







作者:来自 Elastic Tyler Perkins, Kostas Krikellas 及 Julian Kiryakov
探索 Elasticsearch 9.2 中对 ES|QL 的三个独立更新:增强的 LOOKUP JOIN 用于更具表现力的数据关联、新的 TS 命令用于时间序列分析,以及灵活的 INLINE STATS 命令用于聚合。
动手体验 Elasticsearch:深入我们的示例 notebooks,开始免费云试用,或在本地机器上试用 Elastic。
Elasticsearch 9.2 于十月发布,包含大量重要改进,使数据分析比以往更快、更灵活、也更容易使用。本次发布的核心是对 ES|QL(我们的管道查询语言)的重要增强,旨在为终端用户直接带来更多价值。
以下是 Elasticsearch 9.2 中能通过 ES|QL 改变你数据分析工作流的功能。
革新数据关联:更智能、更快、更灵活的 Lookup Join
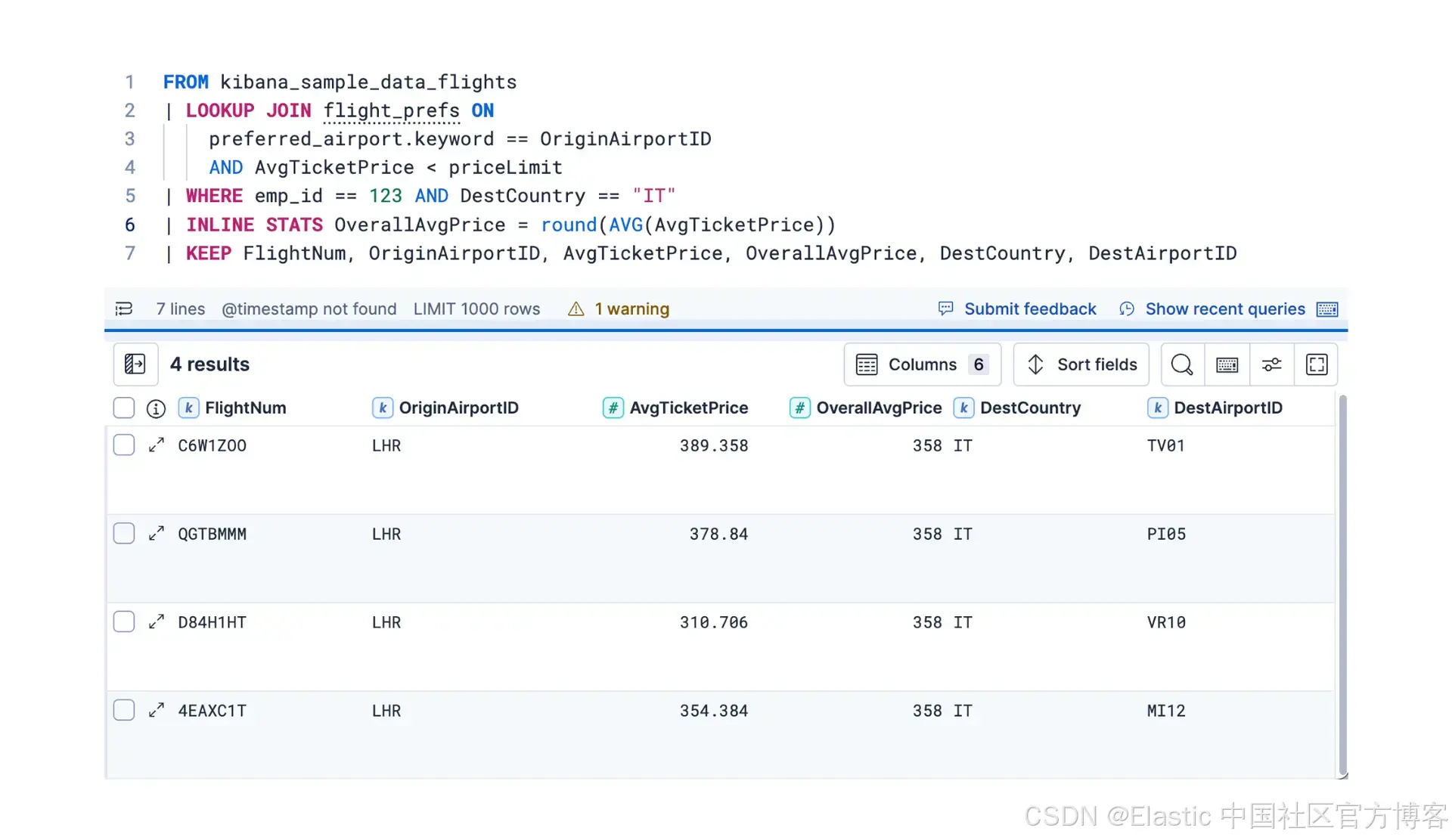
ES | QL 中的 LOOKUP JOIN 命令在 Elasticsearch 9.2 中经历了重大变革,变得更加高效和多功能。LOOKUP JOIN 将 ES | QL 查询结果表与指定 lookup 模式索引中匹配的记录进行组合,根据连接字段中的匹配值,将 lookup 索引中的字段作为新列添加到结果表中。此前,数据连接仅限于单字段和简单等值匹配。但现在不再是这样了!这些增强让你可以轻松处理复杂的数据关联场景。
Lookup Join 的主要增强包括:
- 多字段连接:轻松在多个字段上进行连接。例如,将 application_logs 与 service_registry 按 service_name、environment 和 version 进行连接:
FROM application_logs
| LOOKUP JOIN service_registry ON service_name, environment, version- 使用表达式释放复杂连接谓词(技术预览):
你不再被限制于简单的等值匹配。LOOKUP JOIN 现在允许你为关联指定多个条件,并使用一系列二元运算符,包括 ==、!=、<、>、<= 和 >=。这意味着你可以创建非常细致的连接条件,从而能够对数据提出更加复杂的问题。
