






作者:来自 Elastic Bret Wortman
学习如何在 Elasticsearch 中利用 Deepfreeze 来自动化 searchable snapshot 存储库轮转,在索引删除后保留历史数据,并将其老化到成本更低的 S3 Glacier 层级。
测试 Elastic 领先的、开箱即用的能力。深入了解我们的示例 notebooks,开始免费的 cloud 试用,或现在就在你的本地机器上试用 Elastic。
问题:你的旧数据很昂贵(而且越来越贵)
随着法律要求的变化以及数据保留周期的延长,许多 Elasticsearch 客户开始思考:我如何在不让存储成本失控的情况下保留历史数据?
你的 ILM 策略运行得很好。新数据以 hot 形式进入,随着时间推移进入 warm 或 cold,被冻结为 searchable snapshot,最终 —— 在 180 天、10 年或更长时间之后,取决于你的合规要求 —— 被删除。
当 delete 操作运行时,通常也会一并删除 searchable snapshot。当然,你可能在其他地方有常规 snapshots,但如果不进行完整恢复,它们是不可搜索的。如果有人在六个月后来找你问:“嘿,我们能看看 Q2 2023 发生了什么吗?”你面对的可能是一次漫长的恢复操作、一次手动且耗时的重新摄取,或者一场关于数据保留策略的尴尬对话。
最显而易见的解决方案就是……不删除,对吧?永远保留这些 frozen 索引!但这也会带来新的问题:
- 成本膨胀:Frozen 层的存储并不是免费的,而且会不断累积
- 集群杂乱:管理成百上千个古老的 frozen 索引会变得很混乱
- 资源浪费:你在为“可搜索”的数据付费,但你已经好几个月没有搜索过它们了
你真正想要的是介于两者之间的方案:一种既能让数据保持可访问,又不会被 S3 存储成本拖垮的方法。
解决方案:Deepfreeze 让旧数据变得便宜(但不会消失)
Deepfreeze 是 Elastic 推出的一种新的存储库管理解决方案。它允许你为已删除的索引保留 searchable snapshots,将它们移动到更便宜的 S3 存储层级,并在需要再次使用已保存的数据时轻松恢复。这一切都源于 Elasticsearch 允许你在删除索引的同时保持其 searchable snapshot 完整。
当你配置 ILM 的 delete 操作时,在 delete 阶段有一个经常被忽略的选项:
{
"delete": {
"delete_searchable_snapshot": false
}
}将其设置为 false 后,当索引被删除时,snapshot 存储库会将 snapshot 文件保留在 S3 中。索引会从你的集群中消失(不再需要付费!),但底层数据仍然安静地存放在你的 S3 bucket 中,耐心等待。
