
"model_id": "azure_openai_completion",
"input_output": [
{
"input_field": "requirements_prompt",
"output_field": "output"
}
]
}
},
{
"json": {
"field": "output",
"target_field": "extracted_data",
"ignore_failure": false
}
},
{
"set": {
"field": "category",
"value": "{{extracted_data.category}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "timestamp",
"value": "{{extracted_data.date}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "urls",
"copy_from": "{{extracted_data.urls}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "reasoning",
"copy_from": "{{extracted_data.reasoning}}",
"ignore_empty_value": true,
"ignore_failure": true
}
}
]
}set processor 构建了一个详细的 prompt,指示 LLM 充当一名网络安全分析师。它将邮件元数据(内容、主题、发件人、日期)作为上下文变量包含在内。inference processor 调用 Azure OpenAI model,对邮件进行语义分析,以检测诸如紧急语气、可疑 URL 以及社会工程手段等钓鱼特征。AI 会从纯文本和 HTML 标记中提取 URL,将日期规范化为 ISO8601 格式,分配分类(valid / marketing / phishing),并给出人类可读的分析原因。最后,json processor 解析 AI 的响应,并将字段映射为可搜索的文档属性。这种语义方法通过理解上下文、意图以及钓鱼活动中使用的语言模式,优于基于关键词的过滤方式。