示例 1:查找带有每个服务 SLA 阈值的应用指标
FROM application_metrics
| LOOKUP JOIN sla_thresholds
ON service_name == sla_service AND response_time > sla_response_time示例 2:此查询根据随时间变化的区域定价策略计算应付金额。它基于复杂的日期范围和等值条件连接三个数据集,以计算最终的 due_amount。第二个 lookup join 使用 meter_readings 索引中的 measurement_date 字段和 customers 索引中的 region_id 字段连接到 pricing_policies 索引,以找到特定区域和 measurement_date 对应的正确定价策略。
FROM meter_readings
| LOOKUP JOIN customers
ON meter_id
| LOOKUP JOIN pricing_policies
ON
region_id == region AND
measurement_date >= policy_begin_date AND
measurement_date < policy_end_date
| EVAL due_amount = (kwh_consumed * rate_per_kwh + base_charge) * (1 + tax_rate)
| EVAL period = policy_name
| KEEP customer_name, period, due_amount, measurement_date, kwh_consumed,
rate_per_kwh, base_charge, tax_rate
| SORT measurement_date- 过滤连接的巨大性能提升:
我们改进了使用 lookup 表条件进行过滤的 “扩展连接” 性能。扩展连接会为每一行输入生成多个匹配结果,可能会产生非常大的中间结果集。如果随后又有过滤条件丢弃其中的许多行,情况会更糟。在 9.2 中,我们通过在对 lookup 数据应用过滤时提前过滤掉不必要的行来优化这些连接,从而避免处理最终会被丢弃的行。在某些场景下,这类连接的速度甚至可以提升到原来的 1000 倍!