但真正有意思的地方在这里:如果你只是把这些 snapshots 留在同一个存储库中,它们仍然会被 Elasticsearch“管理”,这意味着它们必须保留在标准访问层级。AWS S3 Intelligent-Tiering 不会将它们移动到更便宜的层级,因为从 S3 的角度来看,Elasticsearch 仍在主动管理这个 bucket。
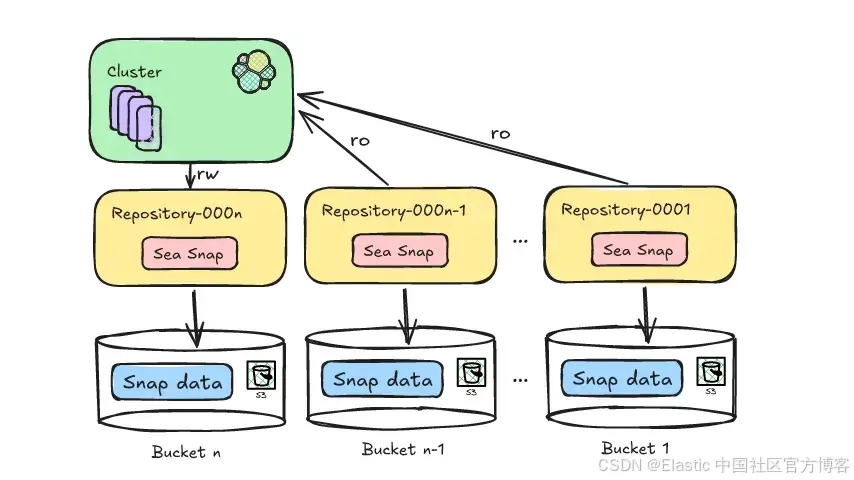
Deepfreeze 通过轮转 snapshot 存储库来解决这个问题。
可以这样理解:与其使用一个不断往里添加文件夹的大型文件柜,不如每个月启用一个新的文件柜。旧的文件柜会被关闭、贴上标签,并移到更便宜的存储中。如果你需要旧文件柜里的东西,随时都可以把它取出来再打开。
注意:Deepfreeze 目前支持 AWS。Azure 和 GCP 已在未来开发路线图中。
Deepfreeze 的工作原理:实现数据自由的四个步骤
Deepfreeze 是一个 Python 自动化工具,定期运行(通常通过 cron)来管理这一轮转过程。当你执行它的每月 rotate 操作时,会发生以下事情:
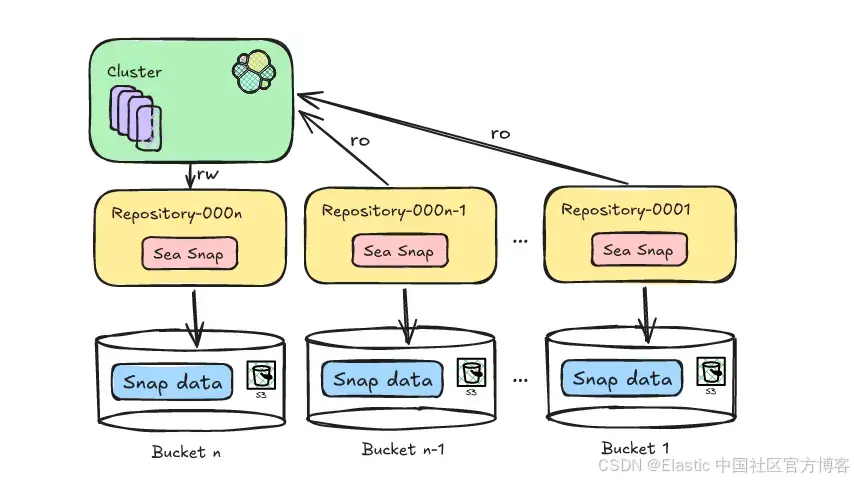
步骤 1:创建一个新的 S3 bucket
Deepfreeze 会创建一个全新的 S3 bucket,使用递增命名(例如 Repository-000002)。该 bucket 会配置为你首选的存储类别 —— 默认是 Standard,也可以选择 Intelligent Tiering。
请注意,我在这里使用“bucket”一词是为了便于讨论。实际上,Deepfreeze 会在一个 bucket 内创建新的 base paths,以避免 AWS bucket 创建限制可能带来的问题。为了简单起见,我将 bucket 和路径的组合统称为 bucket。
步骤 2:将 bucket 挂载为 Elasticsearch 存储库
新的 S3 bucket 会在你的 Elasticsearch 集群中注册为 snapshot 存储库。你的 ILM 策略现在将开始使用这个存储库来存放新的 frozen 索引。
步骤 3:更新 ILM 策略以使用新存储库
这里是关键步骤。Deepfreeze 会自动:
- 扫描你所有的 ILM 策略
- 找到 searchable_snapshot 操作中对旧存储库的引用
- 将 ILM 策略复制为引用新存储库的新策略
- 更新索引模板以使用这些新策略
你无需手动编辑几十个策略,Deepfreeze 会处理一切。
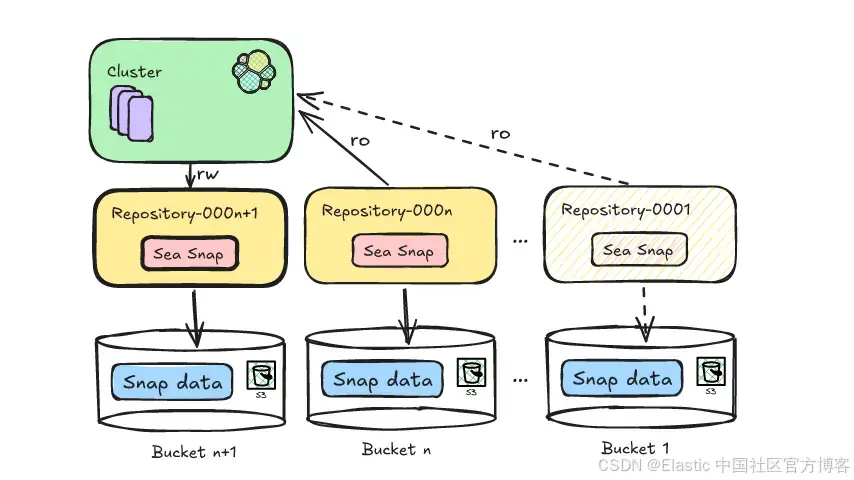