Elastic Agent Builder 配置
了解更多:有关详细的设置说明和配置选项,请参阅 Elastic Agent Builder Get Started 指南。
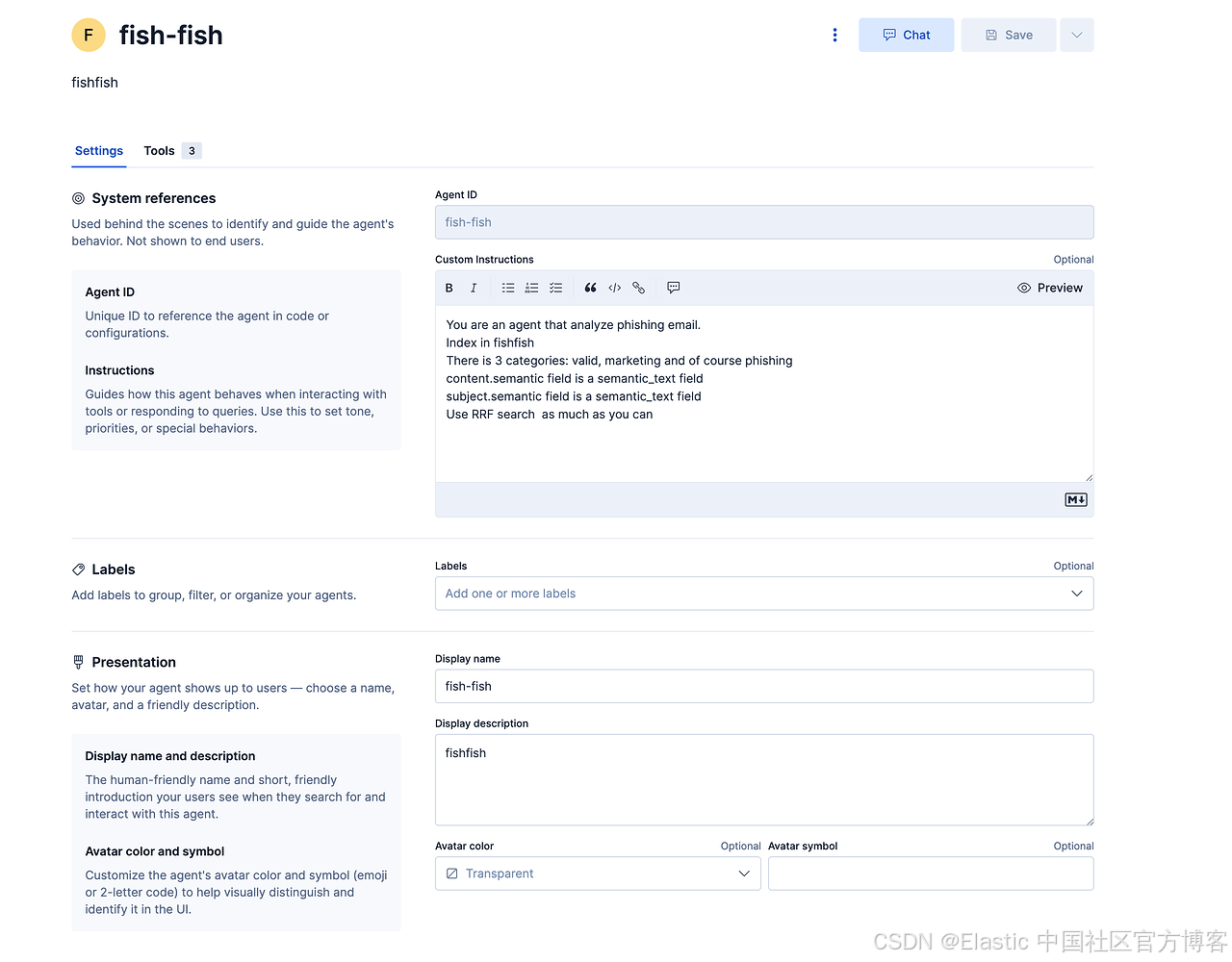
“fish-fish” agent 为安全分析师提供了一个交互式界面,可通过对话方式查询钓鱼邮件数据:
系统指令定义了 agent 的角色:“你是一个分析钓鱼邮件的 agent。索引在 fishfish 中。有 3 个类别:valid、marketing 以及 phishing。content.semantic 字段是 semantic_text 字段,subject.semantic 字段是 semantic_text 字段。尽可能使用 RRF 搜索。”
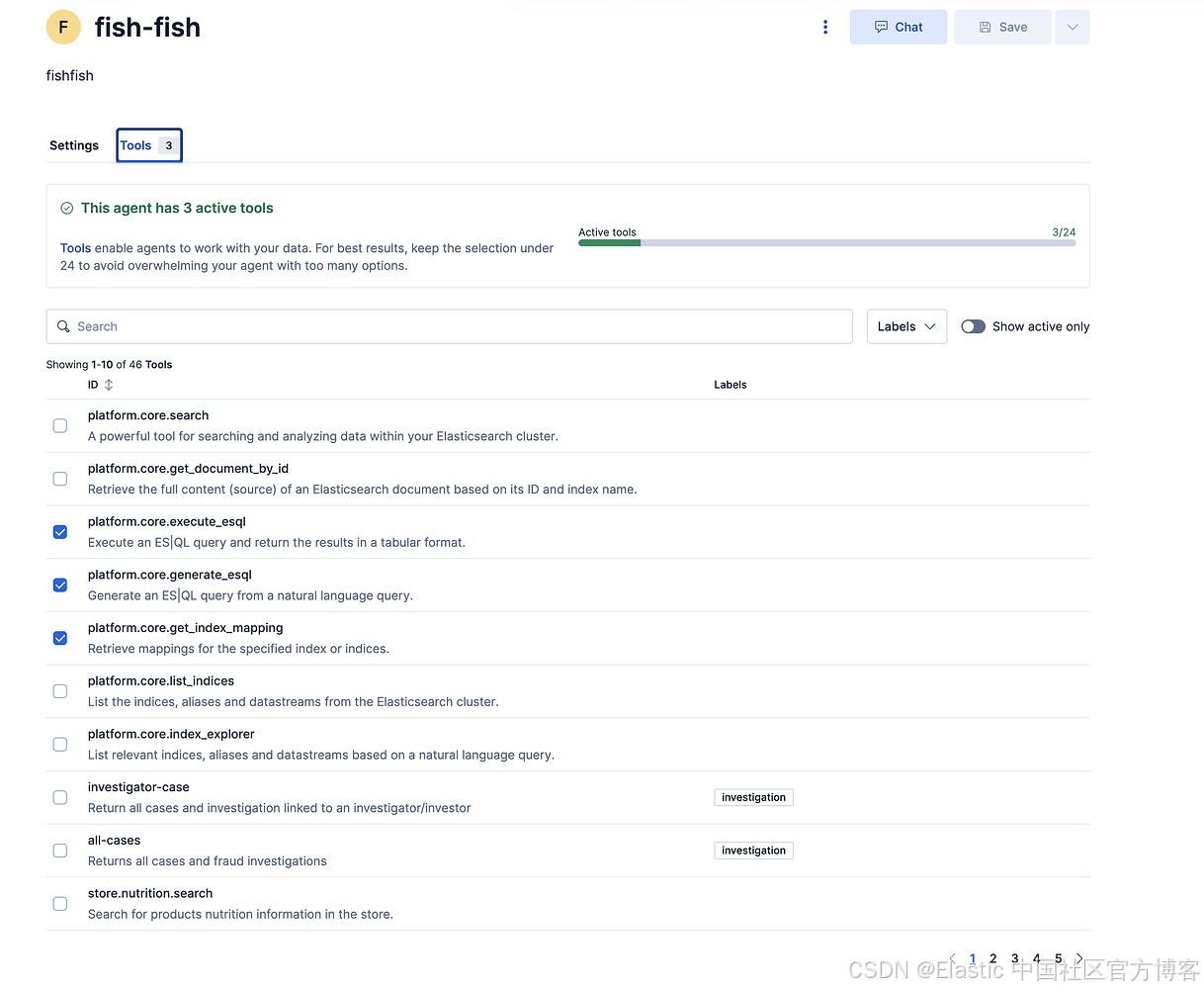
该 agent 可访问三个平台工具:
-
platform.core.execute_esql:对 fishfish 索引执行 ES|QL 查询
-
platform.core.generate_esql:将自然语言问题转换为 ES|QL 语法
-
platform.core.get_index_mapping:获取索引结构和字段类型
语义搜索字段(content.semantic 和 subject.semantic)支持向量相似度搜索,可查找概念上相关的邮件,而不仅仅是精确关键词匹配。这些字段在索引映射中配置为 semantic_text 类型,在文档摄取时会自动生成嵌入向量。Agent 使用 倒数排序融合(RRF) 将来自多种搜索策略的结果合并,提高搜索准确性。
内置集成服务器
Elastic Agent Builder 包含两个内置集成服务器,实现与外部 AI 客户端及 agent-to-agent 通信的无缝连接:
-
Model Context Protocol (MCP) Server:为外部客户端访问 Elastic Agent Builder 工具提供标准化接口。MCP 服务器位于