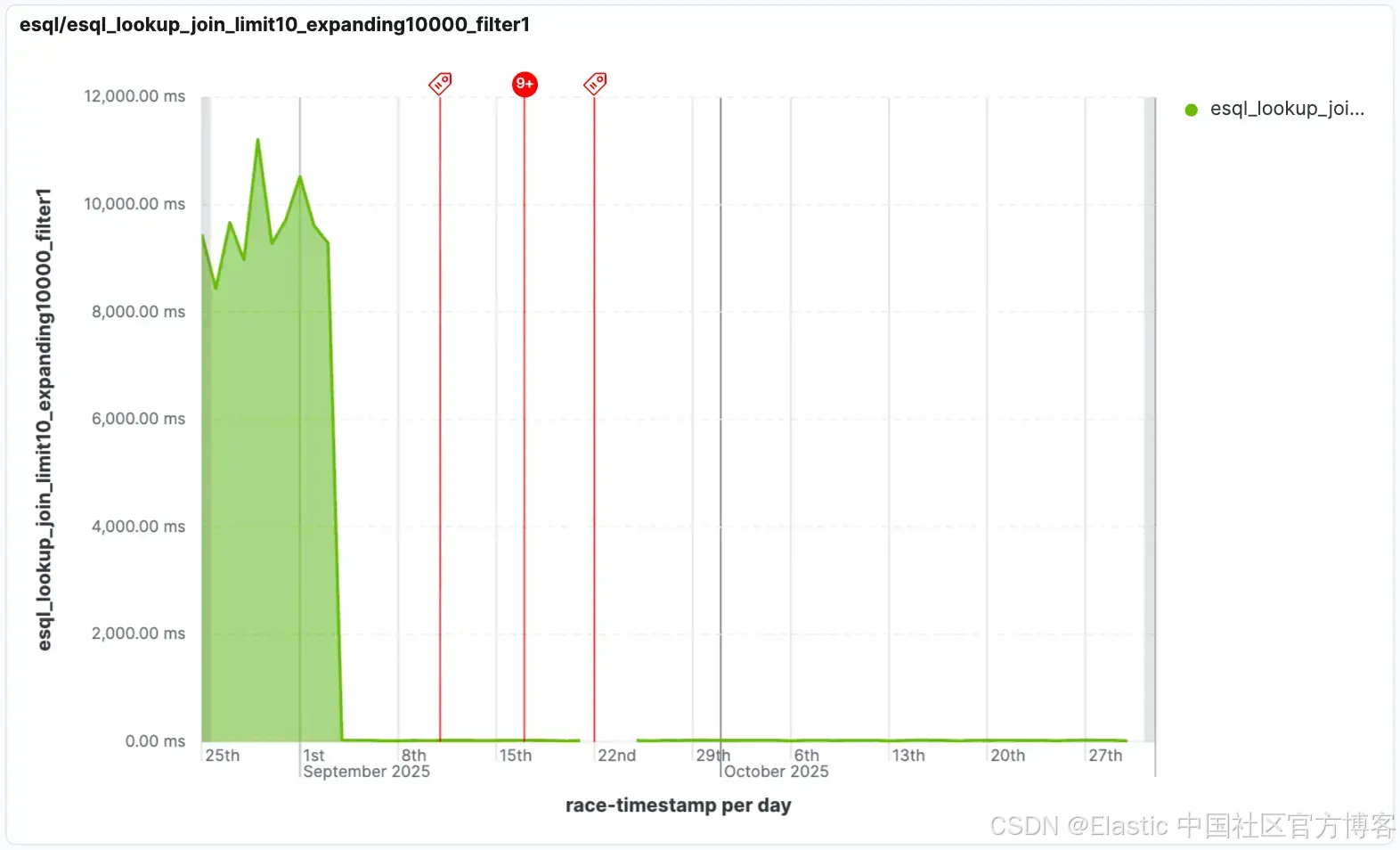
当处理 “扩展连接” 时,这种优化至关重要,因为 lookup 可能最初会生成许多潜在匹配。通过智能下推过滤器,仅处理相关数据,大幅减少查询执行时间,并支持对海量数据进行实时分析。这意味着即使在非常大或复杂的连接操作中,你也能更快获得洞察。
Lookup Join 跨集群搜索(CCS)兼容性:
在 8.19 和 9.1 中,Lookup Join 推出 GA 时不支持跨集群搜索(CCS)。对于在多个集群上运行的组织,LOOKUP JOIN 在 9.2 中现在可以无缝集成 CCS。只需将你的 lookup 索引放在所有希望执行连接的远程集群上,ES | QL 会自动利用这些远程 lookup 索引与远程数据进行连接。这简化了分布式数据分析,并确保在整个 Elasticsearch 部署中实现一致的数据丰富。
这些改进意味着你可以以前所未有的精度、速度和便捷性关联多样化数据集,发现更深层、更可操作的洞察,而无需复杂的变通方法或预处理步骤。