步骤 4:卸载旧存储库(但保留最近的)
Deepfreeze 保持一个挂载存储库的滑动窗口 —— 默认保留最近 6 个月可访问。较旧的存储库会从 Elasticsearch 中卸载,但 S3 bucket 仍保持完整。
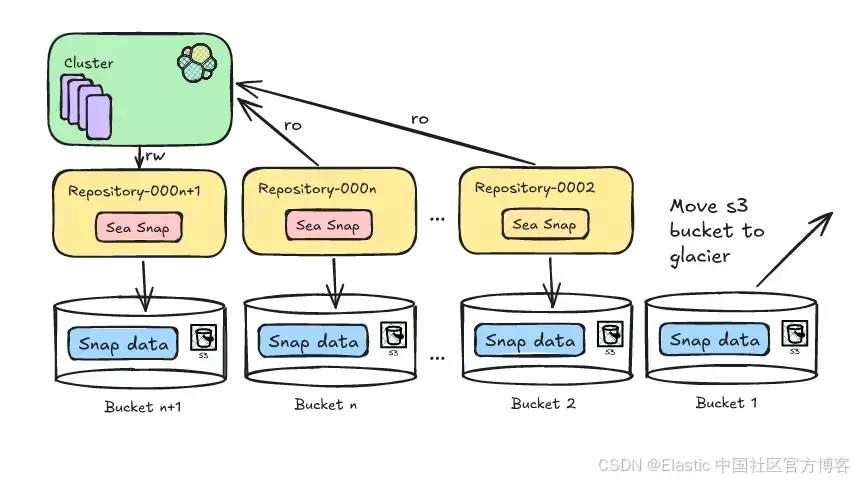
一旦卸载,这些 bucket 不再处于 Elasticsearch 的主动管理之下,Deepfreeze 现在可以将它们移动到 Glacier。
好处:为什么你应该关心
成本优化
Elasticsearch 的 frozen 层存储比 hot 或 warm 存储便宜,但仍会产生标准 S3 存储费用。S3 Glacier 层的成本可以比标准 S3 存储低 95%。随着时间推移,这会累积成可观的开销。
无负担的数据保留
合规要求通常规定必须保留数据多年。Deepfreeze 让你在满足这些要求的同时,不必不断向财务解释存储账单为什么一直在增长。
需要时快速访问
由于 searchable snapshots 仍保持其原生格式,你可以使用 Elasticsearch 的标准 _mount API 重新挂载它们。无需漫长的恢复过程,无需重新格式化 —— 只需指向旧存储库并挂载索引。
Deepfreeze 让这一切更简单,通过跟踪它处理的每个存储库的日期时间范围,实现类似这样的操作:系统通过从 S3 请求 bucket、在数据可用时挂载存储库,甚至挂载覆盖指定日期的索引,完成所有解冻数据的工作。
$ deepfreeze thaw --start-date 2024-10-12 --end-date 2024-12-01在指定时间(默认 30 天)过后,AWS 会自动将数据重新冻结到 Glacier。Deepfreeze 会在正常操作中检查这一点,并更新其元数据、存储库和索引。
(AWS 并不会真正将数据从 Glacier 移回 Standard,而是将所需数据复制回 Standard,然后在时间到期后删除它。)
完全自动化
按计划运行 Deepfreeze(每月的第一天适合每月轮转),然后忘掉它。它会自动处理所有繁琐的策略更新、bucket 创建和存储库管理。可通过 cron 或 .service 文件运行。GitHub 上提供了示例。
减少集群杂乱
你的 Elasticsearch 集群只需跟踪正在挂载的存储库。古老索引不会出现在你的集群状态、监控仪表板或备份流程中。一切保持更整洁。
配置:让 Deepfreeze 为你工作
Deepfreeze 非常灵活。你可以通过环境变量、命令行参数或两者结合进行配置。例如,你可以通过设置 DEEPFREEZE_KEEP 环境变量来更改默认挂载存储库数量。默认值为 6。增加该值可以访问更多数据。