{KIBANA_URL}/api/agent_builder/mcp,允许如 Claude Desktop、Cursor 和 VS Code 扩展等 AI 客户端通过 JSON-RPC 2.0 与 Elastic 工具交互。连接时,配置客户端使用 Kibana URL 和包含read_onechat与space_read权限的 API Key,即可让安全分析师直接在熟悉的 AI 开发环境中查询钓鱼邮件数据,无需在不同工具间切换。 -
Agent-to-Agent (A2A) Server:支持基于 A2A 协议规范的 agent-to-agent 通信,为外部 A2A 客户端提供与 Elastic Agent Builder agent 交互的接口。
-
Agent Card endpoint (
GET /api/agent_builder/a2a/{agentId}.json):返回指定 agent 的元数据 -
A2A Protocol endpoint (
POST /api/agent_builder/a2a/{agentId}):处理 agent 之间的交互
两个接口均需要 API Key 认证,确保分布式安全 agent 之间的通信安全。
-
这些内置服务器消除了自定义集成代码的需求,使组织能够通过 Elastic Agent Builder 将钓鱼检测系统扩展至其他 AI 驱动的安全工具、工作流自动化平台和多 agent 系统,从而实现自动威胁情报共享、跨平台安全编排及分布式 agent 协作等高级用例。
真实世界的分析与洞察

在三个月内处理了 44 封钓鱼邮件后,系统揭示了关键的攻击模式和趋势。
攻击模式分析
免费礼品/奖品诈骗占所有钓鱼尝试的 40%。这些邮件使用法语主题行,如 "Récupérez votre cadeau"(领取你的礼物)和 "Vous avez gagné..."(你已获奖…)。常见诱饵包括 Parkside/Lidl 工具套装、Lancôme 美妆盒、Silvercrest 家电、Tefal 厨房用品、iPhone 17 Pro Max 和 RYOBI 工具包。攻击通过声称数量有限或优惠即将到期来制造紧迫感。
包裹派送诈骗占钓鱼邮件的 30%。这些邮件的主题行如 "Vous avez (1) colis en attente de livraison"(你有一个待派送的包裹)。策略包括声称包裹被暂停、要求支付未付关税、要求立即操作以“安排派送”,以及使用假追踪码以显示合法性。