轻松丰富你的数据:Kibana Discover 对 Lookup 索引的用户体验
数据丰富应该简单,而不是障碍。我们在 Kibana 的 Discover 中引入了一个出色的新用户体验,用于创建和管理 lookup 索引。
直观的工作流程:Discover 的完整自动补全会引导你完成整个过程,在 ES | QL 编辑器中建议 lookup 索引和连接字段,让你轻松将上传的数据与现有索引连接。输入不存在的 lookup 索引名称,只需点击一次即可直接进入 Lookup 编辑器创建索引。输入已有 lookup 索引名称,我们会建议编辑选项:

行内管理(CRUD):在 Discover 中直接使用行内编辑功能(创建、读取、更新、删除),保持你的参考数据集最新。
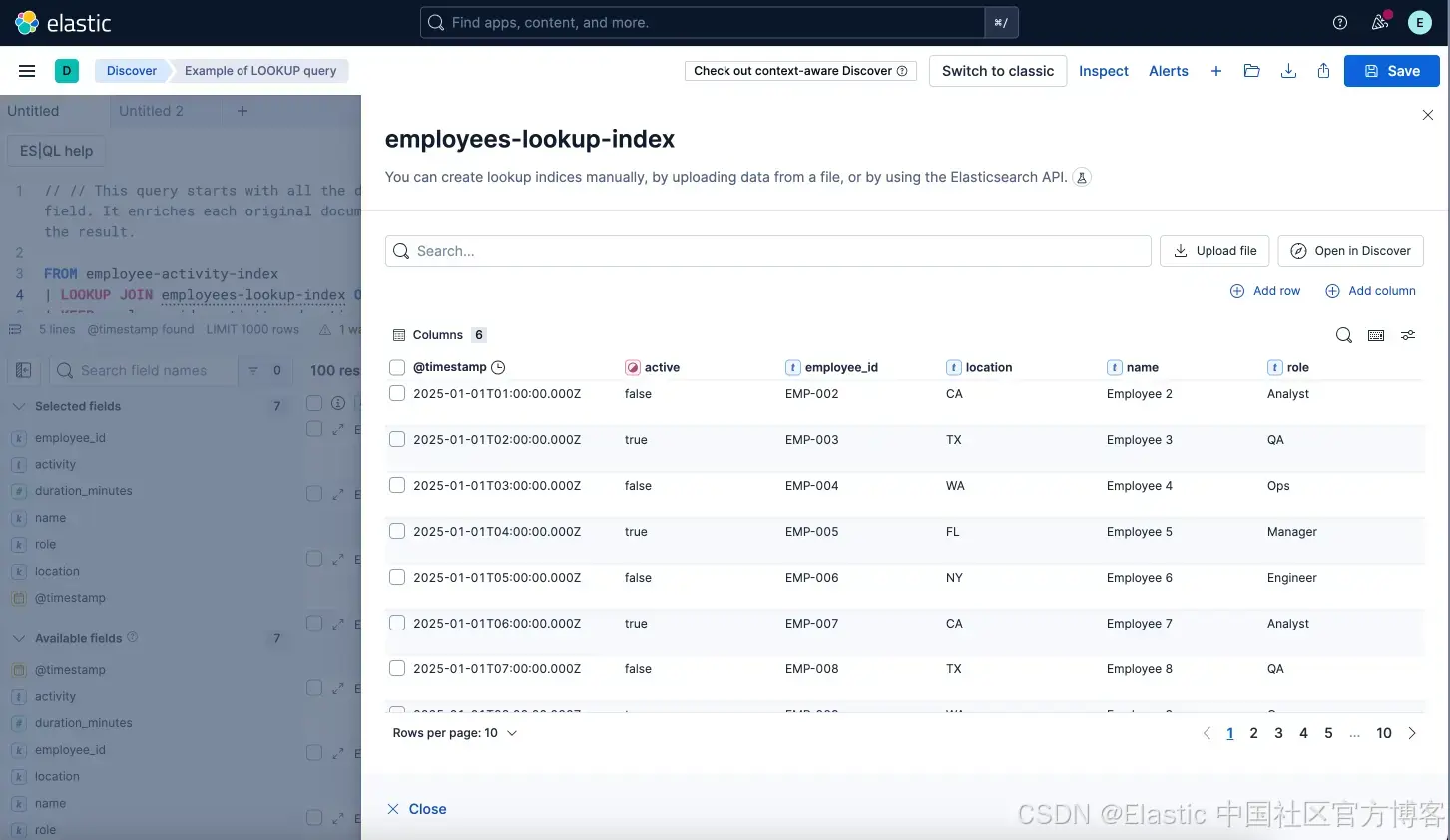
轻松文件上传:现在你可以在 Discover 中直接上传文件,例如 CSV,并立即在你的 LOOKUP JOIN 中使用。无需再在 Kibana 的不同区域来回切换上下文!