DEEPFREEZE_KEEP=10DEEPFREEZE_KEEP 的理想设置取决于你需要访问旧数据的可能性。如果你很少查看超过一年的数据,可以将 keep 值设置为 12,以确保你的集群拥有完整一年的数据;Deepfreeze 会将更早的数据推送到 Glacier 存储。
你还可以更改 AWS Storage Class,使用 intelligent_tiering(基于访问的自动分层)代替默认的 standard(全价、始终可访问):
DEEPFREEZE_STORAGE_CLASS=intelligent_tiering每个操作的选项都在 GitHub README 中。
实际使用案例
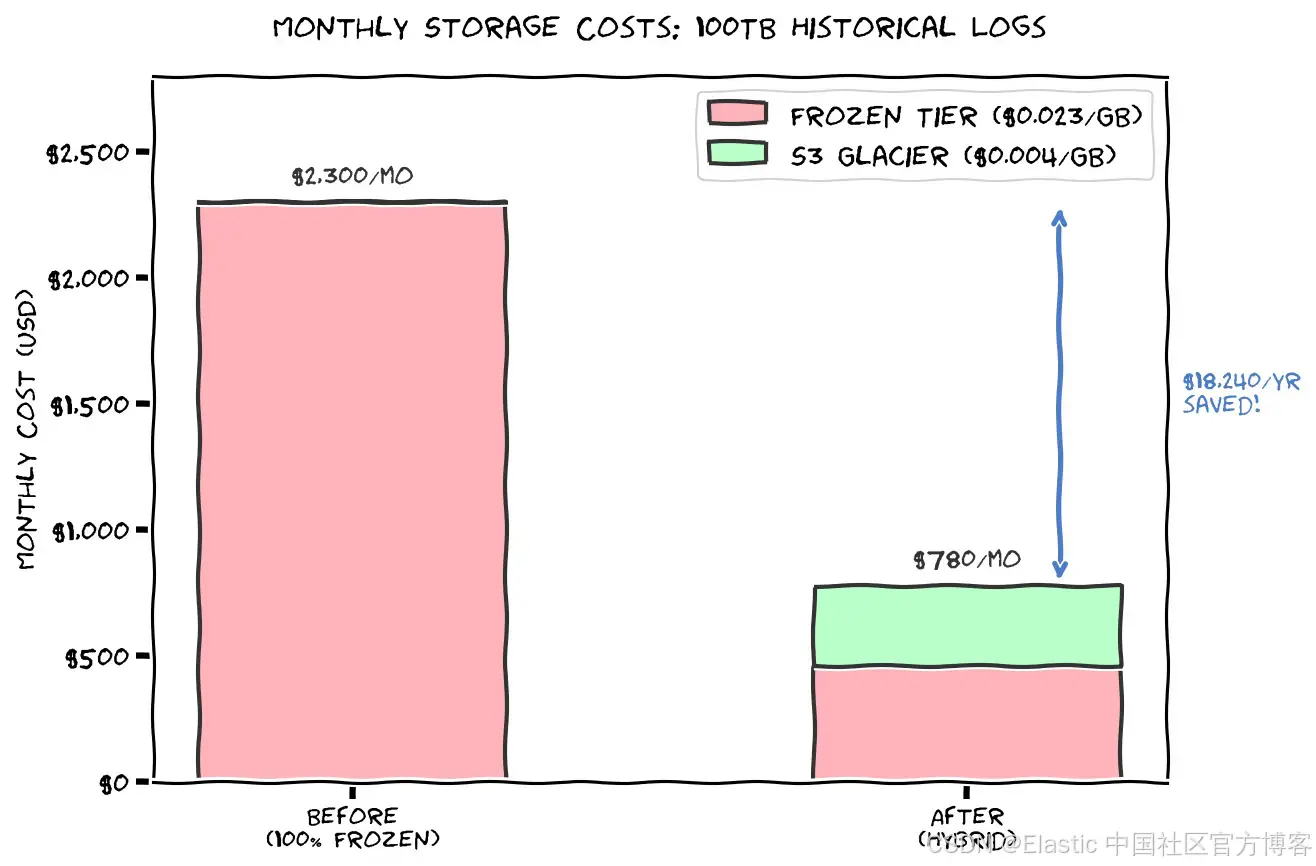
无论你是要摄取 application logs、安全事件、IoT 传感器数据,还是完全不同的数据,成本节省取决于你的摄取速率和保留周期。
例如,如果你每天摄取 175GB 的 application logs,但通常只需要最近 6 个月的数据可搜索以进行故障排除。假设合规要求保留 7 年:
没有 Deepfreeze:
- 保留 7 年 × 60TB = 420TB 在 frozen 层
- 成本:约 $9,660/月
使用 Deepfreeze:
- 保留 6 个月 × 30TB = 30TB 在 frozen 层:$690/月
- 保留 6.5 年 × 390TB 在 S3 Archive:$1,560/月
- 总计:$2,250/月(节省 77%)
技术深度解析:幕后机制
对于想了解实际发生了什么的人,这里展示 Deepfreeze 的实现流程。
Deepfreeze 流程图
START
│
├─► Initialize Elasticsearch client (SSL/TLS, auth)
│
├─► Calculate next repository suffix
│
├─► Validate: At least one existing repo with prefix exists
│
├─► Validate: New repo name doesn't already exist
│
├─► Create new S3 bucket path via boto3
│ └─► Configure: storage class, ACL, region
│
├─► Register new repository in Elasticsearch
│ └─► Type: s3
│ └─► Settings: bucket, base_path, storage_class
│
├─► Update all ILM policies