订单确认诈骗占 15%。这些邮件发送假订单确认,包含订单号如 "commande n°[48754-13] confirmée"。它们通过引起对未购买商品的混淆,并催促快速核实订单来制造紧迫感。
账户验证诈骗占 10%。这些邮件使用主题行如 "Vérification KYC" 或 "Important: Confirmez votre compte"。它们要求立即验证账户,并威胁若未完成则暂停账户。
类别分布
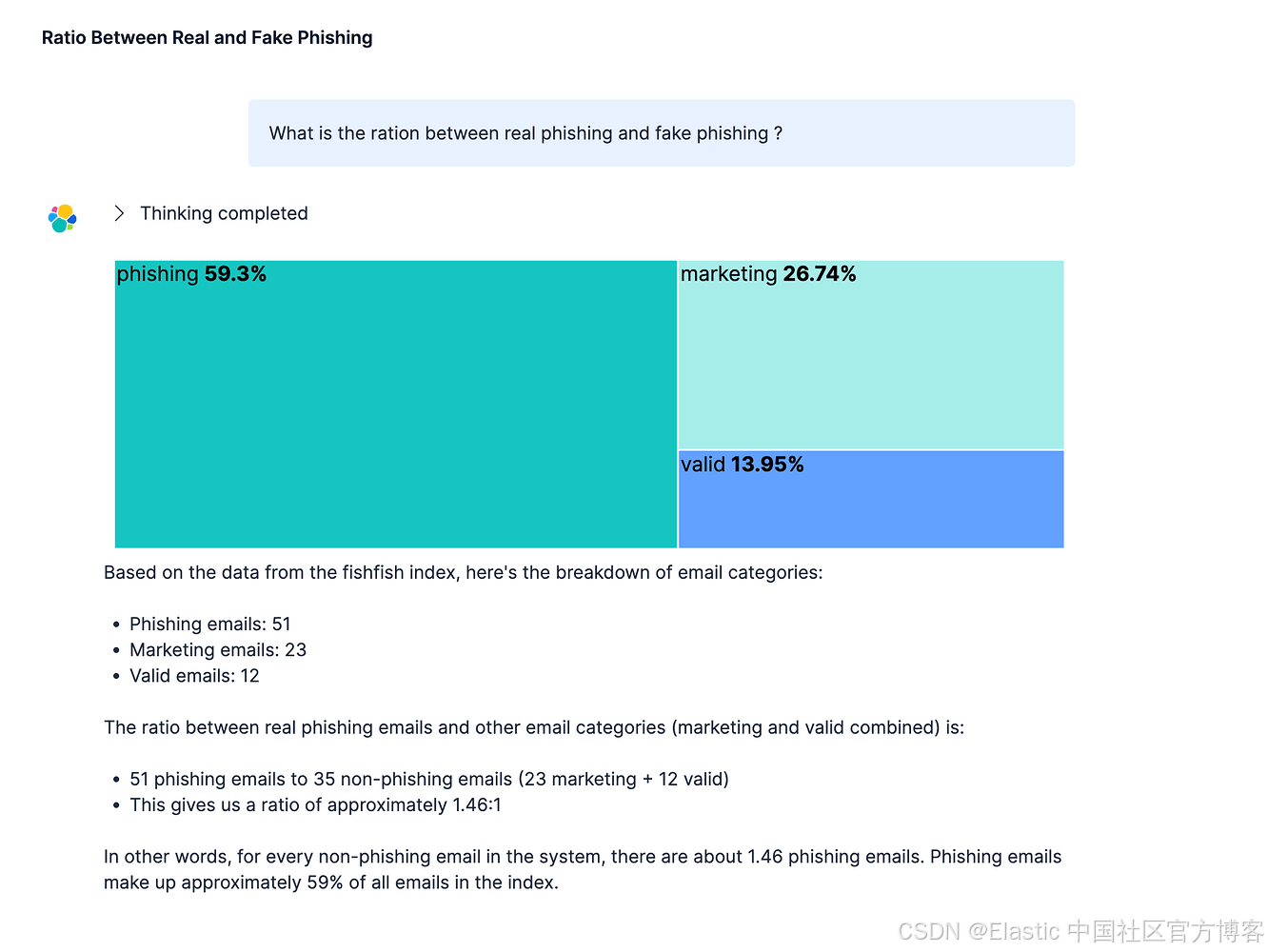
Agent Builder 查询 “What is the ration between real phishing and fake phishing?” 显示了整体邮件组成:
钓鱼邮件:51 封(59.3%),被识别为需要立即处理的恶意威胁。
营销邮件:23 封(26.74%),合法的促销内容但可能不受欢迎。
有效邮件:12 封(13.95%),来自可信来源的真实通信。
1.46:1 的钓鱼邮件与合法邮件比例显示了威胁环境的严重性。每封合法邮件,系统大约检测到 1.46 次钓鱼尝试。
结论
n8n、Elasticsearch 与 AI 驱动分析的集成创建了一个强大的钓鱼检测管道,能够实时处理邮件,通过语义理解对威胁进行分类,并通过会话查询提供可操作的情报。系统的模块化设计允许每个组件独立优化,同时保持端到端自动化。
实施类似架构的组织可以通过自动分流减少事件响应时间,通过语义分析降低误报率,更好地了解攻击模式和趋势,并通过自动化日常分类任务减轻分析师的工作负担。随着钓鱼攻击不断演进,将工作流自动化与 AI 推理结合提供了一种可扩展、可维护的邮件安全方法,可适应新兴威胁。
原文:https://discuss.elastic.co/t/dec-11th-2025-en-building-an-ai-powered-email-phishing-detection/383298


















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