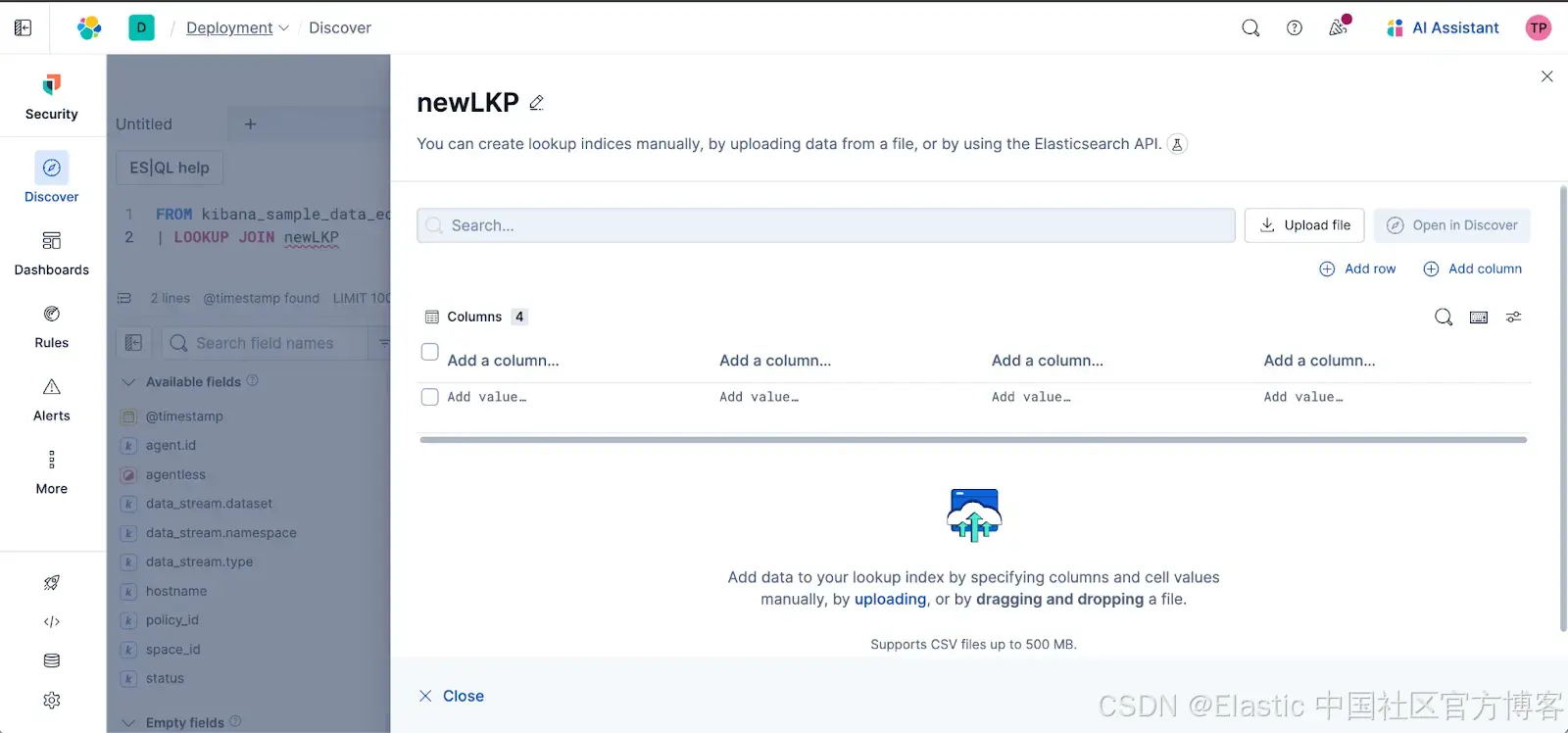
无论你是在将用户 ID 映射到名称、添加业务元数据,还是连接静态参考文件,这个功能都让数据丰富更加普及,将连接的能力直接交到每个用户手中 —— 快速、简单、集中操作。
保留你的上下文:推出 INLINE STATS(技术预览)
聚合数据很重要,但有时你需要同时查看聚合结果和原始数据。我们很高兴将 INLINE STATS 作为技术预览功能推出。
与会用聚合输出替换输入字段的 STATS 命令不同,INLINE STATS 保留所有原始输入字段,只是添加新的聚合字段。这使你在聚合后可以对原始输入字段执行进一步操作,提供更连续、更灵活的分析工作流。
例如,在保留单个航班行的同时计算平均航程:
FROM kibana_sample_data_flights
| KEEP Carrier, Dest, DistanceMiles
| INLINE STATS avgDist = ROUND(AVG(DistanceMiles))
BY Dest
| WHERE DistanceMiles > avgDist
在此查询中,avgDist 被添加到每一行对应的 Dest(目的地)分组中,然后,因为我们仍保留航班信息列,所以可以筛选出距离大于平均值的航班。
ES|QL 中的时间序列支持(技术预览)
Elasticsearch 使用时间序列数据流来存储指标。我们通过 TS source 命令为 ES|QL 添加了时间序列聚合支持。这在 Elastic Cloud serverless 和 9.2 basic 中作为技术预览提供。
时间序列分析主要基于聚合查询,通过时间桶汇总指标值,并按一个或多个过滤维度切分。大多数聚合查询依赖两步处理,(a) 内部聚合函数按时间序列汇总数值,(b) 外部聚合函数将 (a) 的结果跨时间序列组合。
TS source 命令结合 STATS 提供了一种简洁而有效的方式来表达时间序列查询。更具体地,考虑以下示例,用于计算每个主机每小时的请求总率:
TS my_metrics
| WHERE @timestamp > NOW() - 1 day
| STATS SUM(RATE(requests))
BY host, TBUCKET(1h)在这种情况下,时间序列聚合函数 RATE 首先按时间序列和小时进行评估。生成的部分聚合结果随后使用 SUM 组合,以计算每个主机每小时的最终聚合值。
你可以在这里查看可用的时间序列聚合函数列表。counter rate 现在得到支持,这可以说是处理计数器时最重要的聚合函数。
TS source 命令设计为与 STATS 结合使用,其执行经过优化以高效支持时间序列聚合。例如,数据在进入 STATS 之前会先进行排序。可能丰富或更改时间序列数据或其顺序的处理命令,如 FORK 或 INLINE STATS,目前不允许在 TS 和 STATS 之间使用。此限制未来可能会取消。
STATS 的表格输出可以进一步使用任何适用命令处理。例如,以下查询计算每个主机每小时的平均 cpu_usage 与每个主机最大值的比率:
TS my_metrics
| STATS avg_usage = AVG(AVG_OVER_TIME(cpu_usage))
BY host, time_bucket = TBUCKET(1h)
| INLINE STATS max_avg_usage = MAX(avg_usage)
BY host
| EVAL ratio = avg_usage / max_avg_usage
| KEEP host, time_bucket, ratio
| SORT host, time_bucket DESC时间序列数据存储在我们基于 Lucene doc values 的底层列式存储引擎上。TS 命令通过 ES|QL 计算引擎增加了向量化查询执行。与等效的 DSL 查询相比,查询性能通常提高一个数量级以上,且与成熟的指标专用系统相当。我们将在未来提供详细的架构和性能分析,敬请关注。
扩展你的工具箱:新的 ES|QL 函数
为了进一步增强 ES | QL 的实用性和多功能性,我们增加了一套新函数:
字符串处理:CONTAINS、MV_CONTAINS、URL_ENCODE、URL_ENCODE_COMPONENT、URL_DECODE,用于更强大的文本和 URL 处理。
时间序列与地理空间:TBUCKET 用于灵活的时间分桶,TO_DENSE_VECTOR 用于向量操作,以及一整套地理空间函数,如 ST_GEOHASH、ST_GEOTILE、ST_GEOHEX、TO_GEOHASH、TO_GEOTILE、TO_GEOHEX,用于高级基于位置的分析。
日期格式化:DAY_NAME、MONTH_NAME,用于更易读的日期表示。
这些函数为你提供了更丰富的工具集,可在 ES | QL 中直接操作和分析数据。
底层优化:更多性能和效率
除了突出功能之外,Elasticsearch 9.2 在 ES|QL 中还包含了大量性能优化。我们通过下推优化加速了 RLIKE (LIST),在函数替换多个相似 RLIKE 查询的情况下可将这些查询合并为单个自动机,并应用一个自动机而非多个。我们还加快了带索引排序的 keyword 字段加载,以及一般查询优化——这些改进确保你的 ES | QL 查询比以往更高效。
立即开始体验!
Elasticsearch 9.2 对 ES | QL 是一次重大飞跃,为你的数据分析工作流带来前所未有的强大和灵活性。我们鼓励你探索这些新功能,体验它们带来的不同。
有关 Elasticsearch 9.2 中所有更改和增强的完整列表,请查阅官方发行说明。祝查询愉快!
原文:https://www.elastic.co/search-labs/blog/esql-elasticsearch-9-2-multi-field-joins-ts-command


















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