│ ├─► Fetch all policies from cluster
│ ├─► For each policy using the last repo:
│ │ └─► Find searchable_snapshot actions
│ │ └─► Replace old repo name with new
│ │ └─► Submit updated policy
│ └─► Log policy update count
│
├─► Unmount old repositories
│ ├─► List all repos matching prefix
│ ├─► Exclude any thawed repos from consideration
│ ├─► Sort by suffix (oldest first)
│ ├─► While (total count > KEEP):
│ │ └─► DELETE oldest repository (S3 bucket stays!)
│ └─► Log unmounted repo count
│
END关键实现细节
智能存储库发现:该工具通过前缀匹配发现存储库,确保只管理它创建的存储库:
def get_repos(self) -> list:
"""Get all repositories matching our prefix"""
all_repos = self.client.snapshot.get_repository(name='*')
return [r for r in all_repos if r.startswith(self.repo_name_prefix)]自动 ILM 策略更新:无需手动编辑策略。Deepfreeze 会遍历策略结构并更新存储库引用:
# Simplified conceptual example
for policy_name, policy in ilm_policies.items():
for phase in policy['phases']:
if 'searchable_snapshot' in phase['actions']:
phase['actions']['searchable_snapshot']['snapshot_repository'] = new_repo
es.ilm.put_policy(name=policy_name, policy=policy)重要注意事项
S3 Intelligent-Tiering 问题
这里有一个值得讨论的架构问题:AWS S3 Intelligent-Tiering 如何对未挂载的 searchable snapshots 分类?
其原理是,一旦从 Elasticsearch 卸载,S3 bucket 不再被主动管理,因此访问模式降为零,Intelligent-Tiering 应该会将数据通过 Archive Access 层逐步移动到 Deep Archive Access(甚至 Glacier Instant Retrieval)。
由于这依赖于数据至少 90 天不被访问且保持不变,Deepfreeze 默认将存储库放在 Standard 中,并在卸载后立即移动到 Glacier,而不是等待 IT 决定时间。我们确保数据尽快移动到 Glacier,但不会提前。
初始设置要求
在运行 Deepfreeze 之前,你需要:
1)配置 ILM 策略以保留 searchable snapshots:
"delete": {
"delete_searchable_snapshot": false
}2)至少一个使用你选择的前缀的现有存储库(deepfreeze 会验证这一点)
3)配置用于 S3 访问的 AWS 凭证(通过环境变量、IAM 角色或凭证文件)
4)Elasticsearch 身份验证,具有管理存储库和 ILM 策略的权限
setup 命令会运行一系列全面的预检查,以确保在开始之前条件正确。
设置后任务
Deepfreeze 只是创建用于管理存储库的环境;它不会帮助你的数据进入这些存储库。我们不了解你的业务,也不知道你希望保留哪些数据。在 Deepfreeze 设置完成后,确保至少有一个 ILM 策略使用该存储库且禁用 snapshot 删除。你还需要确保有一个索引模板,将该 ILM 策略与希望保留的索引或数据流关联。
快速开始
安装
# Clone the repository
git clone https://github.com/elastic/deepfreeze.git
cd deepfreeze
# Install in development mode
pip install -e .
# Or install dependencies directly
pip install -r requirements.txt基本用法
# Set up environment variables (or use .env file)
export DEEPFREEZE_ELASTICSEARCH=https://es.example.com:9200
export DEEPFREEZE_CA=/path/to/http_ca.crt # For self-signed certificates
export DEEPFREEZE_USERNAME=elastic
export DEEPFREEZE_KEEP=6
# Use a config.yml file instead
cp /path/to/deepfreeze/packages/deepfreeze-cli/config.yml.example ~/.deepfreeze/config.yml
# ...and then edit to set your values
# Run deepfreeze setup
deepfreeze setup
# With command-line options
deepfreeze setup --repo_name_prefix dftest \
--bucket_name_prefix myorg_dftest \
--base_path_prefix df_snapshots推荐工作流程
- 从小开始:先在单个索引或低优先级数据上测试
- 监控成本:在最初几个月关注 AWS 账单以验证节省效果
- 验证分层:如果选择 Intelligent-Tiering,检查 S3 指标以确保其按预期工作
- 逐步自动化:一旦有信心,将其添加到 cron 并扩展到更多索引
结论
Deepfreeze 解决了许多 Elasticsearch 操作人员面临的实际问题:如何在不破产的情况下保持历史数据可访问?
通过自动化 snapshot 存储库轮转,并利用 AWS S3 的原生分层功能,你可以获得:
- ✅ 长期数据保留的巨大成本节省
- ✅ 完全符合数据保留政策
- ✅ 快速访问最近的历史数据(默认 6 个月)
- ✅ 按需重新挂载旧数据
- ✅ 干净、自动化的工作流程,自行运行
Deepfreeze 与现有 ILM 策略兼容,配置要求极少。它不是对整个数据管理策略的重新设计,而是一种几乎能立即收回成本的优化。
从 Glacier 检索数据会产生费用,并且需要时间(截至本文撰写时,Standard 检索约需 6 小时)。如果你预计需要频繁访问历史数据,Deepfreeze 可能不太适合,此时将数据保留在 frozen 层可能是更好的解决方案。
如果你在大规模运行 Elasticsearch 并存储几个月以上的历史数据,Deepfreeze 值得认真考虑。你的 CFO 会感谢你,而且你会睡得更踏实,因为你仍然可以满足六个月前的审计请求。
资源与下一步
- 存储库:github.com/elastic/deepfreeze
- 文档:查看存储库中的 /README.md 和 docs/ 目录
- 依赖项:Python 3.8+,以及 pyproject.toml 中描述的其他依赖
有问题或想分享你的 deepfreeze 成功案例?在 GitHub 上打开 issue 或联系相关人员!
原文:https://www.elastic.co/search-labs/blog/s3-glacier-archiving-elasticsearch-deepfreeze


















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









